-
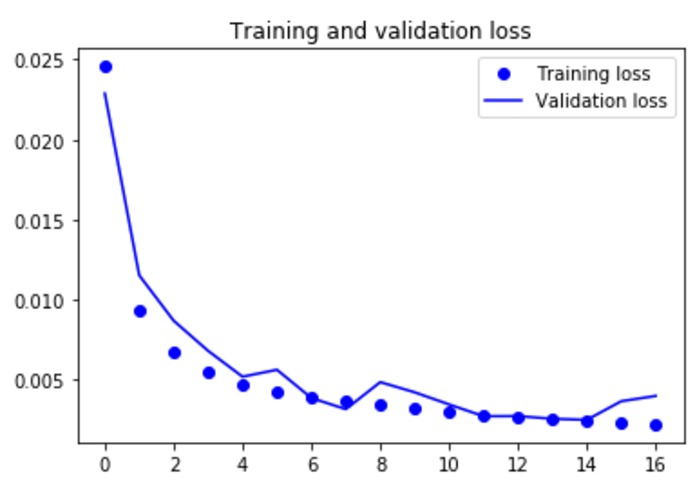
Training and Validation Loss over Epochs
Inspiration
Having worked in the field of Machine Learning for some time, we realized that labeled data was hard and expensive. In order to overcome this problem, we started searching for ideas that would help optimize the data that we can retrieve. This is when we came across AutoEncoders and implemented that into a simple classifier model to work with whatever data we have.
What it does
The Model takes fewer labeled data (100) and is able to train at a relatively higher speed resulting in an overall accuracy of around 65%
How we built it
The encoder part of the autoencoder has 8 convolution layers along with MaxPooloing in between. The decoder has 4 convolution layers along with UpSampling in between. We train this model and replace the decoder part with a simple classifier model, which classifies the input images into the respective categories.
Challenges we ran into
The Autoencoder was extremely power-dependent and training required a substantial amount of GPU processing power.
Accomplishments that we're proud of
Using the whole dataset we were able to achieve around 90% accuracy and using just 100 labeled data we got around 65% accuracy.
What's next for AutoEncoder for Fashion-MNIST
We want to improve our AutoEncoder to tackle more critical tasks like Object Detection and Segmentation

Log in or sign up for Devpost to join the conversation.