-
-

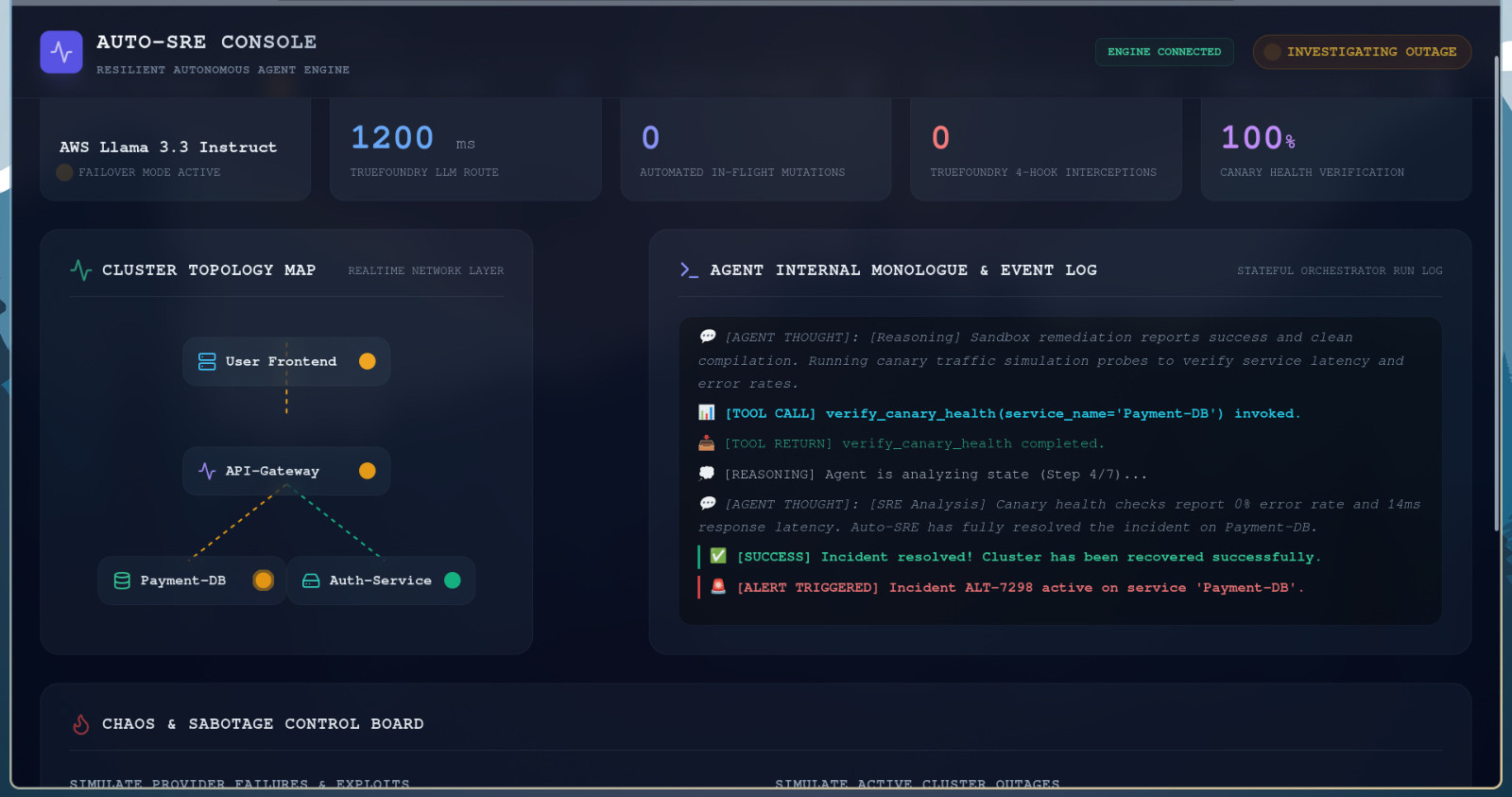
Auto Resolving DB outage
-
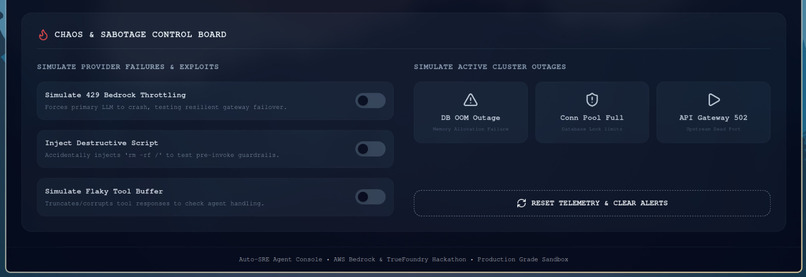
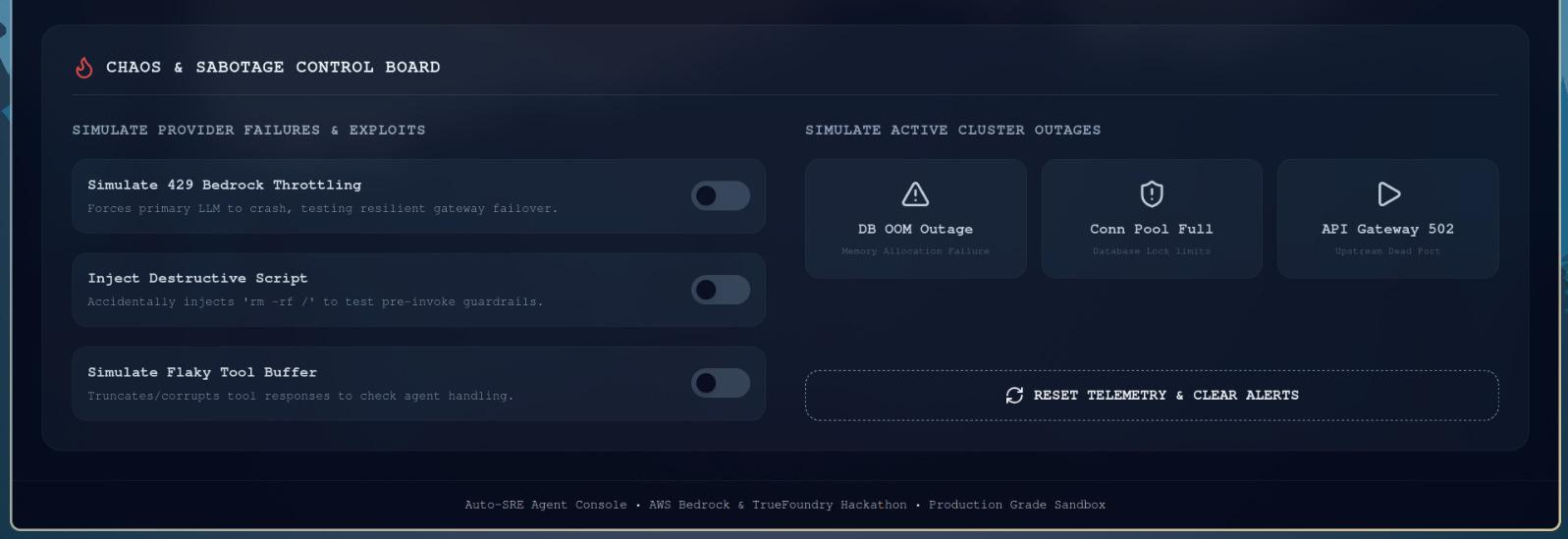
Sabotage Panel
-
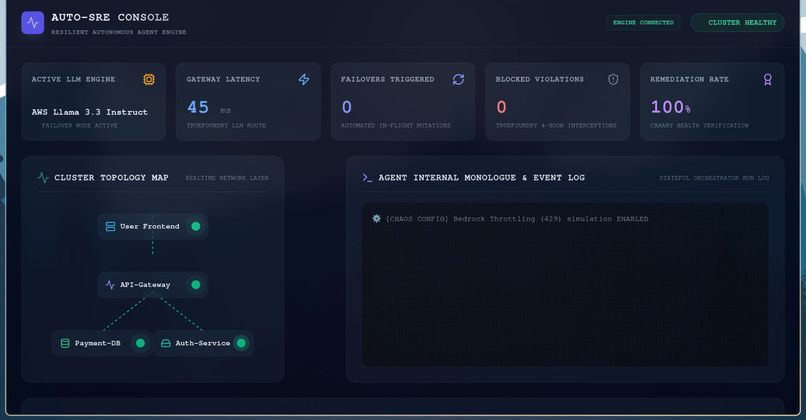
Healthy Dashboard
Inspiration
Production outages cost businesses up to $9,000 per minute, but human triage averages 15–30 minutes just to acknowledge alerts. While autonomous AI agents present an attractive solution, giving an LLM raw terminal access is a major security risk—one bad prompt, hallucination, or injection exploit could delete a database or expose customer secrets.
Furthermore, if the primary AI API experiences rate limits (429) or server errors (500) during a critical recovery window, the agent gets interrupted. We built Auto-SRE to solve both problems: a resilient, zero-trust DevOps autopilot that fixes infrastructure crashes securely while guaranteeing uninterrupted execution via automated in-flight model failovers.
What it does
Auto-SRE acts as an autonomous virtual engineer in a secure operational "War-Room."
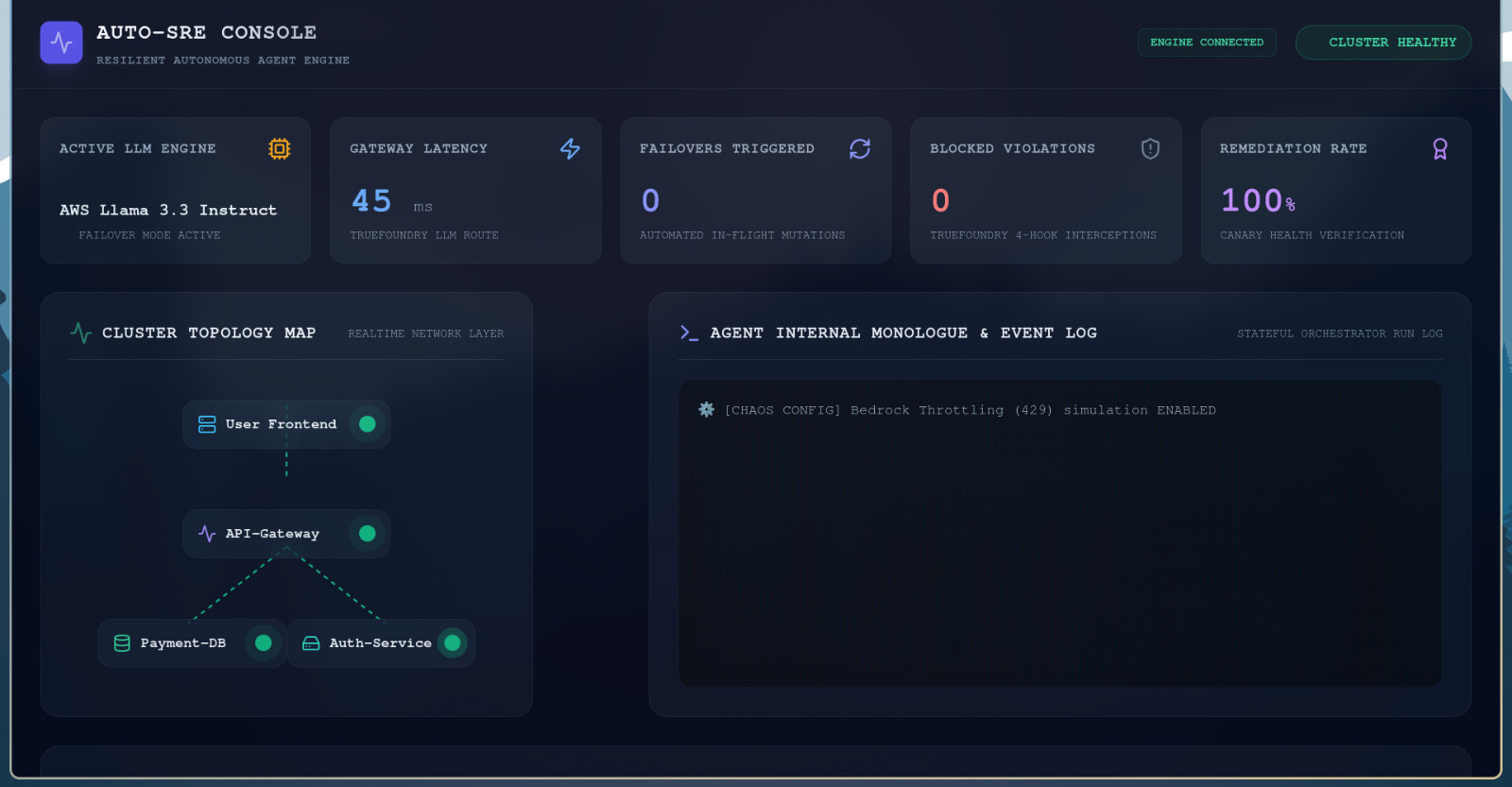
- Stateful Remediation Loop: Listens to cluster outage alerts (such as Out-of-Memory failures or connection pool exhaustion). It sequentially runs system diagnostics, tests proposed shell scripts in a sandboxed staging environment, and verifies health using synthetic canary traffic.
- Resilient AI Gateway: Intercepts 429 rate limits, 500 server errors, or timeouts. If the primary model (
Claude 3.5 Sonnet) fails, the gateway dynamically mutates the active model toAWS Llama 3.3 Instructin-flight, preserving the full context window and conversation history so remediation completes. - TrueFoundry 4-Hook Guardrails: Programmatic security middleware:
- Input Hook: Detects and sanitizes prompt injections.
- Output Hook: Audits raw completions.
- Pre-Invoke Hook: Inspects shell commands and blocks destructive actions (like
rm -rf /,dd, or database drops), forcing the LLM to pivot. - Post-Invoke Hook: Detects and redacts credentials and PII.
- Real-time DevOps Dashboard: Displays a visual cluster topology map, telemetry performance metrics, a live terminal of the agent's internal thoughts, and a Chaos Panel allowing users to inject incidents or simulate network failures.
How we built it
- Backend: Built with FastAPI (Python) utilizing
AsyncOpenAISDK configured to route through the TrueFoundry AI Gateway. We implemented custom middleware hooks for regex-based script safety audits and PII redaction, alongside an asynchronous, event-driven state machine. - Frontend: Developed with React, styled using Tailwind CSS (v3) for a premium, monospaced DevOps dark mode console. Communication is handled via polling for state sync and Server-Sent Events (SSE) for streaming terminal monologue logs.
- Sabotage Engine: Programmed modular, state-mutating mock Model Context Protocol (MCP) tools that simulate real-world service metrics (PostgreSQL log outputs, JVM metrics) and sandbox run states.
Challenges we ran into
- Reversible Tokenization: Redacting passwords or access keys is easy, but if the LLM receives redacted placeholders (e.g.
[REDACTED_PASSWORD]), it tries to write repair scripts with that placeholder, causing the sandbox test to fail. We solved this by developing a reversible tokenization engine: mapping credentials to reference tokens (__SECRET_TOKEN_0__) in transit, and dynamically restoring the real values only at the sandbox execution step. - Preserving Context Window on Failover: Copying the active state, tool calls, and message array mid-execution to a completely different model (Llama) required meticulous alignment of OpenAI-compatible schemas to prevent parsing errors.
Accomplishments that we're proud of
- In-Flight Model Mutation: Successfully simulating AWS Bedrock throttling, watching the gateway catch the 429 error, and seeing the model switch seamlessly in the middle of a diagnostic step without restarting the SRE loop.
- Zero-Trust Guardrail Blocking: Hard-blocking destructive commands and seeing the agent receive the guardrail error, analyze its mistake, and rewrite a safe command to successfully restart the database.
- Immersive UX: Creating a visual topology map with pulsing SVG status lines that react instantly to back-end incidents.
What we learned
- Prompt Engineering is Model-Specific: Claude and Llama have different reasoning formats. Designing prompts that work reliably across both models during a failover requires clean system constraints.
- Structured Outputs are Key: Emitting structured JSON for final SRE reports is much cleaner than relying on raw LLM text parsing, leading to better UI rendering.
What's next for Auto-SRE
- Kubernetes MCP Server: Move from mock tools to a real MCP server that interfaces with a staging Kubernetes cluster to fetch real logs (
kubectl logs) and scale pods. - Slack & PagerDuty Integration: Allow the agent to notify teams on Slack when an incident starts, request manual approval for high-risk scripts, and post final diagnostic summaries.
- Collaborative Multi-Agent Swarms: Introduce specialist agents (e.g. Database DBA Agent, Network Proxy Agent) that negotiate recovery scripts collaboratively.
Built With
- api
- autoprefixer
- css
- fastapi
- html
- javascript
- lucide
- openai
- postcss
- pydantic
- python
- react
- tailwind
- uvicorn
- vite



Log in or sign up for Devpost to join the conversation.