-
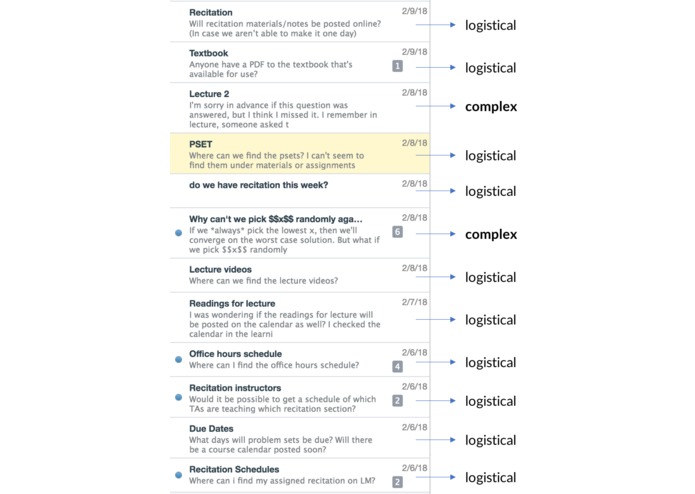
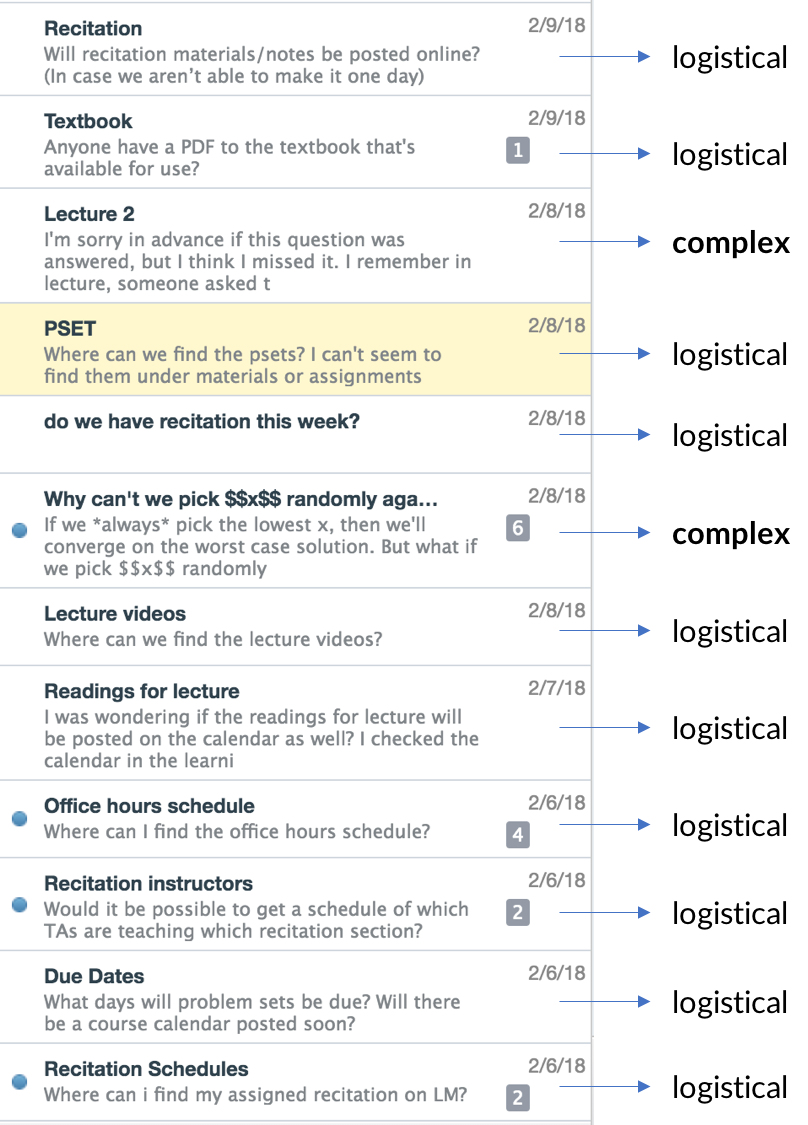
A screenshot of a forum, where the majority of questions (~83%) asked were logistical and could easily be answered by an AI agent
-
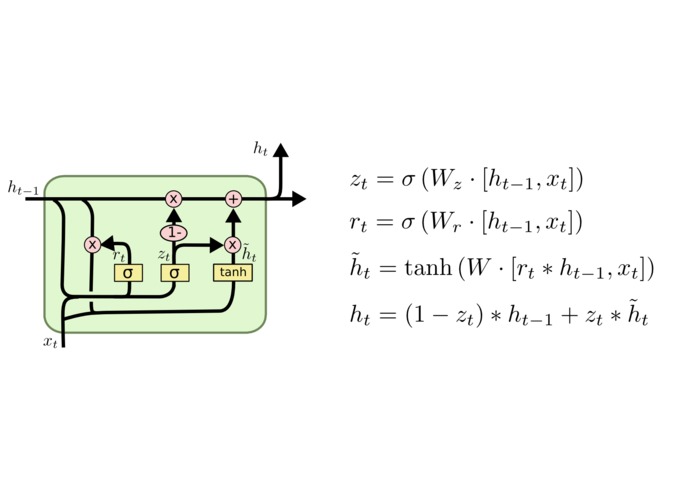
One unit of our multi-layer LSTM network

Inspiration
We are hunched over our computers, working on our algorithm problem set in our dimly lit dorm room. One problem eludes us, problem four, but we know that office hours will be too crowded. We look at the form that accompanies the class on Piazza, but most questions are unanswered.
This is the case with almost every class: redundant questions, especially simple logistical questions, mire these class discussion forums. More mundane tasks such as answering basic questions on class forums can be instead done by AI, saving time and energy.
What it does
AutoAnswer chatbot takes a dataset of already answered questions, and determines which of those questions are closest in meaning to a query question. For example, if one was interested in asking “What are the most populated countries in the world?” our system could pull up related questions such as “Which countries have the most people?” and “What are the top countries in the world by population?” that have already been answered.
How we built it
Our AI model is built using a Long-Short Term Memory deep learning network with an encoder architecture. Inspired by many recent papers in machine translation, siamese LSTM networks and auto-encoder style networks, we constructed our own novel model to specifically address the problem of question similarity.
For an input question, we first tokenize the text by splitting into words, lowercasing and removing punctuation. Next, we take each word and find its corresponding word embedding through the use of GloVe (Global Vectors for Word Representation). Then, we feed these embeddings into the LSTM network at each time step, ultimately receiving an output question-level embedding.
In order to train the model, we used the Quora Question Pairs dataset, where pairs of questions are given along with whether they are duplicates or not. To make use of this specific dataset, we fed pairs of questions through the multi-layer LSTM network and then through a fully connected layer to output a ‘0’ or a ‘1,’ depending on whether the pair of questions are duplicates or not.
We used many tools to develop our project, including Python, PyTorch (deep learning framework), IBM Cloud, Scikit Learn, NLTK (for natural language processing) and Pandas (data manipulation).
Challenges we ran into
To improve model performance, we hand-designed our loss function, architecture and input data pipeline. There were many hurdles along the way in terms of diagnosing architecture-level errors, overfitting and lack of training; it is all the more difficult to debug deep learning models considering their large training time.
In order to best assess our progress, we created a baseline model in which we averaged word embeddings (without using a deep learning model) and used cosine similarity to determine whether questions were duplicates or not. This allowed us to easily compare our accuracy and ensure that our model was improving baseline performance
Accomplishments that we're proud of
We are proud that we were able first to become familiar with and effectively use some of the Natural Language Processing libraries and frameworks within such a short period of time. For all of us, we were using tools that we had been curious about, but really did not have much experience using.
We are also very happy that we got a model to actually train and return something meaningful in such a short period of time, especially given the fact that these Deep Learning experiments can take notoriously long to debug.
What we learned
We learned more intimately what Pytorch was capable of, but also what we could accomplish as a determined and curious group within a short time period.
We gained more of an intuition for the possibilities and limitations of the current state of Natural Language Processing (libraries such as nltk, but also the capabilities of the current state of the art models such as the Neural Language Translation, and the Sequence to Sequence ) and were emboldened to continue to strive for further


Log in or sign up for Devpost to join the conversation.