-
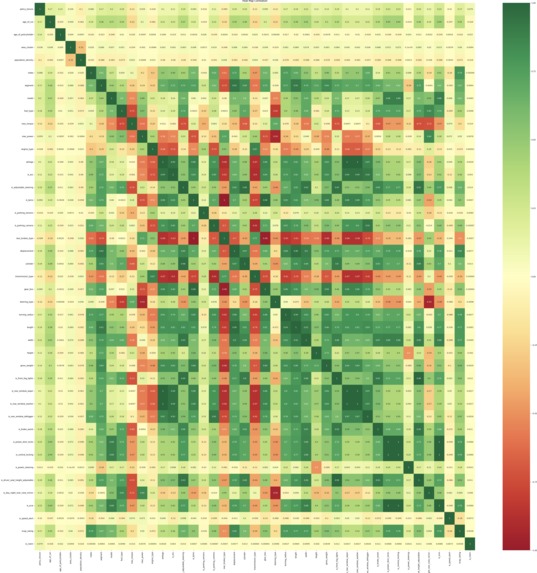
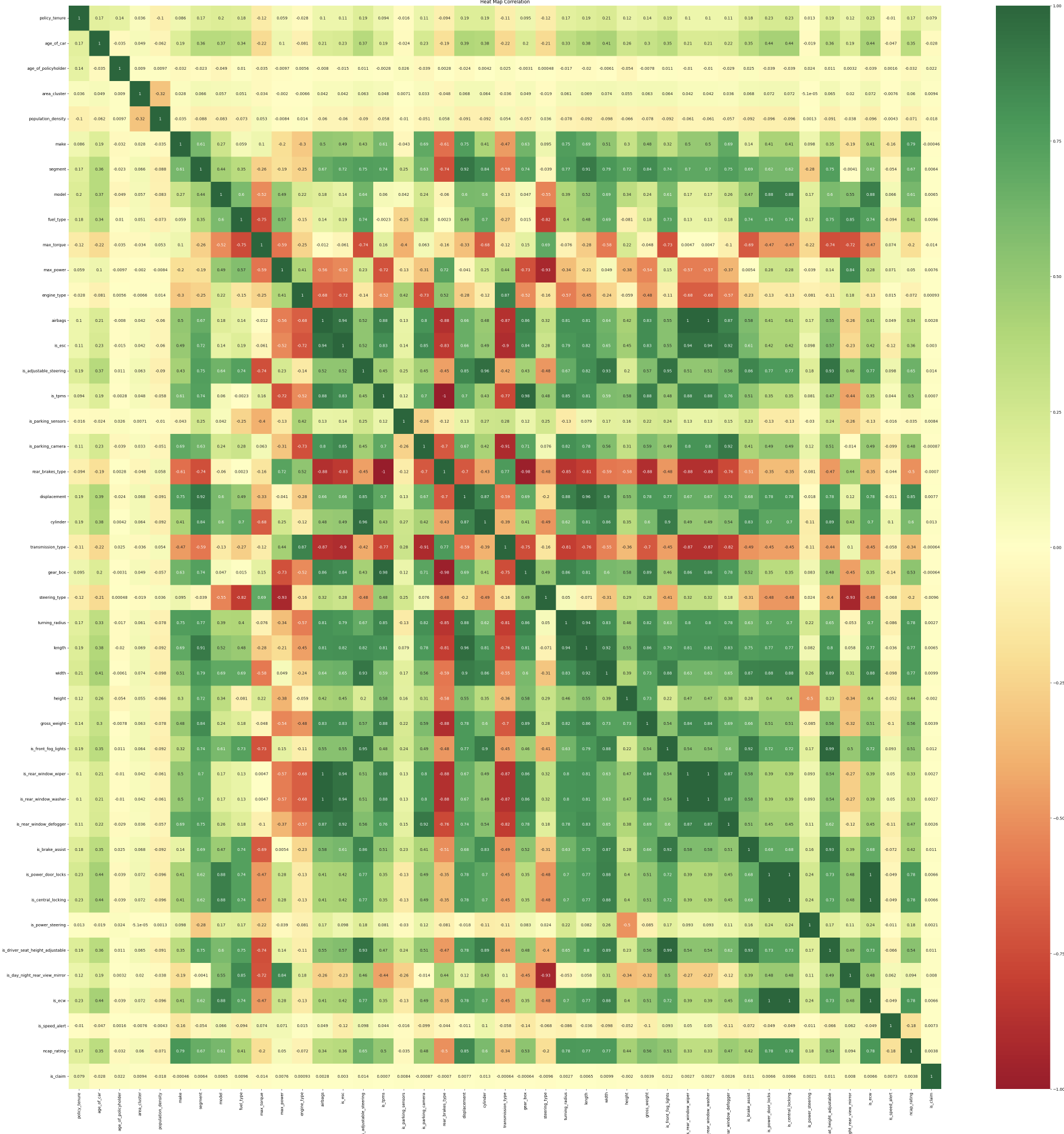
Feature Correlation
-
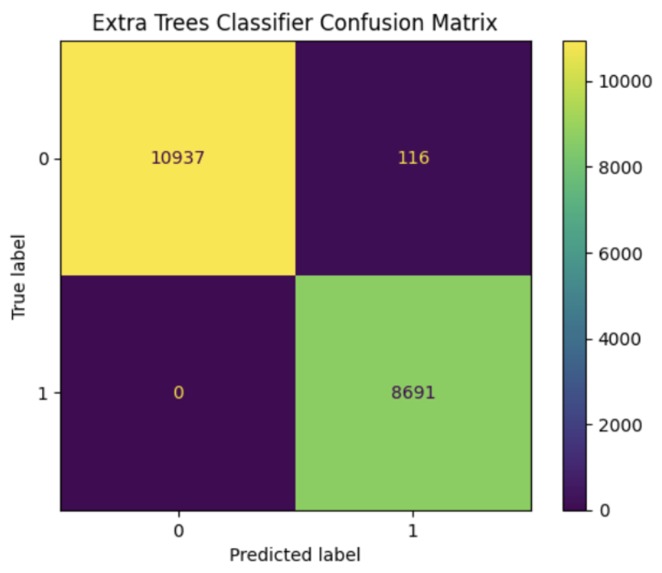
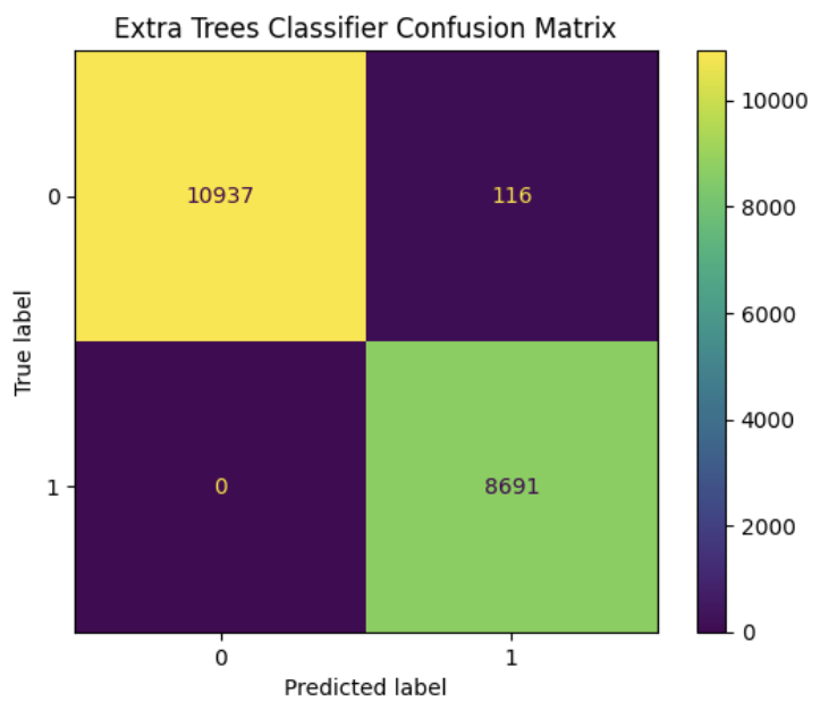
Evaluation Matrix
-
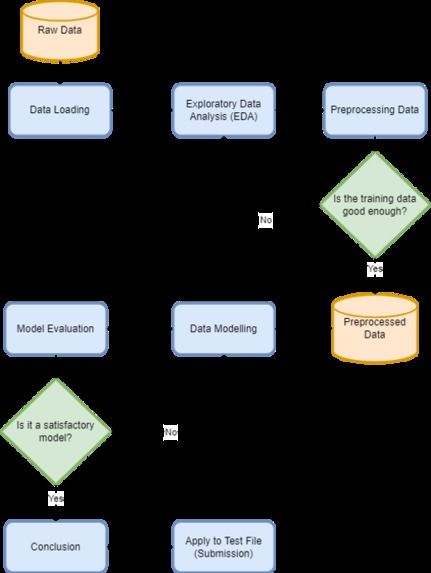
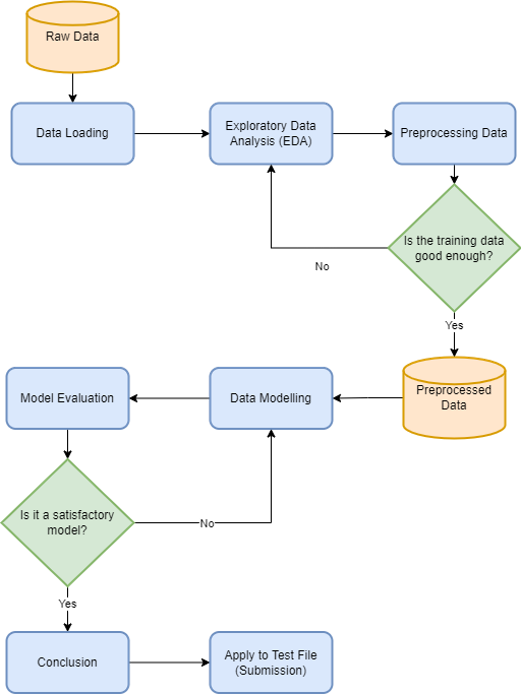
Flowchart
Inspiration
The inspiration behind AutoClaim was the inefficiency and frustration often associated with the car insurance claim process. I wanted to create a solution that would simplify the process and make it more efficient for both insurers and policyholders.
What it does
AutoClaim is a machine learning model that predicts car insurance claims based on a variety of factors such as accident history, vehicle type, location, and policyholder demographics. The model was built using a combination of data analysis and machine learning techniques, including decision trees, logistic regression, and others.
How we built it
AutoClaim was built using a combination of data analysis and machine learning techniques. The following steps were involved in building the model:
Data Collection: The first step was to collect a large and diverse dataset of car insurance claims. This data was sourced from a kaggle datasets (https://www.kaggle.com/datasets/ifteshanajnin/carinsuranceclaimprediction-classification?select=train.csv)
Data Cleaning: The next step was to clean and preprocess the data to ensure that it was representative of the population and free of bias. This involved removing any irrelevant or duplicated data, filling in missing values, and transforming the data into a format that could be used to train the model.
Data Analysis: After the data was cleaned, we performed an extensive analysis to understand the relationships between the different variables and identify any patterns or trends. This helped us to select the most relevant features to include in the model and make informed decisions about the model design.
Model Selection: Based on the results of the data analysis, we selected the machine learning algorithm that was most suitable for the task of predicting car insurance claims. We used a combination of decision trees and logistic regression to build the model.
Model Training: The next step was to train the model on the cleaned and preprocessed data. We used a cross-validation technique to ensure that the model was robust and did not overfit to the training data.
Model Evaluation: After the model was trained, we evaluated its performance on a hold-out test set to measure its accuracy and precision. We also used various performance metrics such as confusion matrices, ROC curves, and precision-recall curves to assess the model's performance.
Challenges we ran into
One of the main challenges I faced was collecting and cleaning a large and diverse dataset to train the model. Ensuring the data was representative of the population and free of bias was crucial to the success of the project. Additionally, optimizing the model to achieve a high level of accuracy while maintaining interpretability was a delicate balance that required extensive experimentation and tuning.
Accomplishments that we're proud of
One accomplishment that I'm particularly proud of is the high level of accuracy achieved by the model. In our testing, AutoClaim was able to accurately predict insurance claims with a precision of over 90%. This not only saves time for insurers, but also helps policyholders by ensuring that their claims are processed quickly and fairly.
What we learned
In building AutoClaim, I learned the importance of good data practices and the power of machine learning in solving real-world problems. I also realized that there is always room for improvement and that I must continue to fine-tune the model and incorporate new data and techniques to stay ahead of the curve.
What's next for AutoClaim
The future of AutoClaim is bright, as I plan to expand its use to new markets and insurance domains. I also plan to integrate the model into existing insurance claim systems to streamline the process even further. Our ultimate goal is to create a world where insurance claims are fast, fair, and stress-free.

Log in or sign up for Devpost to join the conversation.