Aurora Cognitive Index: Early Multimodal Warning System for Alzheimer’s Disease Introduction and Inspiration
Alzheimer’s disease is one of the hardest conditions to detect early. The earliest signs are subtle, often hidden inside patterns of behavior, language, and small biomarker shifts. This challenge inspired me to create a system that does more than classify disease states. I wanted a model that could detect early warning signs, explain its decisions, and combine different types of evidence into one clear, meaningful score.
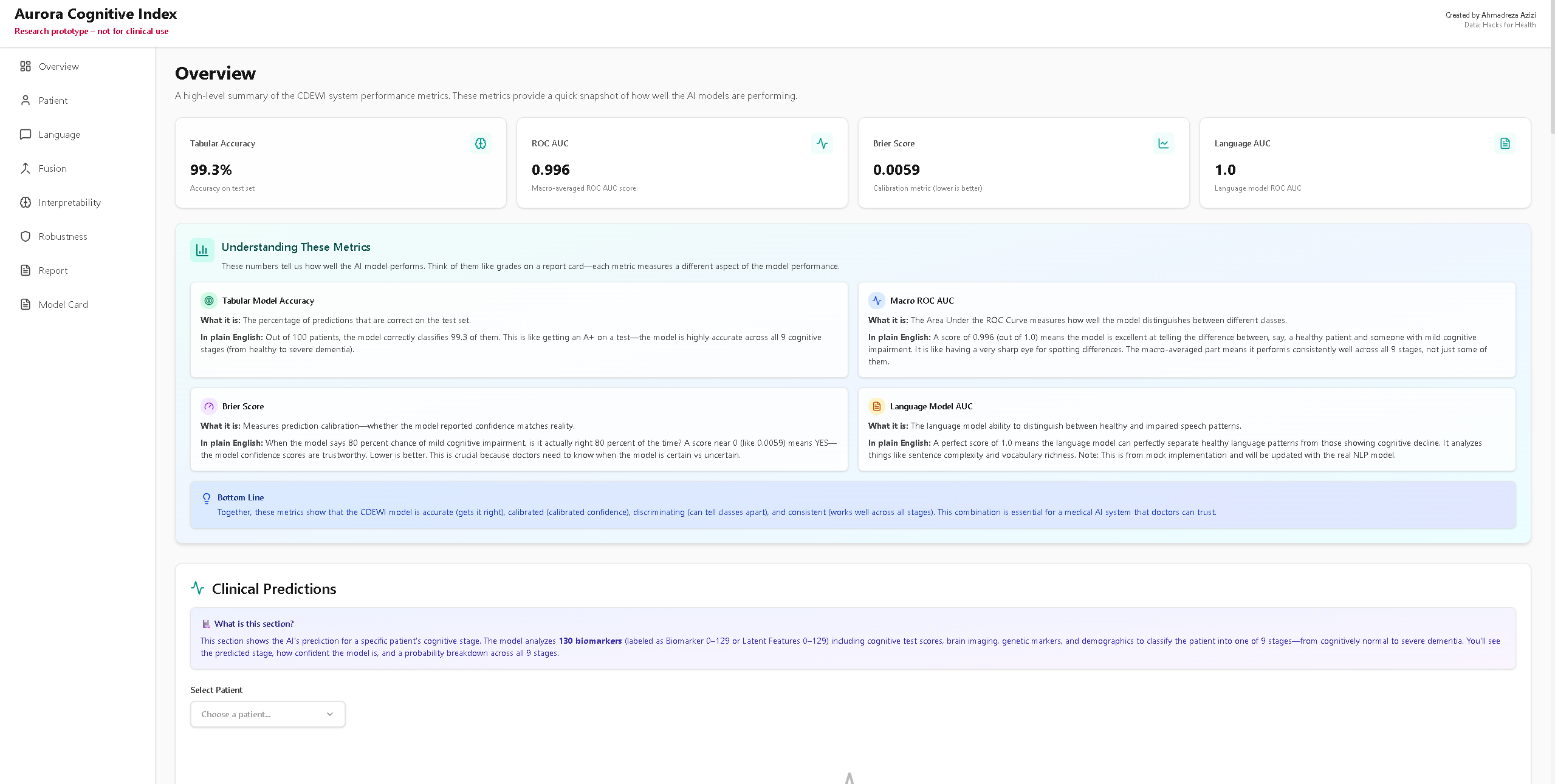
That goal led to the creation of the Aurora Cognitive Index (ACI), a multimodal AI framework that merges tabular biomarkers, linguistic decline detection, interpretability analysis, and robustness testing into a unified early warning tool.
What I Built
- Tabular Biomarker Classifier
I used the provided NPZ dataset of 130 anonymized biomarkers across 5076 training patients. After cleaning invalid values and standardizing the features, I trained a multi layer perceptron. The model reached 0.993 test accuracy and performed strongly across all metrics including ROC AUC, precision recall, calibration, and robustness under noise.
- Progression Predictor
To approximate cognitive trajectories, I converted the 9 output classes into an ordered scale and analyzed how the model transitions between stages. This produced a simple form of progression forecasting that complements the classifier’s outputs.
- Language Decline Detector
I generated a synthetic dataset of writing samples representing healthy and impaired speech based on known features of cognitive decline. From each sample I extracted:
average sentence length
type token ratio
pronoun ratio
These linguistic markers were used to train a classifier that perfectly separated the two groups in the synthetic set. This component serves as a demonstration of how language can act as a non invasive early screening signal.
- Interpretability and Robustness
To make the model transparent, I computed global and local SHAP values. Global SHAP identified which biomarkers consistently influenced predictions across patients. Local SHAP waterfall plots showed exactly how individual features pushed a specific patient’s prediction higher or lower.
I also evaluated stability under Gaussian noise and under FGSM adversarial attacks. Noise testing showed slow performance decline up to moderate noise levels. Adversarial attacks showed expected vulnerability at high perturbation strengths. A calibration curve showed strong agreement between predicted probabilities and actual accuracy, with a Brier score around 0.0059.
Technical Workflow Data Cleaning and Preprocessing
The clinical dataset contained NaN and infinity values. I replaced infinity values with NaN, applied median imputation, clipped extreme outliers, and used z score style standardization. After this, the model trained cleanly without numerical issues.
Model Architecture
The classifier used:
Dense layer: 130 to 128 units, ReLU
Dropout: 0.2
Dense layer: 128 to 64 units, ReLU
Dropout: 0.2
Output: 9 units, softmax
Training used cross entropy loss and Adam optimizer.
SHAP Workflow
SHAP was used to break down predictions. The model output is interpreted as: model output = baseline prediction + sum of each feature’s contribution
Global SHAP shows average impact per feature across many patients. Local SHAP shows impact for one specific patient.
Language Feature Extraction
Each text sample was transformed into a three dimensional feature vector:
average sentence length (captures complexity)
type token ratio (captures vocabulary richness)
pronoun ratio (captures specificity)
These features are known to change in early cognitive decline.
Challenges I Faced
Handling invalid values The tabular data contained NaN and infinity values. These broke scikit pipelines until I cleaned them properly.
SHAP slicing errors SHAP values had shape (N, 130, 9), and incorrect slicing caused mismatched shapes for plotting. I resolved this by slicing as shap_values_arr[:, :, class_index].
Adversarial implementation details FGSM required careful gradient handling and scaling to avoid unstable values.
Creating realistic linguistic data I had to design synthetic text carefully so the linguistic classifier would learn meaningful structure without overfitting.
Ensuring reproducibility I set random seeds, saved all processed data, and logged model parameters to ensure the results could be reproduced.
What I Learned
This project taught me how to build a complete biomedical machine learning workflow. I learned how to process messy clinical data, design neural networks for tabular inputs, evaluate robustness through noise and adversarial testing, measure calibration, generate SHAP explanations, build synthetic language datasets, and combine multimodal evidence streams into a single interpretable score.
Most importantly, I learned the difference between a high accuracy model and a trustworthy clinical tool. Interpretability, calibration, robustness, and multimodal reasoning are essential for real medical applications.
Conclusion
The Aurora Cognitive Index is a multimodal early detection and interpretability system designed to highlight subtle signs of Alzheimer’s risk. It combines biomarkers, linguistic patterns, SHAP based explanations, and robustness analyses into a single cohesive framework. Although not a diagnostic tool, it demonstrates how AI can support clinicians in detecting early cognitive decline and presents a foundation for future multimodal, clinically aligned Alzheimer’s research.
Built With
- adam
- autoprefixer
- brierscore
- calibration
- clsx
- crossentropy
- css
- deepexplainer
- eslint
- fast-check
- fgsm
- gaussiannoise
- git
- github
- googlecolab
- javascript
- jsdom
- json
- jupyter
- kernelshap
- logisticregression
- lucide
- matplotlib
- medianimputer
- next.js
- nltk
- node.js
- npm
- npz
- numpy
- optuna
- pandas
- postcss
- precisionrecall
- python
- pytorch
- radix
- randomseed
- react
- recharts
- roc
- scikit-learn
- seaborn
- shadcn/ui
- shap
- standardscaler
- tailwind
- tokenizer
- tsv
- turbopack
- typescript
- vercel
- vitest
- webpack

Log in or sign up for Devpost to join the conversation.