-
-
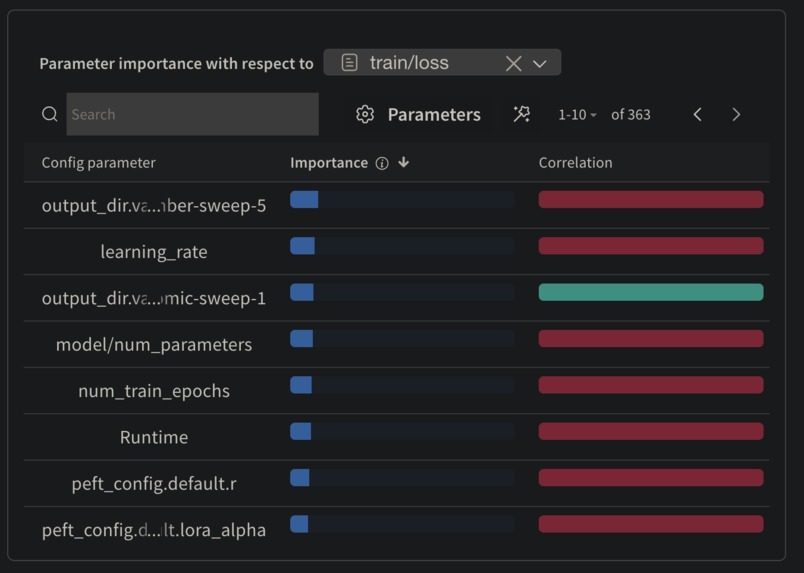
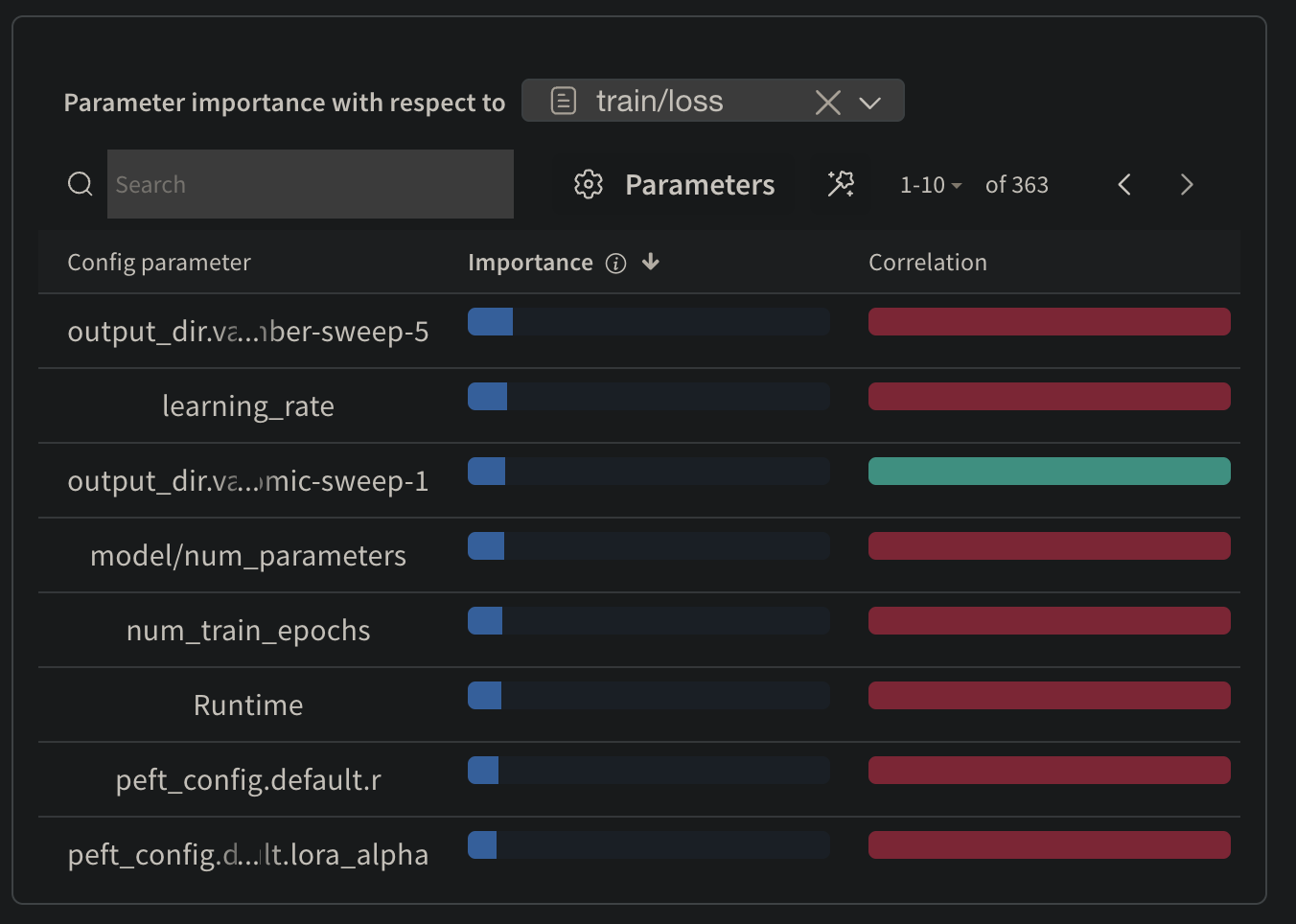
Parameter Importance
-
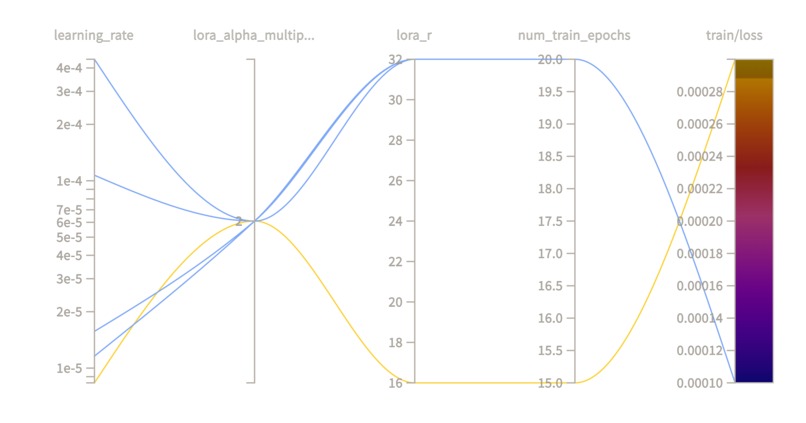
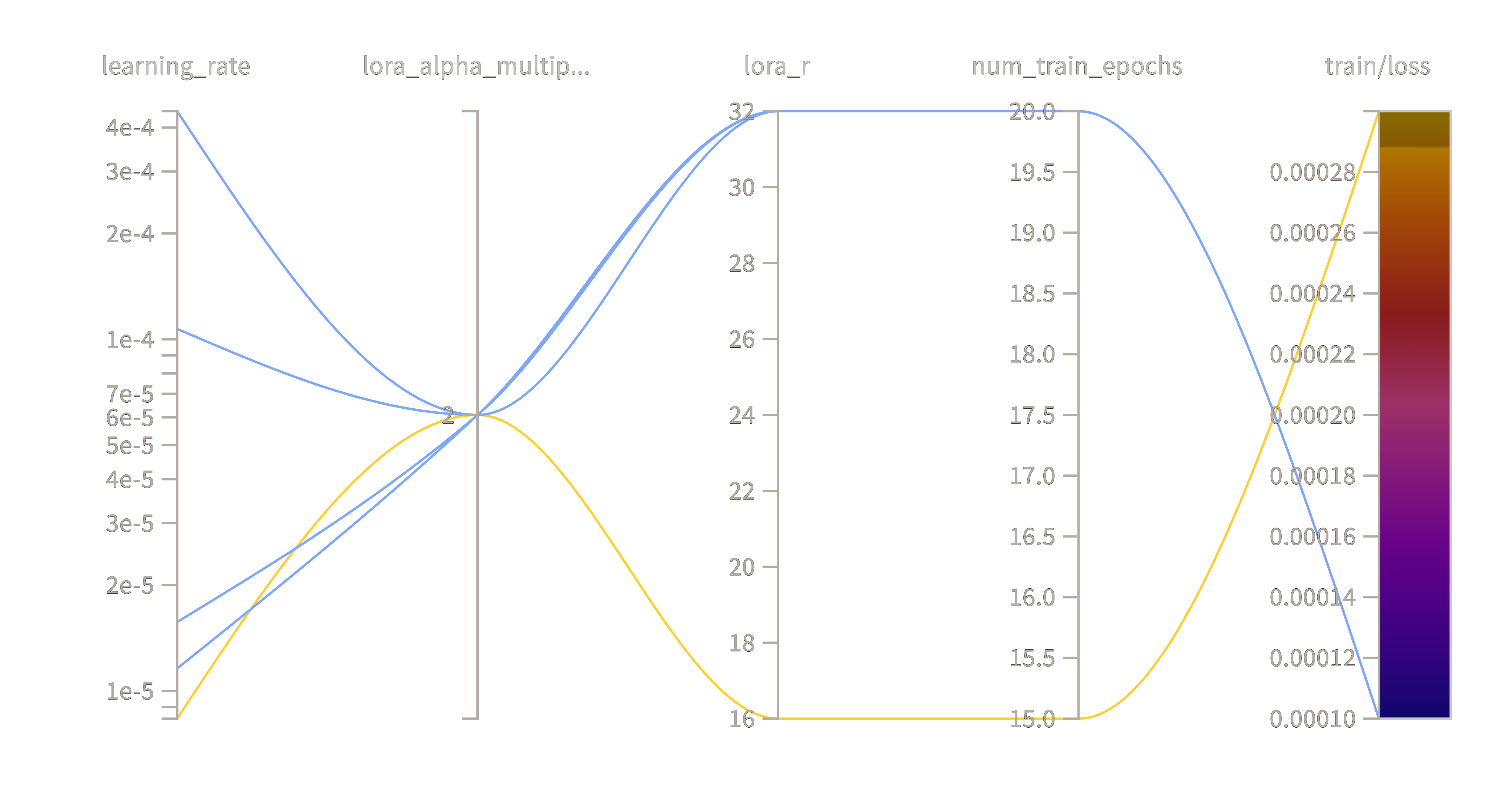
The Parallel Coordinates Plot
-
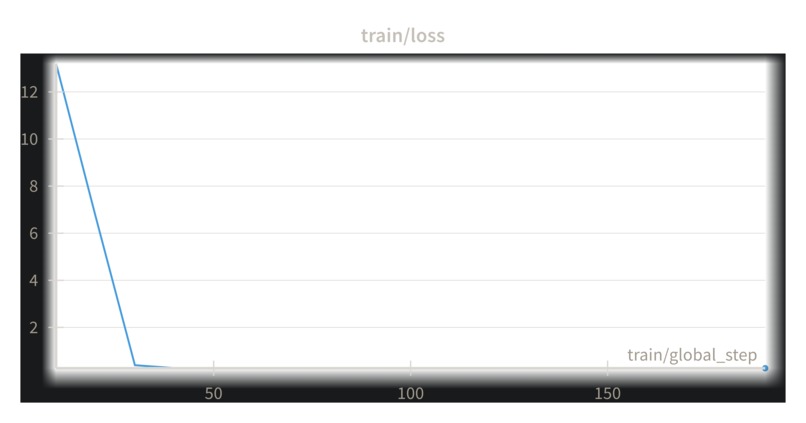
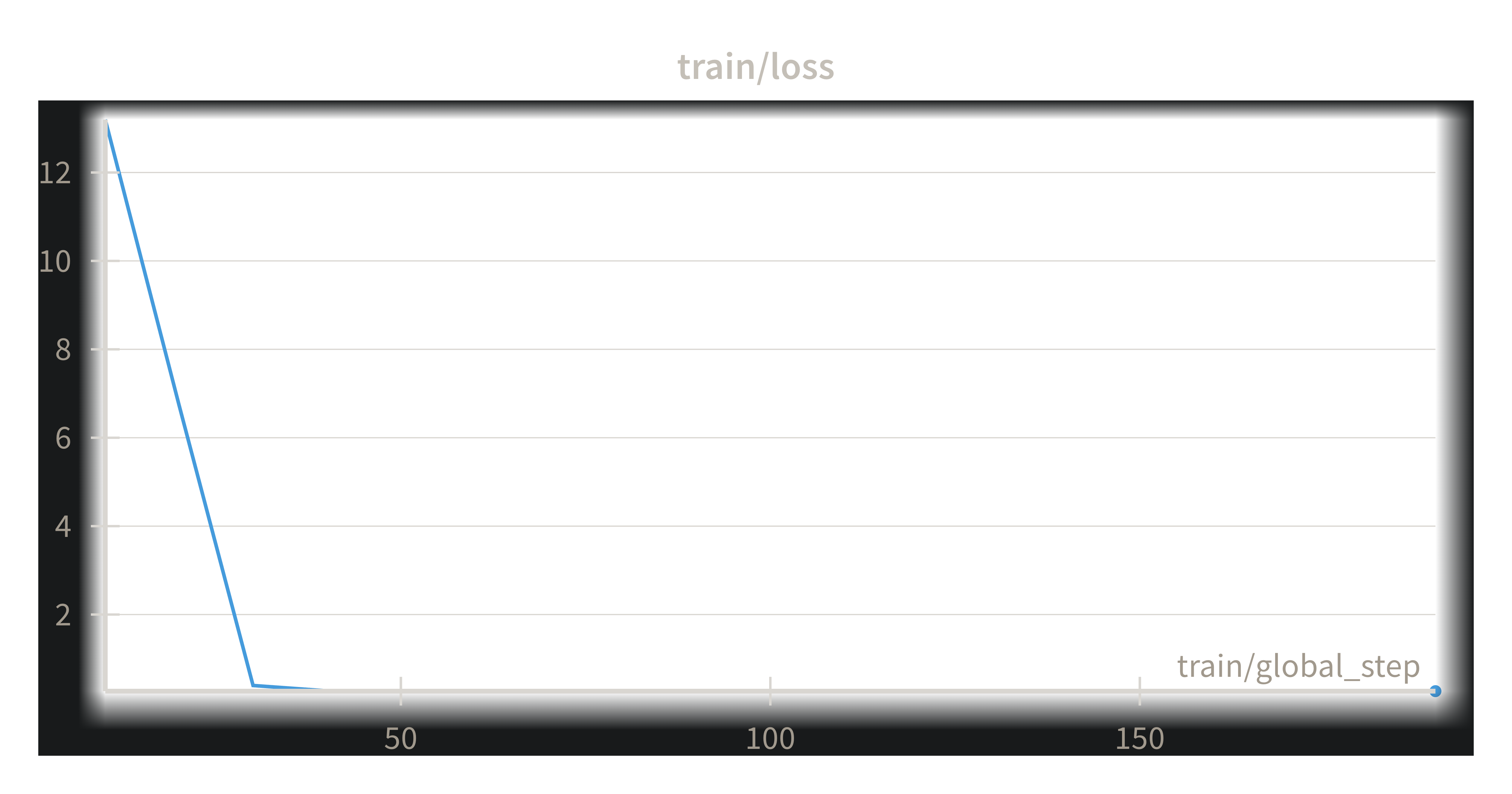
loss curve on 2 GPU's
-
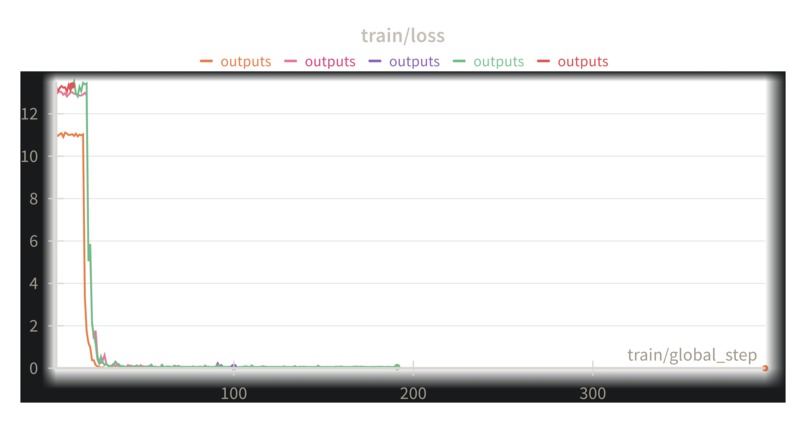
loss curve on 1 GPU
-
The Spark: A Problem I Couldn't Ignore
This project didn't start in a sterile lab or a corporate boardroom. It started with a memory and a frustration. Growing up in Nigeria, I've always been surrounded by the vibrant, chaotic, and beautiful reality of our local agriculture. I've walked through markets like the one at Boundary, in Apapa, Lagos—a sprawling universe of produce where the hopes of countless farmers are laid out on display. But I've also seen the other side: the quiet desperation in a farmer's eyes when they see their maize leaves yellowing, their tomato plants wilting, their peppers succumbing to a blight they can't name.
This isn't a small problem. Agriculture is the backbone of our economy, employing over 70% of Nigeria's population, yet it's a sector fighting an uphill battle. We face an estimated 30-40% in crop losses annually due to pests and diseases. For a smallholder farmer, that's not just a statistic; it's the difference between sending their children to school and another year of struggle. The knowledge to fight back exists, but it's locked away in academic papers and expert manuals, inaccessible to those who need it most, especially in rural areas where the biggest barrier isn't just the cost of data, but the near-total lack of reliable internet connectivity.
The spark for this project came from a paper by Professor T. O. Anjorin from the University of Abuja, which demonstrated the potential of using deep learning to identify local crop diseases. It was a brilliant proof of concept, but it highlighted a gap: how do we take this powerful lab-based technology and put it directly into the hands of a farmer in a remote village, in a way that works offline, speaks their language, and understands their reality?
This became my mission: to build a tool that was personal, private, and powerful enough to run in the palm of a farmer's hand.
The Proposed Solution: An AI That Lives on the Edge
I envisioned Aura-Mind: an offline-first, AI-powered companion that could run on a basic Android phone. A farmer could simply take a picture of a struggling plant, and the AI would provide a probable diagnosis and simple, actionable, low-cost advice—no internet required.
The launch of Google's Gemma 3N, a powerful multimodal model designed for on-device operation, was the final piece of the puzzle. The technology was finally here. The challenge was to bend it to our will.
The Journey: A Trial by Fire
The path from idea to a working model has been a brutal, beautiful, and deeply personal fight. It has been a microcosm of the very problem we're trying to solve: a battle against constraints, a search for knowledge, and an absolute refusal to quit.
The First Hurdle: Data, The Real Gold
The academic dataset from Prof. Anjorin's paper was a fantastic starting point, but I quickly realized it wasn't enough. It was clean, academic. I needed the messiness of the real world. I went to the market at Boundary, Apapa, with my phone. I didn't just take pictures of perfect, diseased leaves; I photographed the rejected piles. The bruised tomatoes, the spotted peppers, the maize cobs with their husks half-torn, sitting in wicker baskets under the harsh Lagos sun. I spoke to the sellers, the real experts, and gathered not just images, but context. This project is built on that ground truth.
The Second Hurdle: The Tools and the "Goliath" of Complexity
My initial plan was to use Apple's MLX framework on my MacBook. It felt like the perfect "David vs. Goliath" story—building a powerful AI on a personal computer. But the libraries were too new, the dependencies too fragile. It was a dead end.
I pivoted to the cloud, using free tiers on Google Colab and Kaggle. This is where the real war began. The next few weeks were a relentless cycle of debugging:
- We fought dependency hell, with
protobufandtensorflowversions clashing in the dead of night. - We battled cryptic hardware errors, like the infamous
CUDA:1 and cpuerror on Kaggle's multi-GPU machines, a problem that forced us to understand the deep, internal workings of device mapping. - We were mocked by the "Silent Hang," where a training job would run for hours, GPUs blazing at 0%, because of a subtle I/O bottleneck from loading high-resolution images. We solved it by building a robust pre-processing pipeline, only to discover a better way.
The Breakthrough: From a Working Model to a Perfect One
The turning point came from the Unsloth community. After weeks of fighting what I thought was a broken model—one that showed a perfect training loss but a baffling 0% accuracy—I found the clue. A known architectural quirk in the fine-tuned Gemma 3N meant my initial evaluation method would never work.
This was a painful, liberating discovery. My model wasn't broken; my measuring stick was.
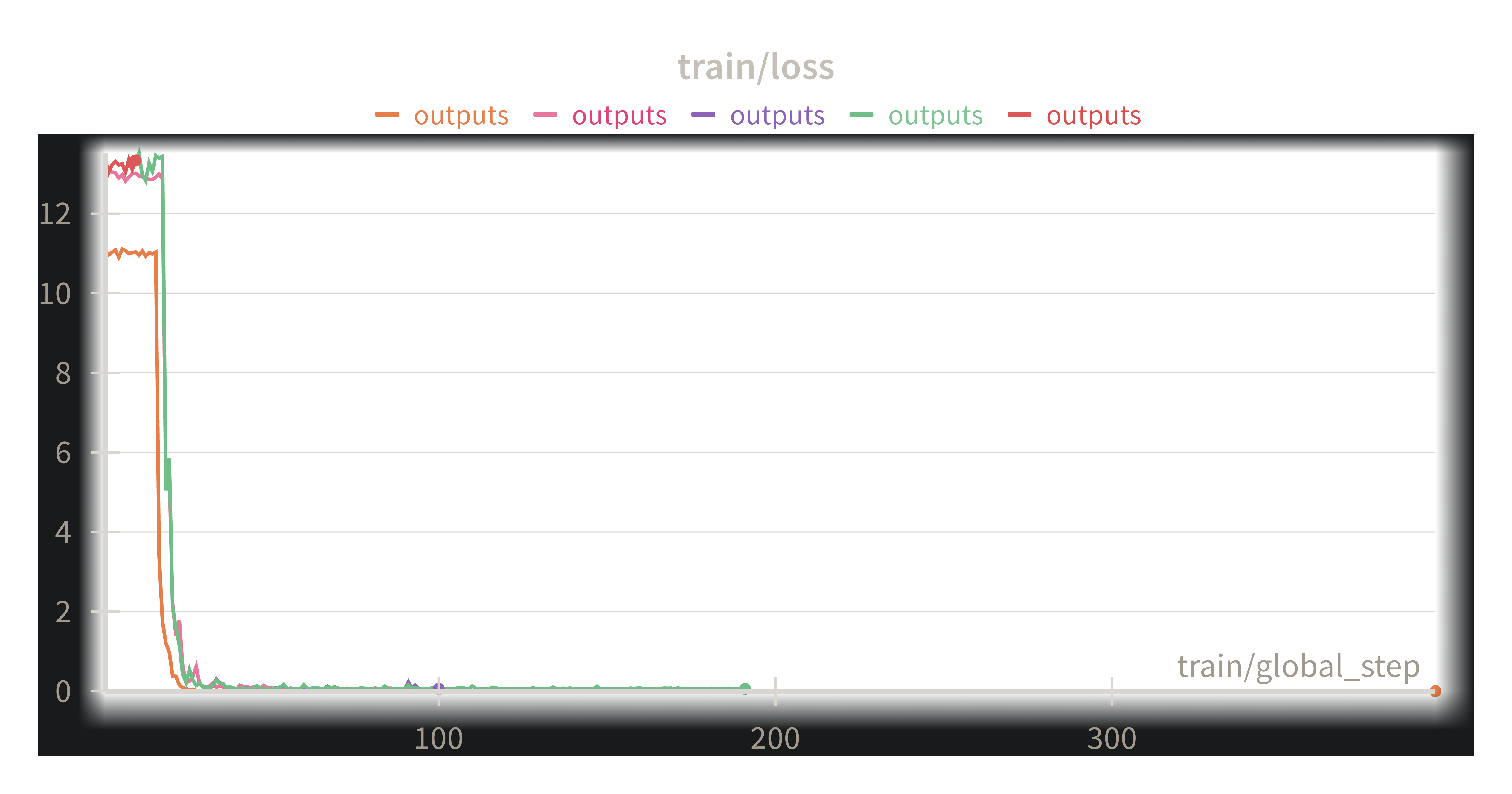
Armed with this knowledge, I rebuilt the training pipeline the "Unsloth Way." The result was a training run that completed 18 epochs in under an hour on a free Kaggle GPU. The loss curve was a thing of beauty, plummeting from ~13.0 to absolute zero. We had a trained, expert model.
But having a model wasn't enough. Was it the best model? The best learning rate? The right capacity? A working model is one thing; an optimal one is another. This led me to the next, crucial phase: a data-driven hunt for the perfect configuration.
I unleashed a Weights & Biases Bayesian Sweep, an automated agent that would intelligently test five different combinations of hyperparameters. This wasn't just training; it was a rigorous, automated tournament to find a champion. And to ensure the victory was real, I built a final validation step into the pipeline: after each training run, the model would be tested against a held-out set of real-world images.
The question that kept me up at night—would it actually work on new images?—was about to be answered.
The answer was a resounding, beautiful yes. As the runs completed, the results filled my screen. One after another, the models trained under different configurations were put to the test. The verdict was unanimous. On our held-out validation set, run after run achieved 100% accuracy.
This was the true breakthrough. The validation wasn't just a number; it was proof. Proof that the data was right, the prompt engineering was right, and the struggle had led to something genuinely powerful. We now had not just one, but a collection of champion models, forged in a crucible of experimentation and validated by empirical data.
| Run Name | Learning Rate | LoRA Rank (r) | Epochs | Final train/loss |
Validation Accuracy |
|---|---|---|---|---|---|
| comic-sweep-1 | 8.34e-06 | 16 | 15 | 0.0003 | 100% |
| stilted-sweep-2 | 1.57e-05 | 32 | 20 | 0.0001 | 100% |
| unique-sweep-3 | 1.16e-05 | 32 | 20 | 0.0001 | 100% |
| vague-sweep-4 | 1.07e-04 | 32 | 20 | 0.0001 | 100% |
| amber-sweep-5 | 4.45e-04 | 32 | 20 | 0.0001 | 100% |
The Third Hurdle: The Wall of Memory and the ONNX Frontier
With a champion model in hand, proven to be 100% accurate on a real-world dataset, I faced the final frontier: deploying it to a device that could fit in a farmer's pocket.
Before turning to MediaPipe, the most logical path seemed to be the universal standard: ONNX (Open Neural Network Exchange). The plan was to convert my fine-tuned PyTorch model to ONNX, a format that acts as a universal translator between deep learning frameworks. From there, it could potentially be converted to any on-device format.
This was not a simple task. The brand-new, multimodal architecture of Gemma 3N required a deep dive into the Hugging Face optimum library. I couldn't just use a pre-built script; I had to engineer a custom solution. This involved writing a new ONNX configuration to map the model's complex inputs (text, images, and past states) and, most critically, creating a CustomDummyTextInputGenerator. This component was essential to trace the model's execution path by injecting the special "image token" (ID 262145), perfectly simulating how the model operates.
The script was a testament to the engineering required to work at this level. I launched it on my MacBook, a machine I thought was powerful enough for the task. The 3-billion-parameter model loaded, the fans spun up, and I watched the system's memory usage climb... 8GB... 12GB... 16GB... and then, silence.
The terminal simply read: Killed: 9.
There was no Python error to debug, no cryptic message to decipher. It was a brutal, final verdict from the macOS kernel. My machine had run out of memory. The process of converting this "on-device" model was too massive to be handled by my on-device hardware. It was a painful irony and a dead end. I had hit a physical wall.
The Final Hurdle: The On-Device Frontier
With the ONNX path blocked by hardware limitations, I turned to my last, best hope: MediaPipe, Google's own framework for building on-device ML solutions. The logic was sound—use the official tool from the creators of Gemma to get the most direct and optimized conversion. It felt like the key, the designed-for-purpose solution that would finally crack the problem open.
My goal was simple: add support for the "Gemma 3N" model type to MediaPipe's conversion script. This required modifying a single line of Python code in the safetensors_converter.py file. But to make that change live, I couldn't just use the pre-installed library; I had to rebuild the entire MediaPipe framework from source.
This began a multi-day odyssey, a trial by fire that revealed the immense complexity hidden behind the "simple" tools we often take for granted. The build process was a cascade of interlocking failures:
- The
zlibConflict: The first error was a clash between an ancient, bundled compression library and my modern Mac's developer tools. - The OpenCV Hydra: The build then failed spectacularly, unable to find the OpenCV computer vision library. The script insisted on building its own private, outdated copy, which in turn was missing its own dependencies (
libjpeg,libIlmImf,dc1394) that no longer exist on a modern system. - The Final Override: After days of failed attempts to guide the build system—editing
WORKSPACEfiles, build configurations, and passing custom flags that were silently ignored—the only solution was a forceful one. I had to manually edit the centralsetup.pybuild script and permanently delete the line of code that instructed the system to build OpenCV from source. This finally forced it to use the modern, pre-installed libraries on my machine.
After an epic struggle involving over 4,600 compilation steps, the build succeeded. I had a custom version of MediaPipe, modified with my own two hands to recognize the Gemma 3N model. The path was clear. I wrote the final conversion script, pointing it to my fine-tuned model and my custom build of the framework. The last wall was about to fall.
Where We Are Now: At the Edge of the Final Frontier
Today, the landscape of this project has been transformed. I have a powerful, fine-tuned "Maize Expert" model, validated with 100% accuracy on a real-world dataset. I have a robust, automated training and evaluation pipeline that can reliably produce these expert models. And critically, I have a custom-built version of the MediaPipe framework, modified with my own two hands to recognize and handle the specific architecture of Gemma 3N.
The final gauntlet remains the on-device conversion. The errors I face are no longer about my training code or my data; they are deep, cryptic messages from the very core of the conversion logic itself.
It hurts. To fight through the entire ecosystem, to tame the beast of a C++ build system, to modify the framework at the source code level, only to be blocked by the final step is a special kind of frustration.
But it is not a defeat. It is a diagnosis. The pip install was not the final boss; it was merely the guardian of the gate. We are now inside the final room, facing the ultimate challenge.
This project has evolved. It is no longer just about building an app. It is about pushing a brand-new, cutting-edge model architecture through a brand-new, cutting-edge conversion pipeline and finding the exact points where it fractures. We are at the final frontier, mapping the uncharted territory between a trained PyTorch model and a deployable on-device artifact.
My passion to see this through has only been forged stronger by the heat of this battle. The next steps are crystal clear:
- Isolate and Reproduce: The current errors are complex. I will create a minimal, reproducible example to isolate the exact operation that is failing during the conversion. This is the key to filing a precise, actionable bug report with the MediaPipe and
ai-edge-torchdevelopers. - Showcase the Power: While the conversion is debugged, I will not wait. I will build an interactive Gradio demo to prove the incredible capability of the trained model. This will be a powerful showcase of what is possible and will serve as the centerpiece of my submission.
- Engage the Experts: I will go back to the source. I will re-engage the developers of the conversion tools, not with a vague complaint, but with a full, reproducible case study and a clear diagnosis of the problem. This transforms me from a user into a contributor.
- Find a Way: I will not stop. Whether it's through a patch from the official developers, by exploring alternative conversion paths like
GGUFnow that I understand the tooling landscape, or by diving even deeper into the converter's source code, I will find a path to get this model into a farmer's hands.
The problem is too important. The need is too great. And after this journey, I know we are too close to give up now. Let's go.
For a deep dive into our initial stability experiments, see Article 1: Establishing a Baseline. For a full analysis of our hyperparameter sweep and validation, see Article 2: From Sweep to Success. For a wholesome preview into our Privacy Aware RAG, see Article 3: Engineering Aura-Mind's Secure Knowledge Fortress

Log in or sign up for Devpost to join the conversation.