-
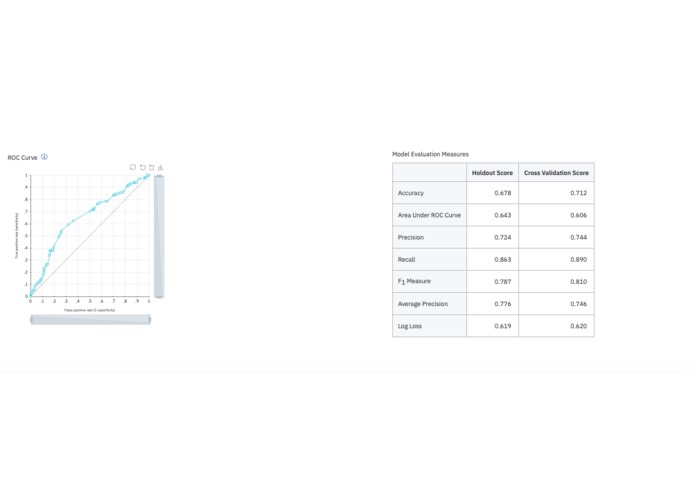
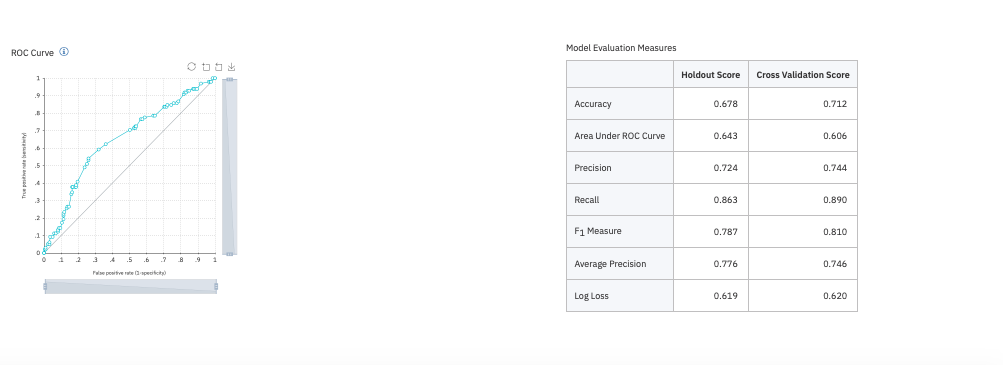
Model Accuracy
-
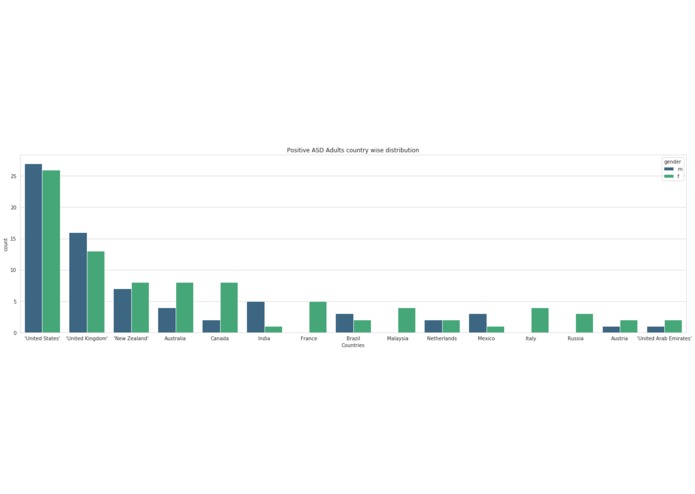
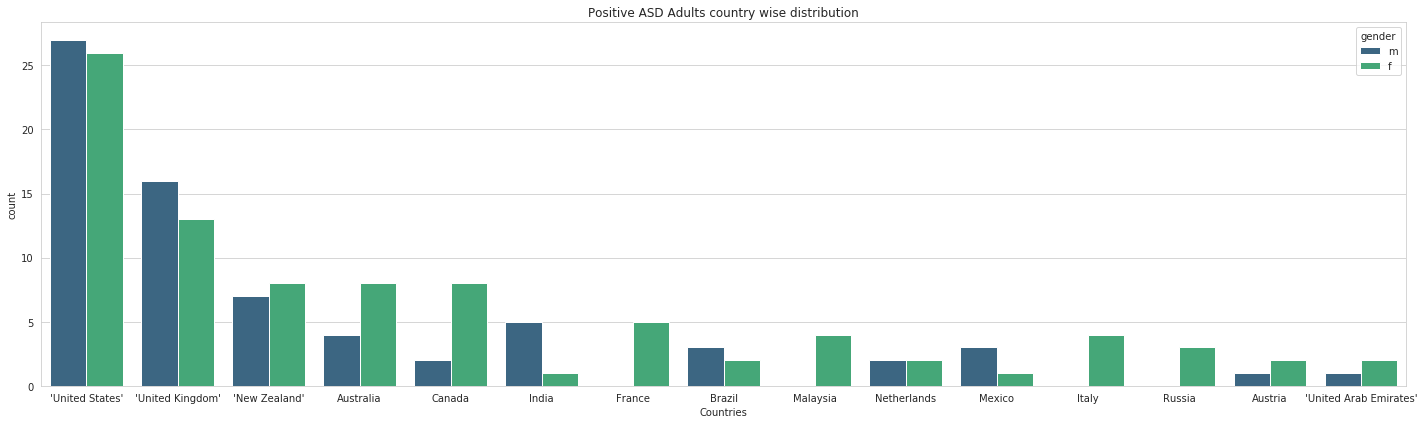
Country-wise distribution of people affected with Autism
Inspiration
Autistic Spectrum Disorder (ASD) is a neurodevelopment condition associated with significant healthcare costs, and early diagnosis can significantly reduce these. The economic impact of autism and the increase in the number of ASD cases across the world reveals an urgent need for the development of easily implemented and effective screening methods. Therefore, a time-efficient and accessible ASD screening is imminent to help health professionals and inform individuals whether they should pursue formal clinical diagnosis. The rapid growth in the number of ASD cases worldwide necessitates datasets related to behaviour traits. However, such datasets are rare making it difficult to perform thorough analyses to improve the efficiency, sensitivity, specificity and predictive accuracy of the ASD screening process. Presently, very limited autism datasets associated with clinical or screening are available and most of them are genetic in nature.
What it does
Hence, we propose a new dataset related to autism screening of adults that contained 20 features to be utilised for further analysis especially in determining influential autistic traits and improving the classification of ASD cases. With just the help of these features - including sample questionnaires and some birth facts, we have provided a Machine Learning model that can evaluate the chances of a person being diagnosed with autism with an accuracy of around 80%.
How we built it
We took Autism Screening Questionnaires and developed a set of features with the output being in a binary format of 0 or 1 evaluating or NO or a YES. Some of these Questions were as follows: . has a deviant style of communication with a formal, fussy, old-fashioned or “robotlike” language
- invents idiosyncratic words and expressions
- has a different voice or speech
- expresses sounds involuntarily; clears throat, grunts, smacks, cries or screams
- is surprisingly good at some things and surprisingly poor at others
- uses language freely but fails to make adjustment to fit social contexts or the needs of different listeners
- lacks empathy
- makes naïve and embarrassing remarks
- has a deviant style of gaze
- wishes to be sociable but fails to make relationships with peers
- can be with other children but only on his/her terms
- lacks best friend
- lacks common sense
- is poor at games: no idea of cooperating in a team, scores “own goals”.
We also had other features such as ethnicity, gender etc.
The dataset was then refined in order to reduce the features by cutting down the ones that weighted a lot less by having very little significance on the output classification.
We deployed the model in 2 phases:
Used several distinct classifiers such as Logistic Regression, Decision Trees, Random Forest and an Ensemble Classifier to get the best possible trained model and evaluate it based on past models used. Ran the model on Google Colab.
Used IBM Watson to generate a model for the refined data we had. It made it easier since it showed 4 pipelines with different hyper-parameters tuning. We created a model and deployed the same to be used on our mobile devices as a service.
Challenges we ran into
Overfitting was the most serious problem we had. Finding the correct ratio of bias vs variance was really difficult to find as some features were being overweighed by our models thereby making the other features redundant. This was more prominently happening on IBM Watson as it tries to derive the best possible model by running huge number of epochs and iterations over the model thereby overfitting it. As far as manual running was concerned, we reduced overfitting by tuning the hyper-parameters such as reducing the number of epochs, using different models to come up with a better fit for unseen inputs, etc. For IBM Watson, we observed that the testing data was very less as it automatically uses only 5% of the data for testing and 95% for training. So the model is overtrained on a number of examples it observes. We increased the amount of testing data to 30%. After that, we had to make altercations with the data, as it was not consistent with data types, thereby causing problems in giving a better result. So we made the data consistent with data types and the model started giving way better results.
We saved this model and deployed it for using it as a service.
Accomplishments that we're proud of
Waiting times for an ASD diagnosis are lengthy and procedures are not cost effective. By using our methodology of incorporating Machine Learning with probable screening questionnaires, we will be able to cull out these problems and it will be viable for everyone to use. This is a model created with keeping people in mind. We want to make sure that everyone is given an equal and proper chance to diagnose their child with autism.
What we learned
We were able to learn the AutoAI feature of IBM Cloud and how using it can save considerable time and space. Apart from that, we were able to effectively run and train the model on Google Colab which was furthermore a big advantage for us.
What's next for Autism Detector
We want to improve the accuracy of our model and improve the dataset further. There is a lot of variance in screening questions from place to place and we want to try incorporating all those with dependencies on the place the person being diagnosed is from.
Built With
- android-studio
- decisiontreeclassifier
- ensemble
- google-cloud
- ibm-watson
- logisticregression
- matplotlib
- numpy
- pandas
- python
- randomforestclassifier
- scikit-learn
- sns
- supportvectormachine


Log in or sign up for Devpost to join the conversation.