-
-
give task or goal to perfrom
-
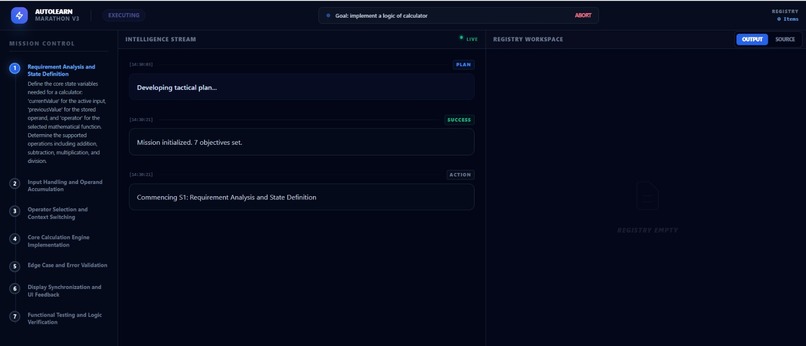
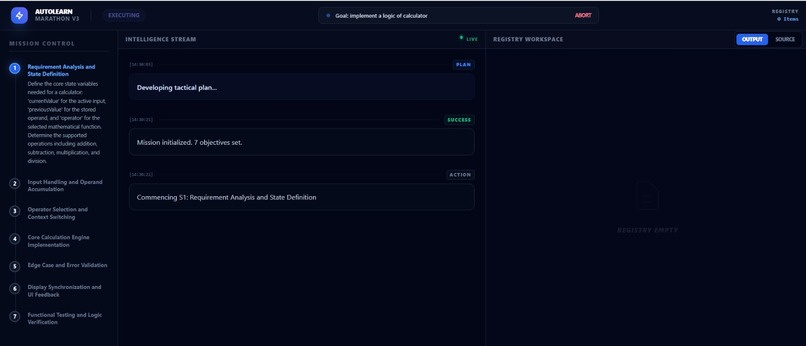
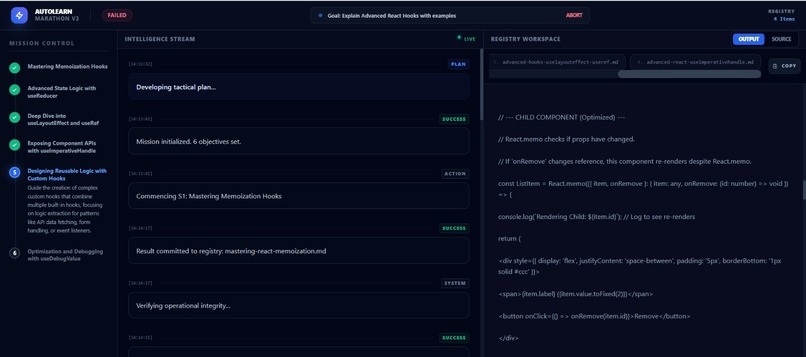
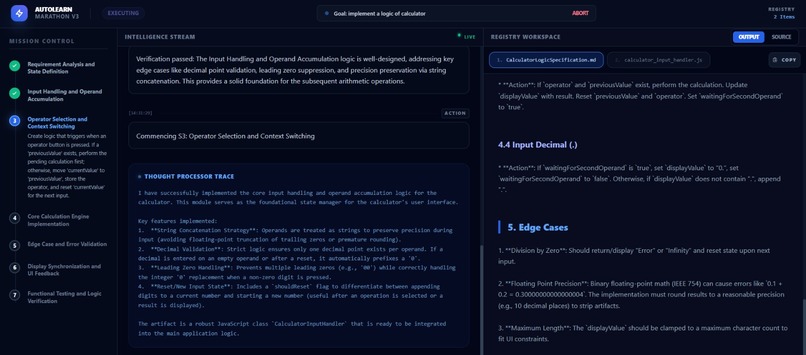
planning
-
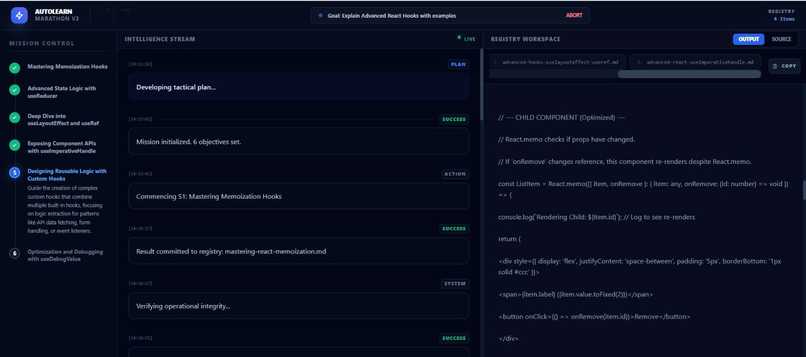
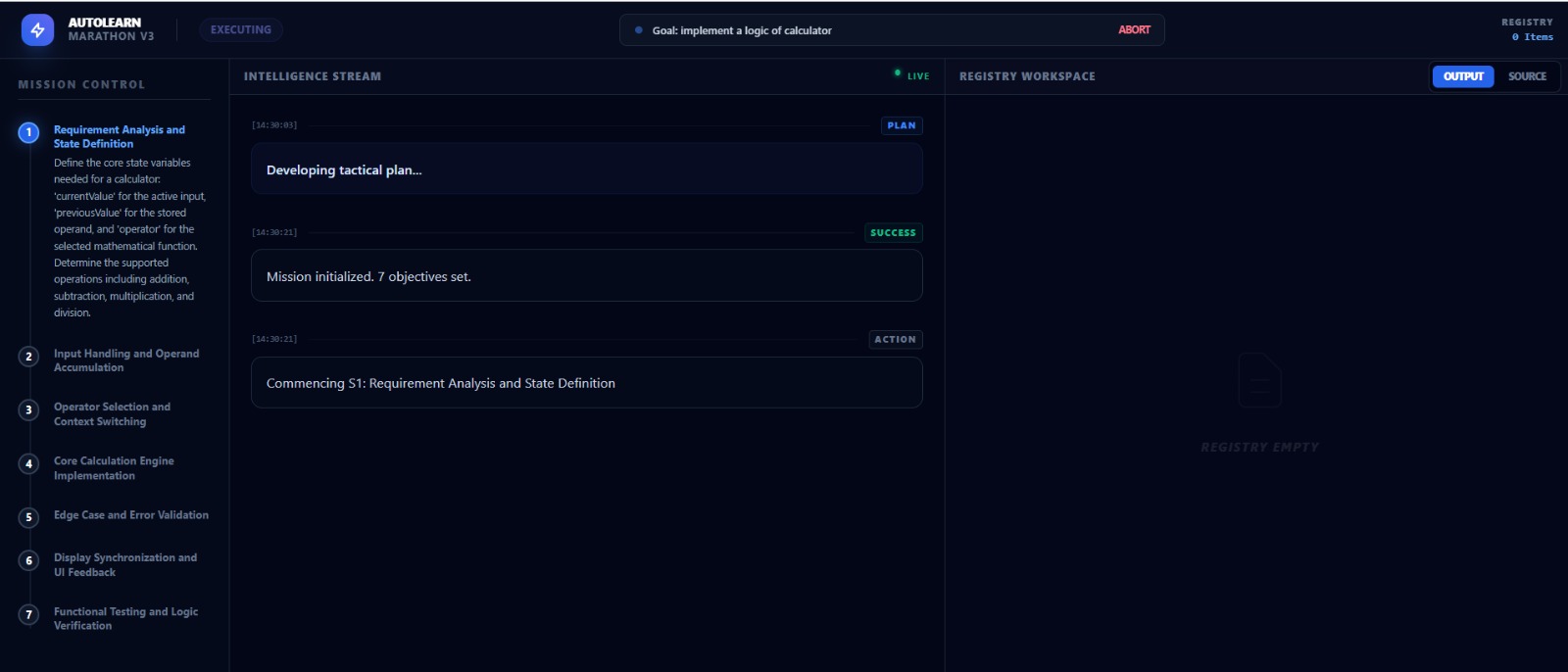
execution
-
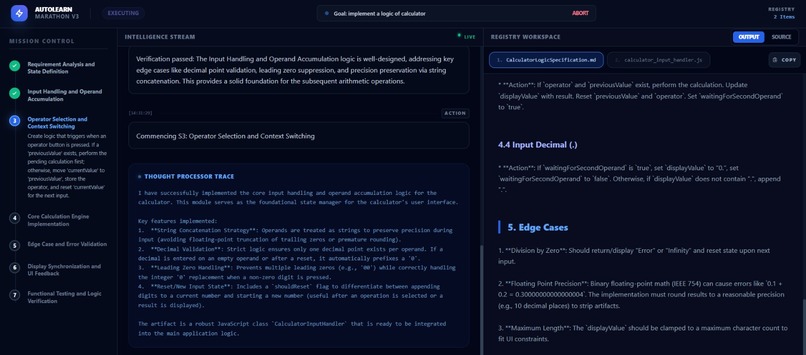
executing step by step
-
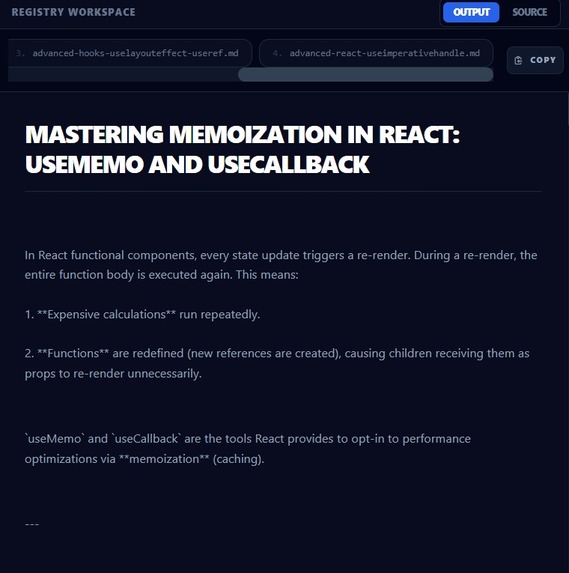
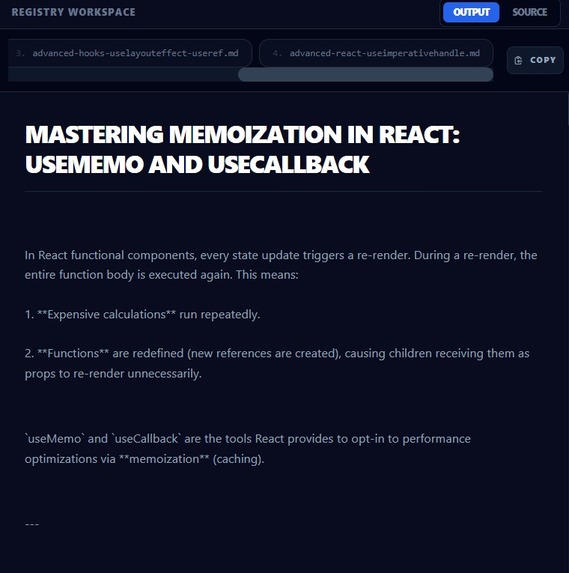
Output
-
-
-
-
-
-
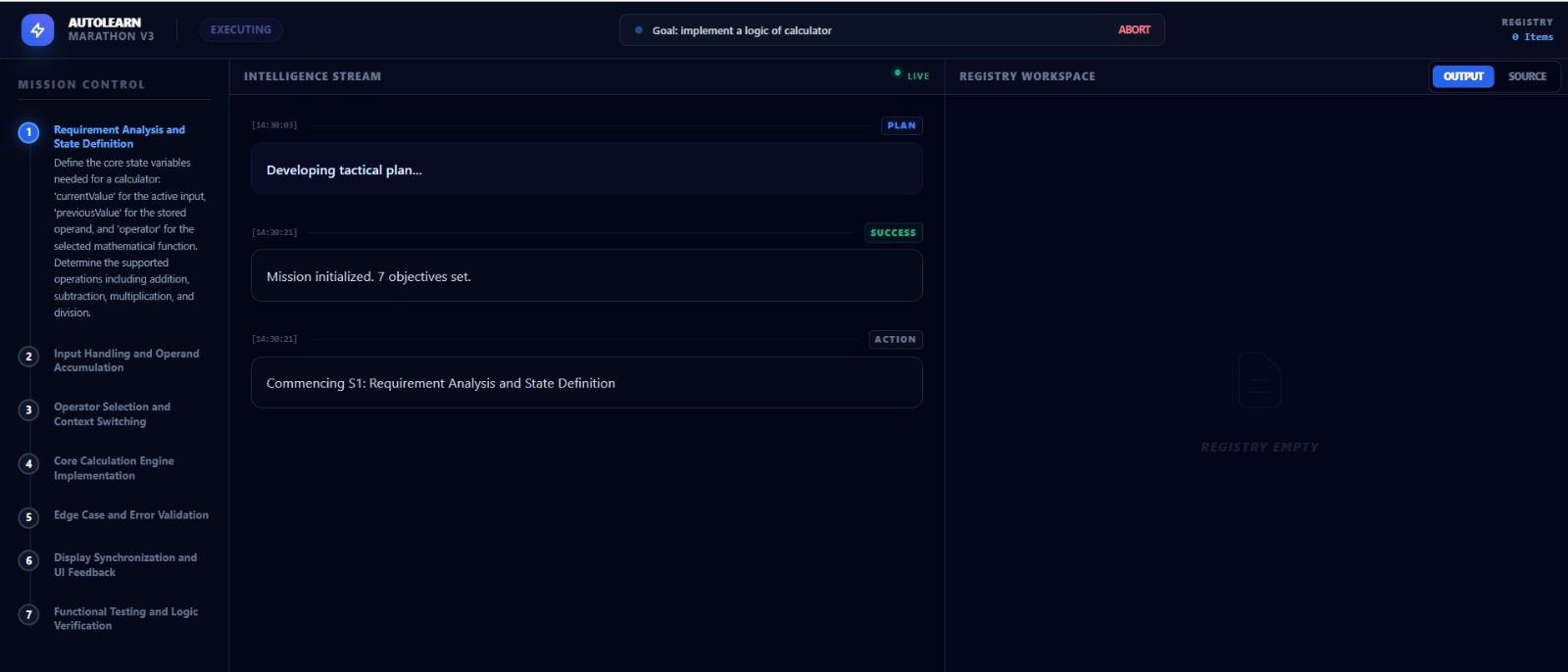
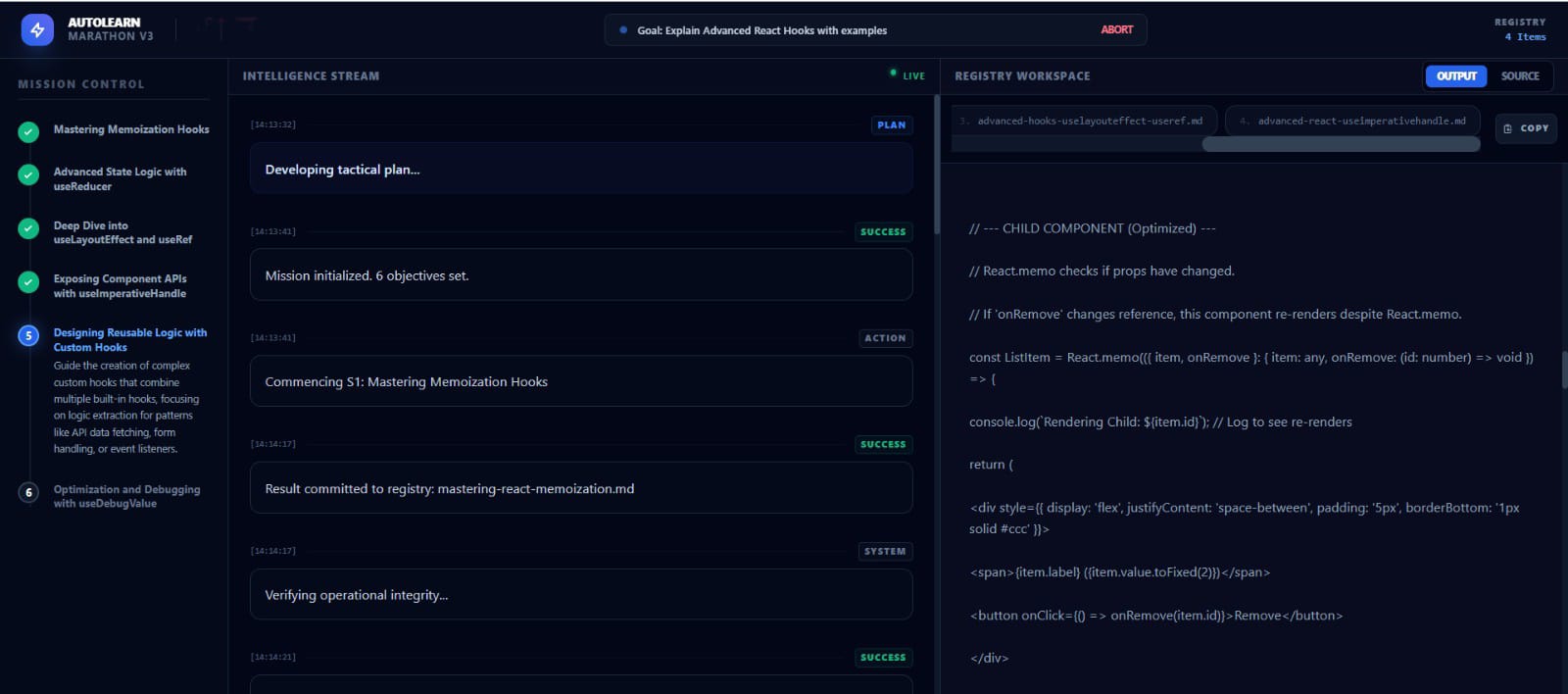
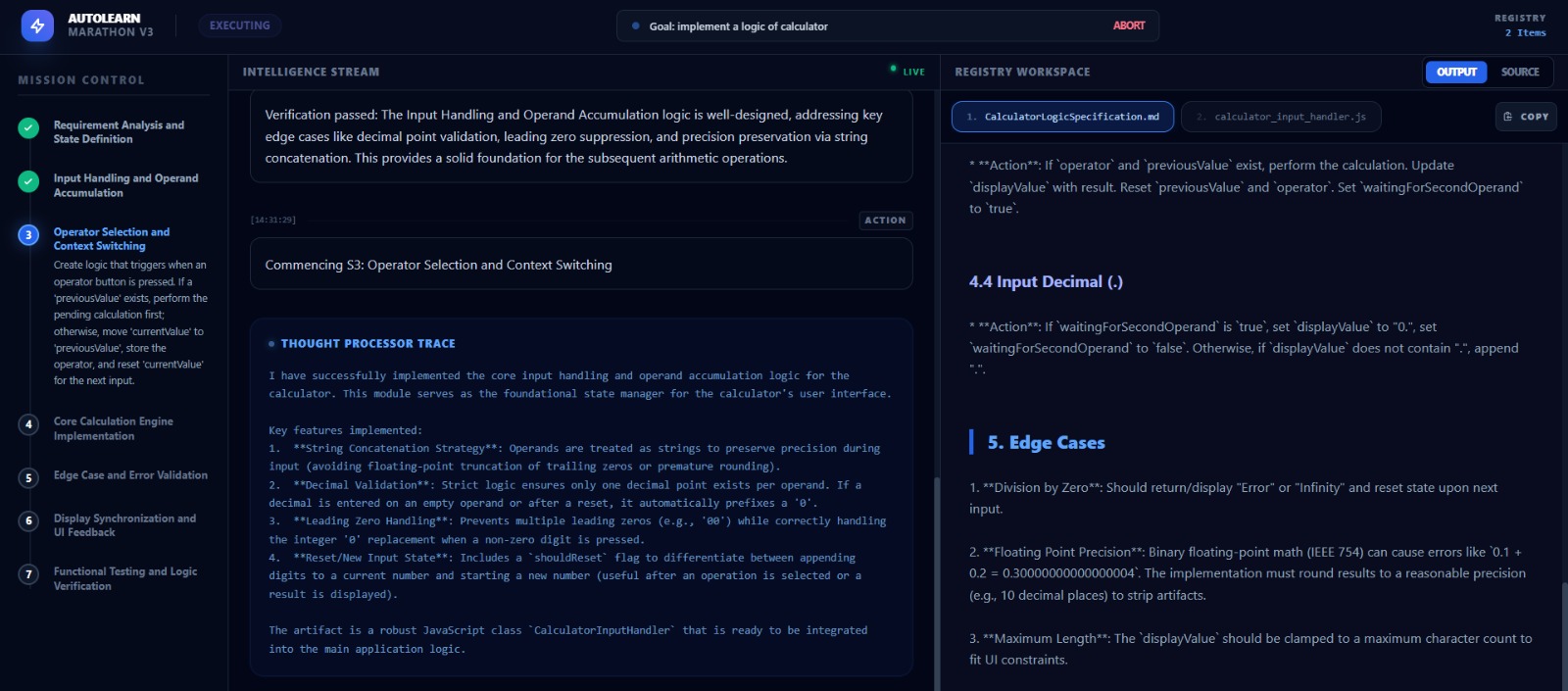
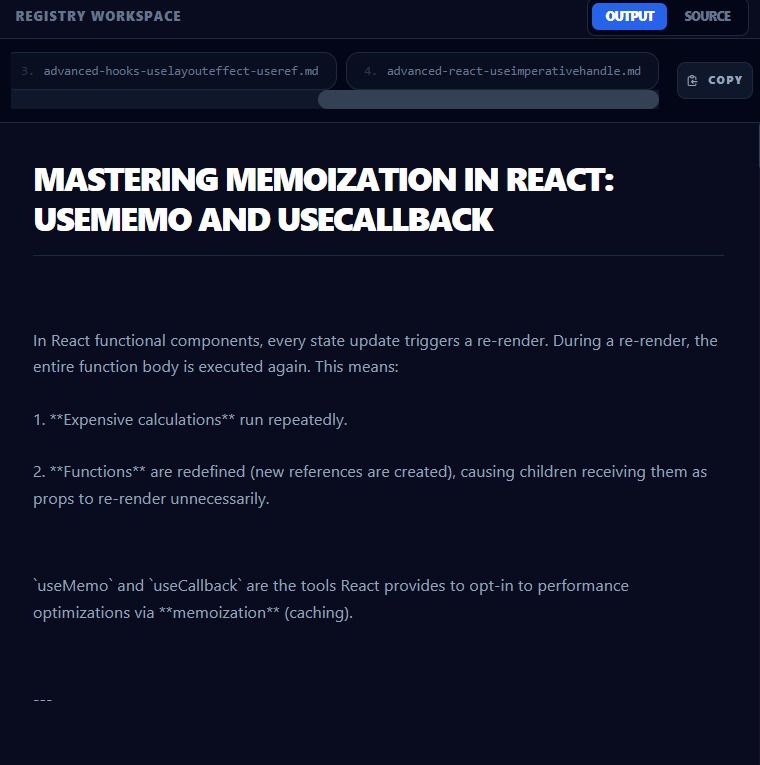
Inspiration
We are entering the "Action Era" of AI. For the past year, we’ve all used chatbots that are brilliant at answering questions but terrible at doing things. If you ask an AI to "build a website," it gives you code snippets, but you have to copy-paste them, run them, fix the errors, and paste the errors back. It’s a ping-pong match.
We asked ourselves: What if we could give an AI a goal, walk away for 12 hours, and come back to a finished project?
That inspired AutoLearn Marathon Agent autonomous system designed not just to chat, but to work, fail, learn, and fix itself in a continuous loop until the job is done.
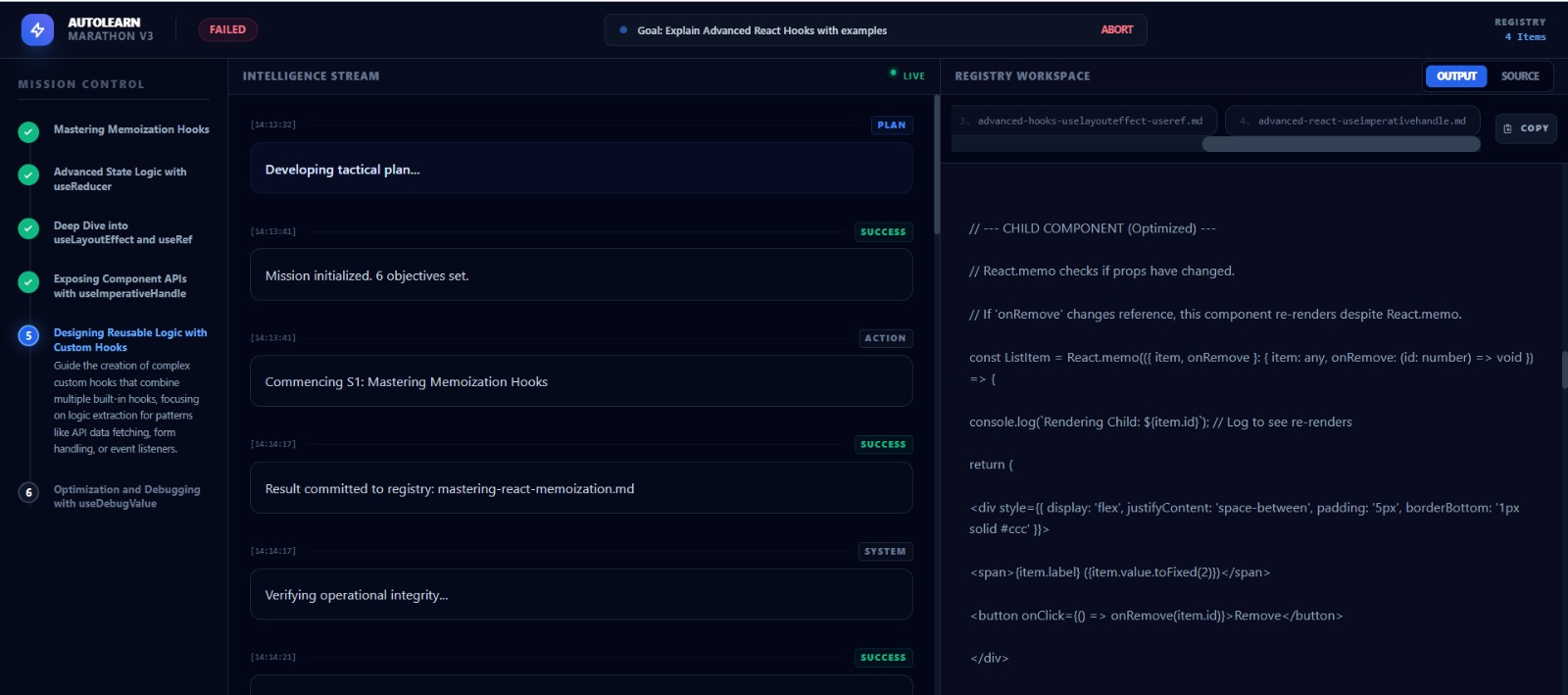
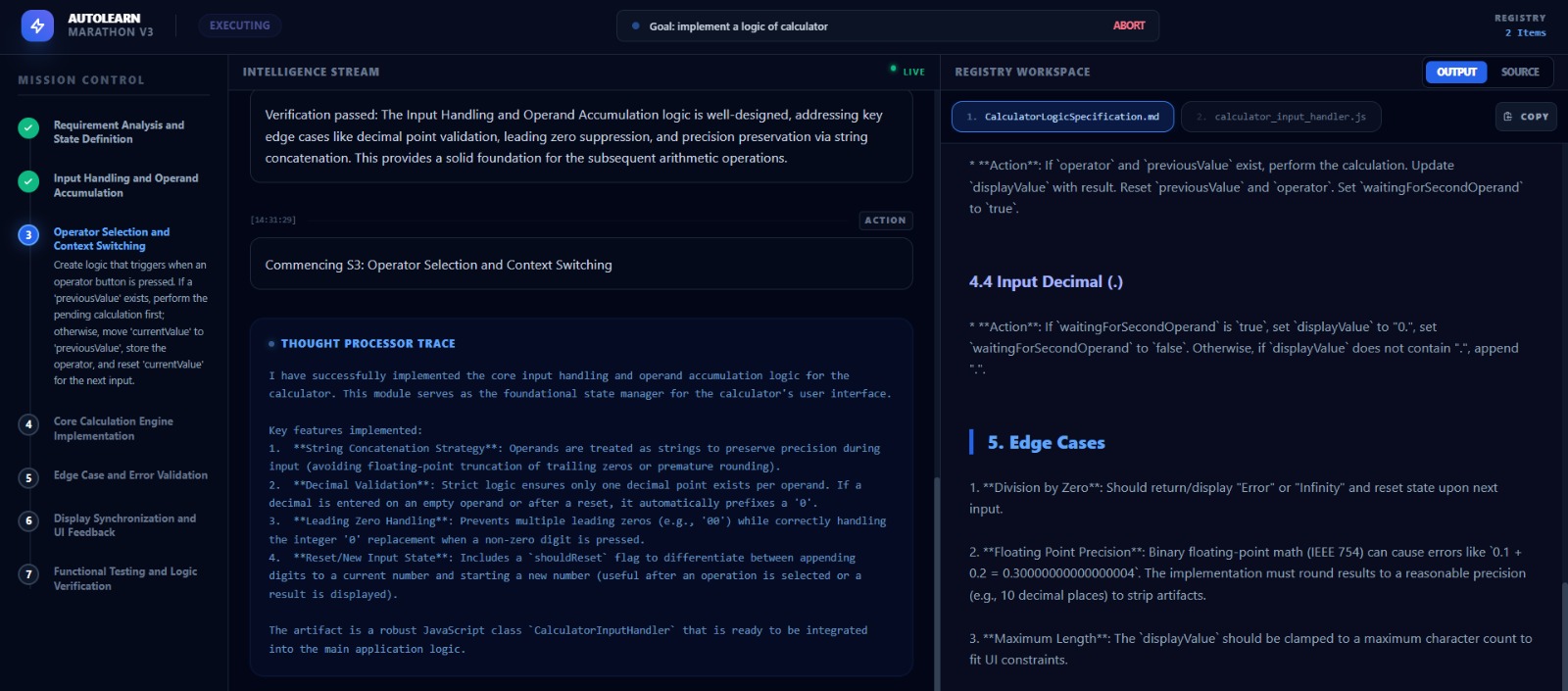
What it does
AutoLearn is an autonomous agent framework that accepts a high-level long-term goal (e.g., "Learn Git and create a repo" or "Build a Snake game in Python") and executes it without human intervention.
Unlike a standard chatbot, it:
- Plans: Breaks the goal into a sequence of logical steps.
- Acts: Uses actual tools (Terminal, File System) to write code and execute commands.
- Self-Corrects: If a command fails (e.g.,
ModuleNotFoundError), it reads the error log, researches a solution, installs the missing package, and tries again. - Persists: It operates in a "Marathon" loop, maintaining context over long execution cycles that would typically hit token limits in standard chats.
How we built it
We built the system using a "Brain-Body" architecture powered by Gemini 3.
The Brain (Gemini 3): We used Google's Gemini 3 model via AI Studio. Its massive context window allows it to remember the entire history of its "marathon," ensuring it doesn't repeat mistakes it made 100 turns ago. The Body (Python & FastAPI): We built a lightweight backend using FastAPI and WebSockets. This layer handles the "Tool Use"—giving Gemini the ability to execute shell commands and write to files safely. The Interface (Vibe Coding): instead of complex React apps, we built a raw "Hacker Terminal" interface using HTML/JS that streams the agent's "thoughts" live via WebSockets.
We implemented a modified OODA Loop (Observe, Orient, Decide, Act) for the agent's logic. Mathematically, we modeled the decision process as maximizing the probability of success given the current state and history :
Where the history includes all previous errors and successful commands, allowing the agent to "learn" dynamically.
Challenges we ran into
The "Infinite Loop" Trap: Early versions of the agent would get stuck trying the same failed command (e.g., pip install) over and over. We had to implement a "Frustration Metric" where the agent detects repetitive failures and forces a strategy change (e.g., "Try a different library").
Safety vs. Autonomy: Giving an AI access to a terminal is dangerous. We had to build a "Sandbox" layer that strictly forbids commands like rm -rf / or accessing files outside the workspace.
Hallucinated Files: Sometimes the agent would try to run a file it thought it created but hadn't. We added a "Reality Check" step where the agent must verify a file exists (ls) before trying to run it.
Accomplishments that we're proud of
True Autonomy: We successfully watched the agent encounter a ModuleNotFoundError, pause, run pip install, and then successfully run the script—all without us touching the keyboard.
Vibe Coding Success: We built the core logic using natural language "System Instructions" rather than thousands of lines of rigid code.
Live Visualization: The WebSocket dashboard that shows the agent's "Thought Process" (e.g., "THOUGHT: That didn't work. I need to check the documentation...") makes the AI feel incredibly alive.
What we learned
Prompt Engineering is Logic Engineering: Writing the System Instruction was harder than writing the Python code. We learned that you have to treat English prompts like code—modular, testable, and strict. Gemini 3's Reasoning is Real: The model's ability to look at a complex error stack trace and pinpoint the exact missing dependency was superior to many junior developers. Agents need "Sleep": We realized that for very long tasks, the context window fills up. We learned techniques to "summarize" memory so the agent can keep working indefinitely.
What's next for AutoLearn Marathon Agent
Docker Containerization: Currently, the agent runs locally. We plan to move the execution environment into isolated Docker containers for 100% safety. Multi-Agent Swarm: Instead of one agent doing everything, we want to spawn a "Team"—one agent to write code, one to write tests, and one to review security. Voice Interruption: Using Gemini Live capabilities to let the human "manager" verbally interrupt the agent to change the plan mid-marathon.
Built With
- artifactregistrypattern
- browserlocalstorage
- geminiapi
- react
- tailwindcss
- typescript
- zero-buildarchitecture

Log in or sign up for Devpost to join the conversation.