Inspiration
Every day, teams waste hours manually extracting data from PDFs, spreadsheets, and reports. In traditional industries, much of this still happens on paper or static documents, creating friction between information and action. We wanted to build something that bridges that gap — an AI agent system that can read, understand, and transform documents just like a human, but faster and more reliably.
What it does
AutoDoc is an AI-powered document ETL (Extract, Transform, Load) platform built entirely on AWS. It enables users to upload any document (PDF, image, Word, Excel) or even ask natural language questions — and have the system extract, validate, and store structured information automatically.
At its core, AutoDoc Agent orchestrates multiple AI-powered subtasks — file loading, text extraction, metadata recognition, validation, and database storage — through a unified agentic runtime. This creates a seamless, end-to-end document pipeline that runs with minimal human intervention.
How we built it
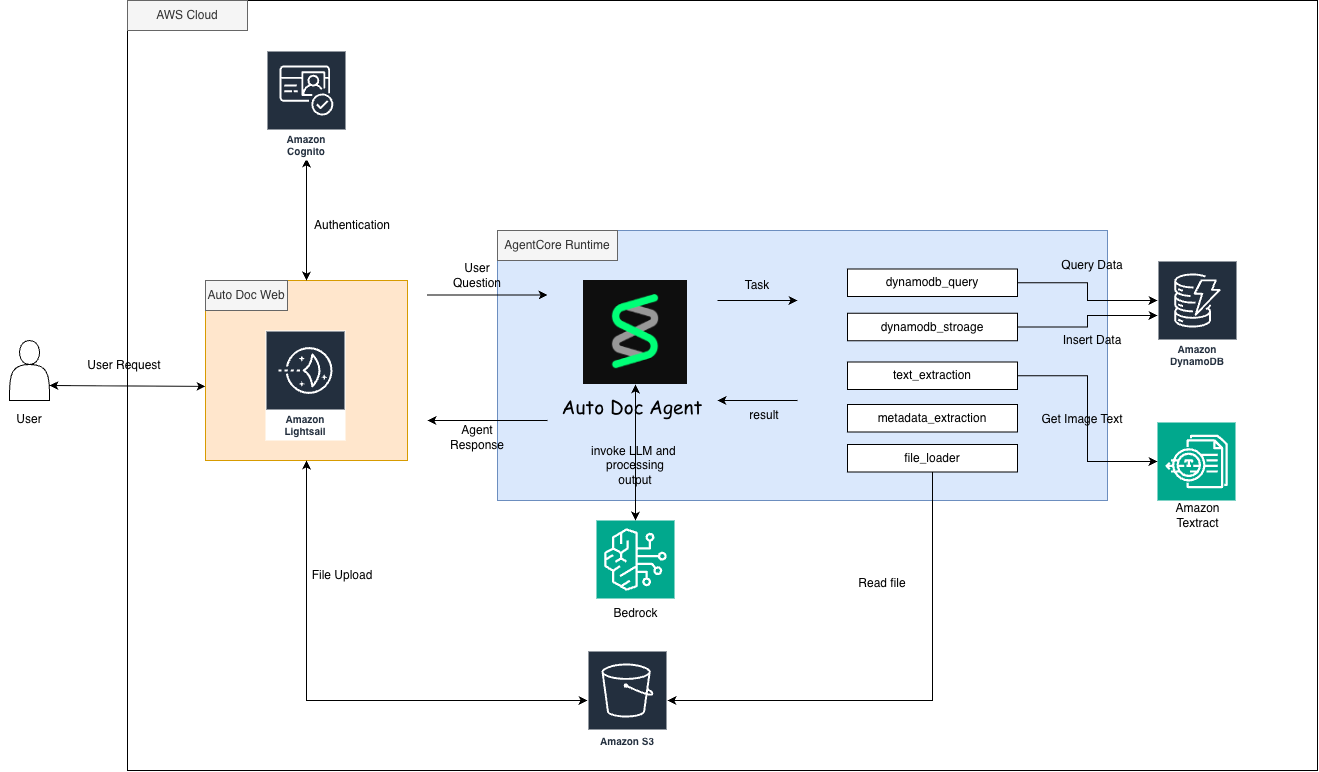
The system is composed of three main layers:
🟠 1. Frontend Layer — AutoDoc Web
- Hosted on Amazon Lightsail
- Handles user interactions, file uploads, and queries
- Secured with Amazon Cognito for authentication and access control
🔵 2. AgentCore Runtime — AutoDoc Agent The intelligent core that coordinates all tasks Invokes AWS Bedrock for LLM reasoning, semantic parsing, and response generation Implements specialized modules:
- file_loader — reads and parses uploaded documents
- text_extraction — uses Amazon Textract for OCR and table detection
- metadata_extraction — identifies key entities (dates, totals, names, etc.)
- dynamodb_storage / dynamodb_query — writes and retrieves structured data from Amazon DynamoDB
🟢 3. Data & AI Services
- Amazon S3 — stores uploaded and processed files
- Amazon Textract — extracts text and structure from image or PDF files
- Amazon DynamoDB — serves as the structured database for processed outputs All components communicate through event-driven flows using AgentCore Runtime, enabling modular, scalable orchestration.
Challenges we ran into
- Integrating multiple AWS services while maintaining stateless communication between the frontend and the agent runtime was challenging.
- We also had to optimize OCR + LLM fusion, where Textract’s raw output feeds into the Bedrock LLM for contextual interpretation.
- Ensuring data integrity and cost-efficient LLM invocation were key engineering problems we solved through caching and validation strategies. ## What we learned
- We learned how to design agentic architectures that combine AWS’s reliability with LLM flexibility.
- Building AutoDoc taught us to think of documents not just as static files, but as dynamic data flows that can evolve through automation.
- We also gained experience balancing serverless design, data accuracy, and AI reasoning performance within real-world constraints. ## What's next for AutoDoc We plan to enhance AutoDoc with:
- Domain-specific templates for finance, legal, HR, and logistics use cases
- Multi-channel Agent triggers — enabling document processing to start automatically from various sources such as email attachments, shared folders, API calls, or chatbots Our vision is to make AutoDoc the universal document agent, capable of connecting to any information source and transforming messy files into clean, actionable intelligence — automatically.
Built With
- agentcore
- bedrock
- python


Log in or sign up for Devpost to join the conversation.