-
-
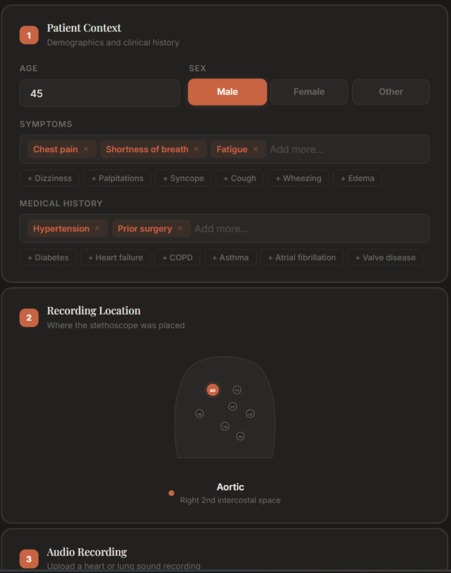
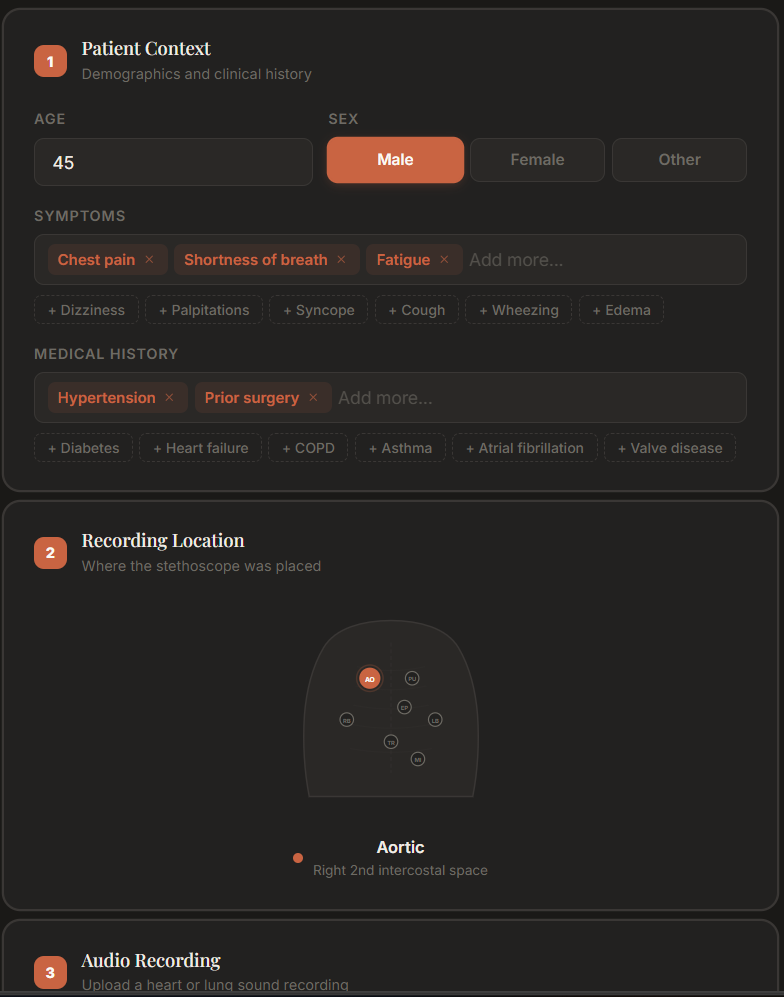
Interface for uploading/recording patient heartbeat
-
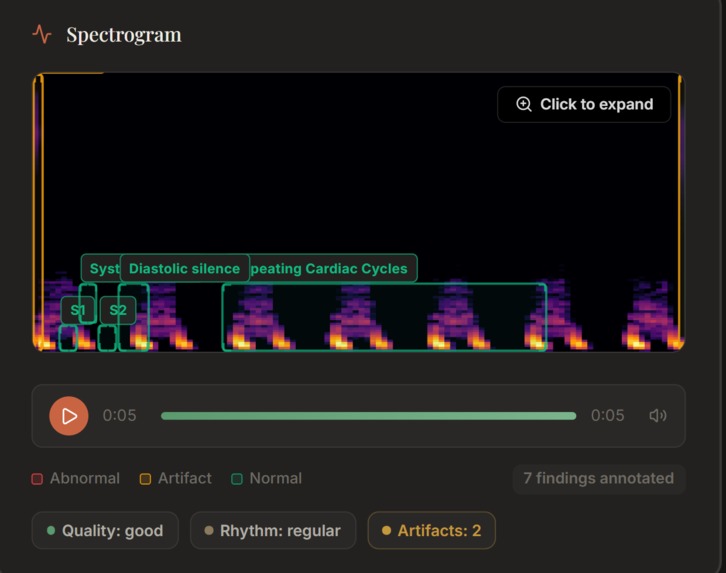
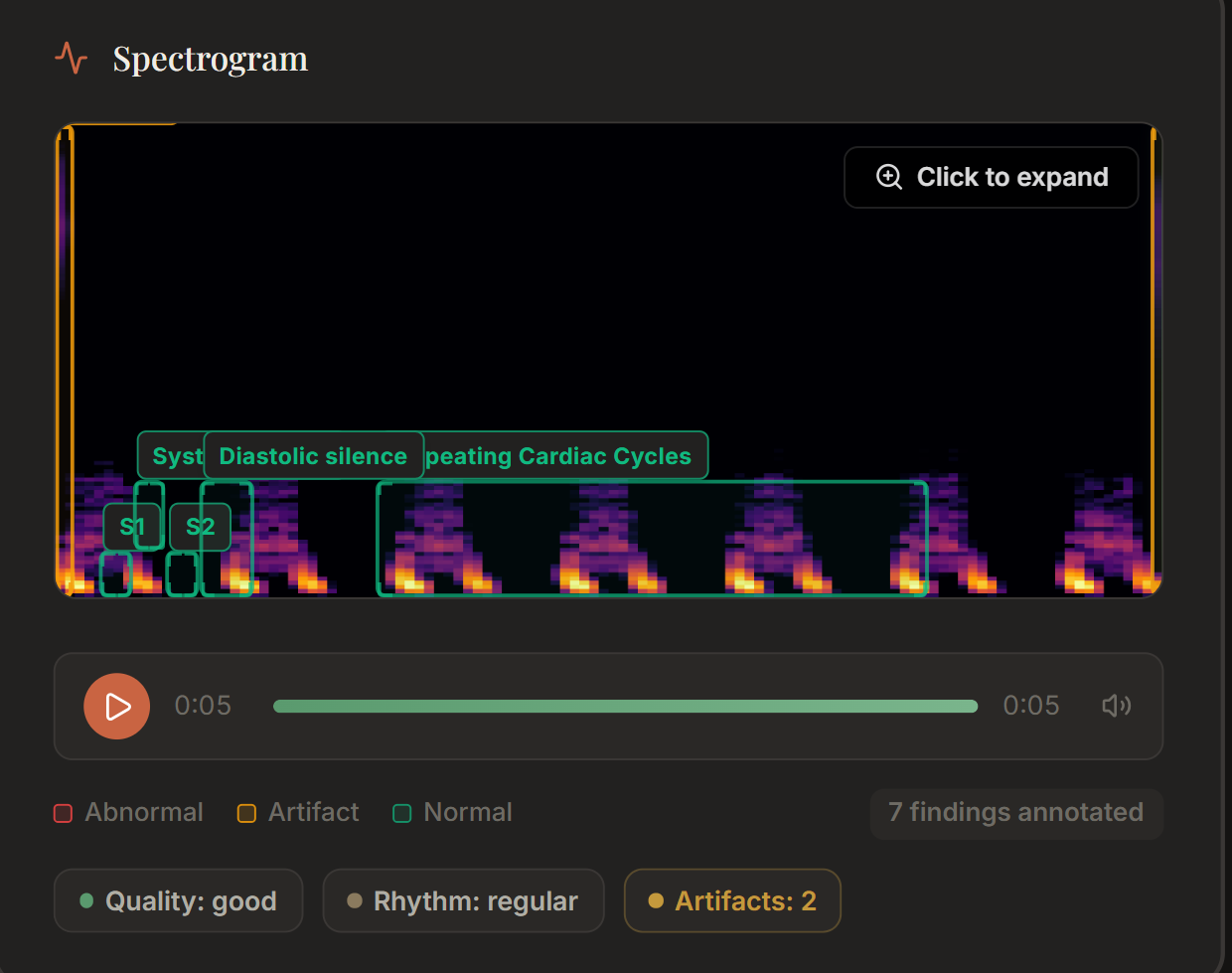
Spectrogram analysis
-
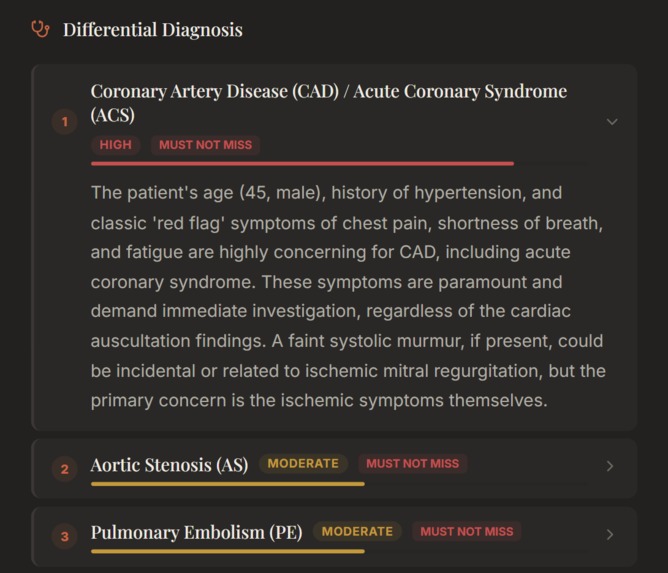
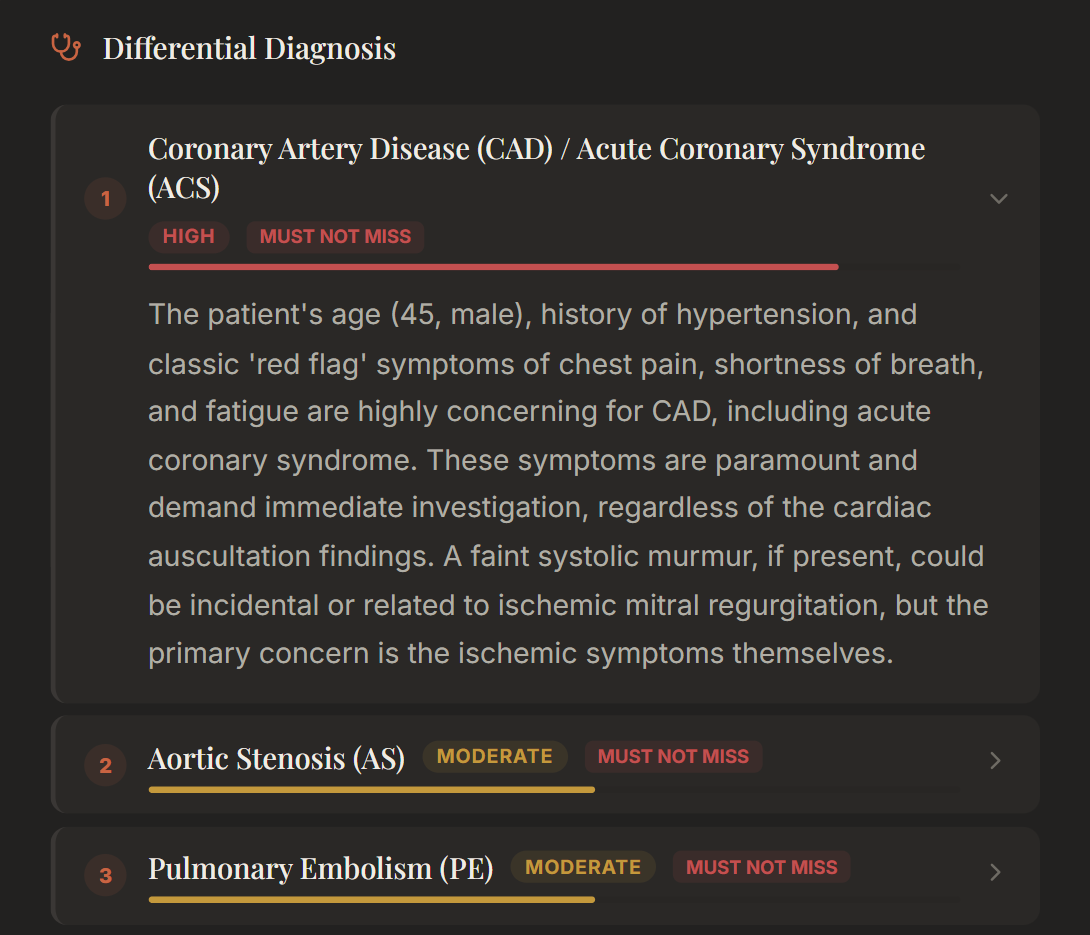
Differential diagnosis after initial recording
-
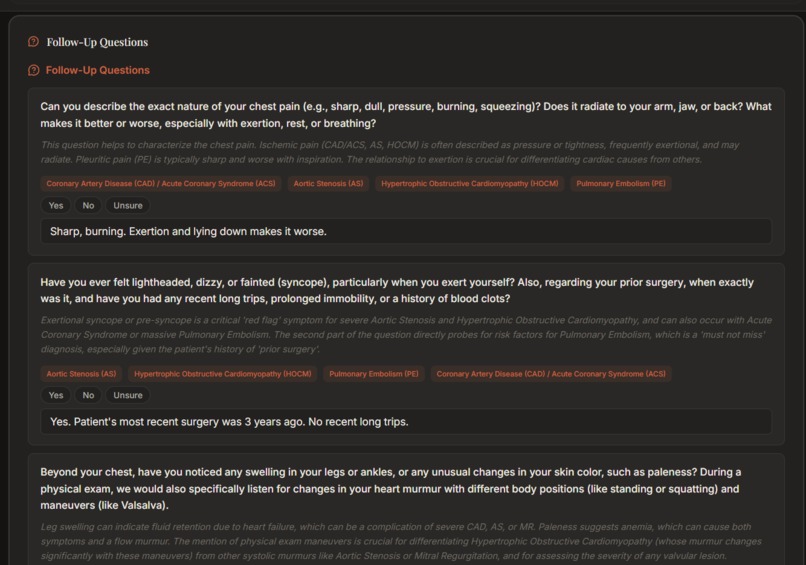
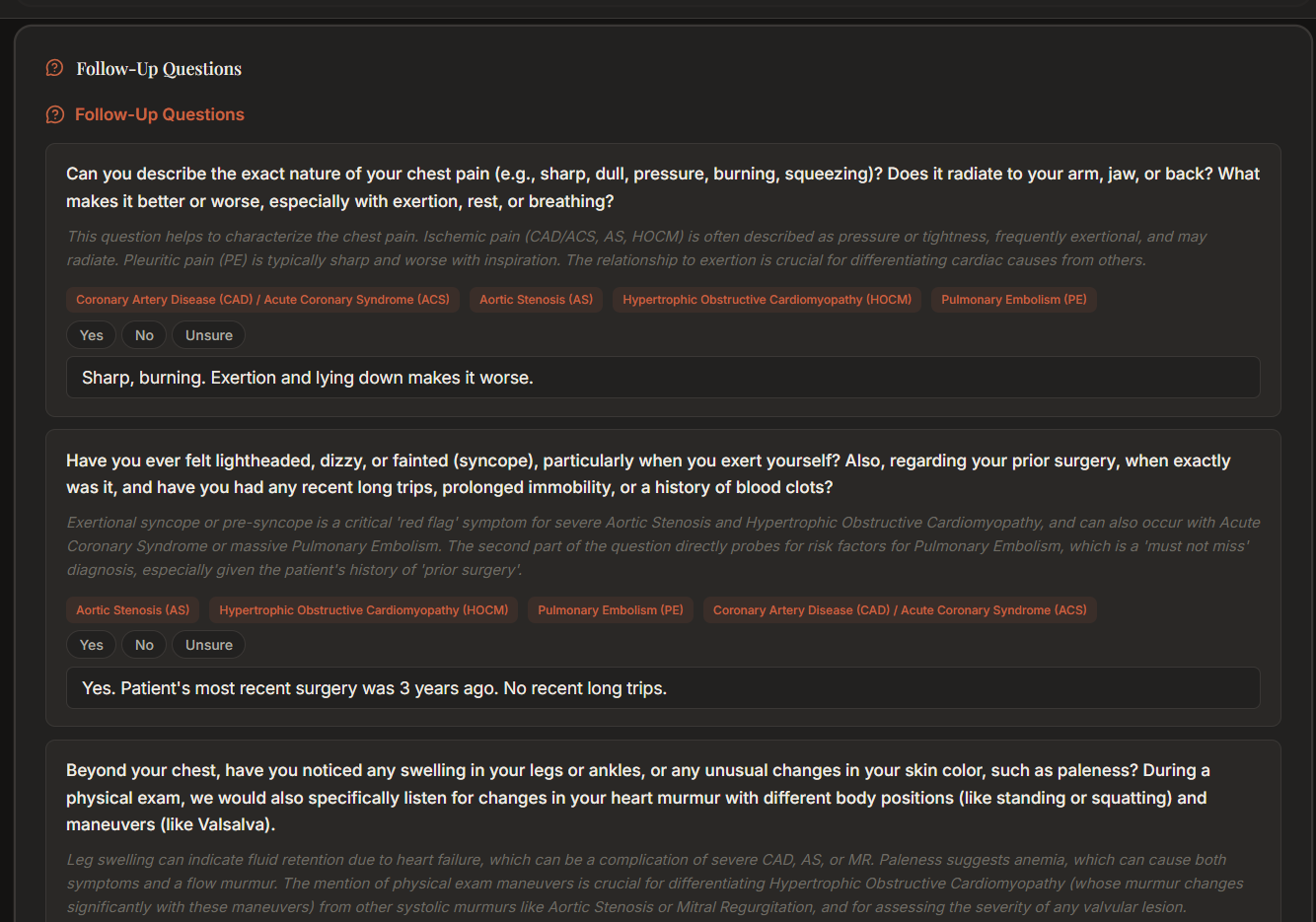
Follow-up questions to refine the diagnosis (a recording at a secondary chest location is also an option)
-
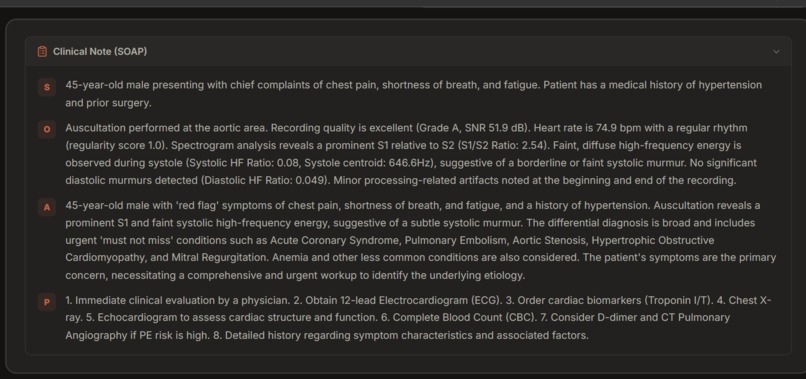
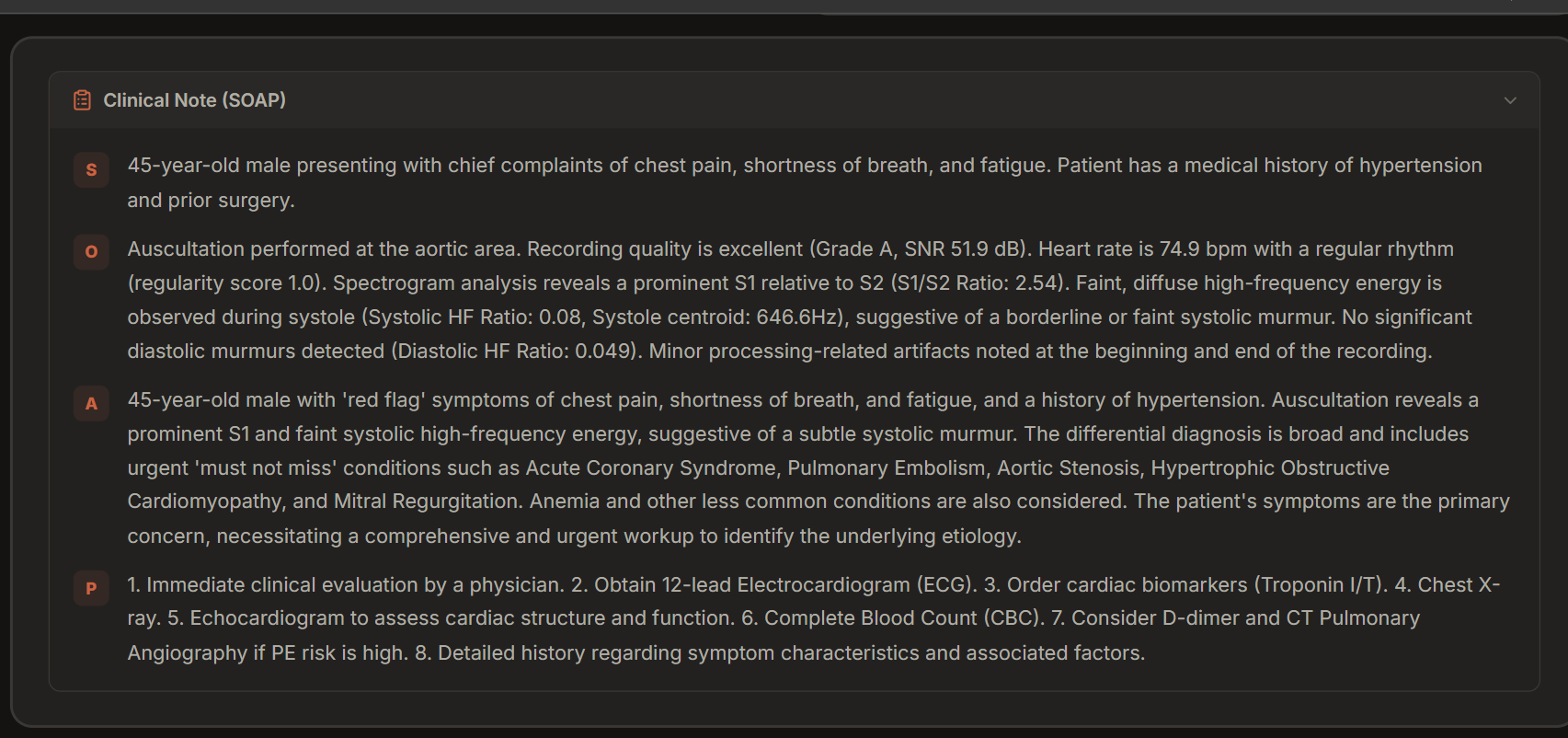
Final SOAP notes for use by the care provider
AuscultAI — Project Story
Inspiration
The stethoscope is 200 years old. In that time, almost nothing about how clinicians interpret what they hear has changed — it still requires years of trained intuition that most doctors simply don't have time to develop.
We learned that the average medical student receives fewer than 2 hours of auscultation training before graduating. Rural and primary care physicians routinely miss murmurs, arrhythmias, and early-stage valve disease because they haven't heard enough hearts to pattern-match confidently. Meanwhile, specialist access in rural areas can mean a 3-month wait for an echocardiogram referral.
Existing digital stethoscopes (Eko CORE 500, Littmann CORE) can label a sound as "murmur" or "normal." But a label without reasoning is not useful to a non-specialist. "Murmur detected" does not tell you whether to refer urgently, watch and wait, or reassure the patient.
We wanted to build the thing that comes after the label — the explanation, the differential, the follow-up question, the teaching moment.
What We Built
AuscultAI is a smart stethoscope system built on a Raspberry Pi 4 with a MEMS microphone seated inside a standard acoustic stethoscope. The hardware is under $170. The intelligence is Gemini.
The pipeline works as follows:
- Capture — 15-second recording through the stethoscope chest piece
- DSP — Butterworth bandpass filter ($20$–$2000$ Hz), spectral noise gating
- Spectrogram — Mel spectrogram generated with librosa:
$$S(f, t) = \left| \text{STFT}(x)[f, t] \right|^2$$
- Local CNN classifier — TFLite model trained on PhysioNet CinC 2016 (~3,000 labeled recordings, 96.2% test accuracy) gives an initial fast signal
- Gemini multi-agent reasoning — a 5-node LangGraph pipeline:
- Analyst sees only the spectrogram image (blinded to demographics to prevent confirmation bias) and describes visual patterns
- Reasoner receives patient context + RAG-retrieved cardiology knowledge (AHA/ACC 2020, Braunwald's 12th ed) and builds a differential
- Reviewer critiques the differential for cognitive biases and missed diagnoses
- Synthesizer produces the final structured output
- Agentic loop — Gemini generates follow-up questions; clinician answers; answers feed back into the pipeline for a refined diagnosis
- React dashboard — real-time pipeline visualizer, annotated spectrogram, collapsible differential with reasoning, SOAP clinical note, educational explanation
The Gemini Differentiator
The key insight is that a narrow classifier cannot do what a large multimodal model can. A CNN trained on PhysioNet outputs:
$$P(\text{abnormal} \mid \text{spectrogram}) = 0.78$$
That number is useful as a signal. But it cannot tell you why it said 0.78, cannot ask whether the murmur changes with the Valsalva maneuver, cannot notice that the high-frequency artifact at 800 Hz might be a pleural friction rub rather than a cardiac sound, and cannot explain the crescendo-decrescendo pattern to a medical student in plain language.
Gemini does all of that. It reasons across modalities — visual (spectrogram image), text (patient symptoms, demographics, conversation history), and structured data (classifier confidence scores) — in a single coherent reasoning chain.
How We Built It
Hardware: Cut the stethoscope tubing at the Y-split. Seated a USB MEMS mic capsule inside the open tube end with hot glue for an airtight seal. The stethoscope diaphragm does the acoustic amplification; the mic just digitizes what comes through.
Backend: FastAPI serving a LangGraph StateGraph. SSE streaming pushes real-time agent progress to the frontend so users watch the pipeline animate node by node. Rate limiting and retry logic handles Gemini's free-tier 15 RPM ceiling.
RAG knowledge base: FAISS vector index over ~40 cardiology documents covering 6 cardiac conditions and lung sounds from ICBHI 2017. Injected into the Reasoner's context window at inference time.
Frontend: React + Vite. Three views: Input → Pipeline → Report. The pipeline page is a full-screen interactive canvas — draggable nodes, pan/zoom, clickable detail panels showing model architecture and data sources. The report page includes a guided tour on first visit and collapsible sections to avoid overwhelming users.
Challenges
Acoustic coupling. Getting a clean signal out of a $10 acoustic stethoscope and a $4 MEMS mic required obsessing over the seal. A small air gap drops signal amplitude by 60%+. Hot glue and patience.
Gemini rate limits. Five sequential agent calls at 15 RPM on the free tier means the pipeline takes 30–60 seconds. We added an animated pipeline visualizer specifically so the wait feels intentional and informative rather than broken.
Spectrogram bounding box accuracy. Asking Gemini to return pixel coordinates for visual annotations on a spectrogram is unreliable — the coordinates often don't align with actual features. We render whatever Gemini returns but treat it as illustrative rather than precise.
CNN train/test leakage. Our augmented training pipeline (5× oversampling of the abnormal class) created augmented copies that leaked across the train/test split. The 96.2% accuracy is optimistic; real-world performance is likely 80–90%. We're transparent about this in the UI — the CNN is a supporting signal, not the star.
What We Learned
Building this project taught us that the hardest part of applying AI to healthcare is not the model — it is the interface between the model's output and the clinical workflow. A confidence score means nothing to a nurse practitioner in a rural clinic. A sentence that says "the systolic crescendo-decrescendo pattern here, combined with your patient's age and the absence of syncope, makes an innocent flow murmur more likely than aortic stenosis — but ask about family history of bicuspid aortic valve" is actionable.
That translation — from raw signal to clinical reasoning — is exactly what Gemini makes possible. That is why we built this.

Log in or sign up for Devpost to join the conversation.