-
-
home page
-
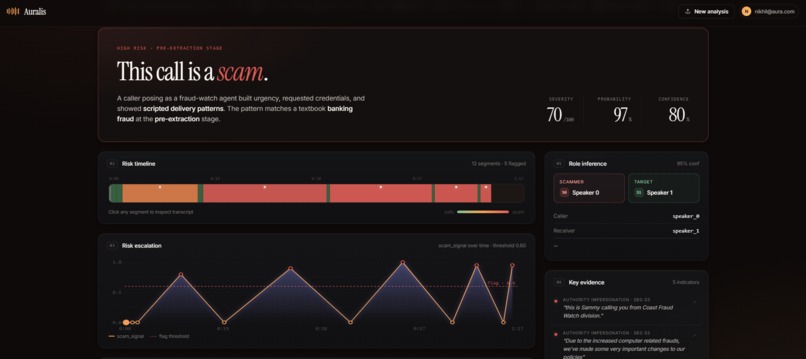
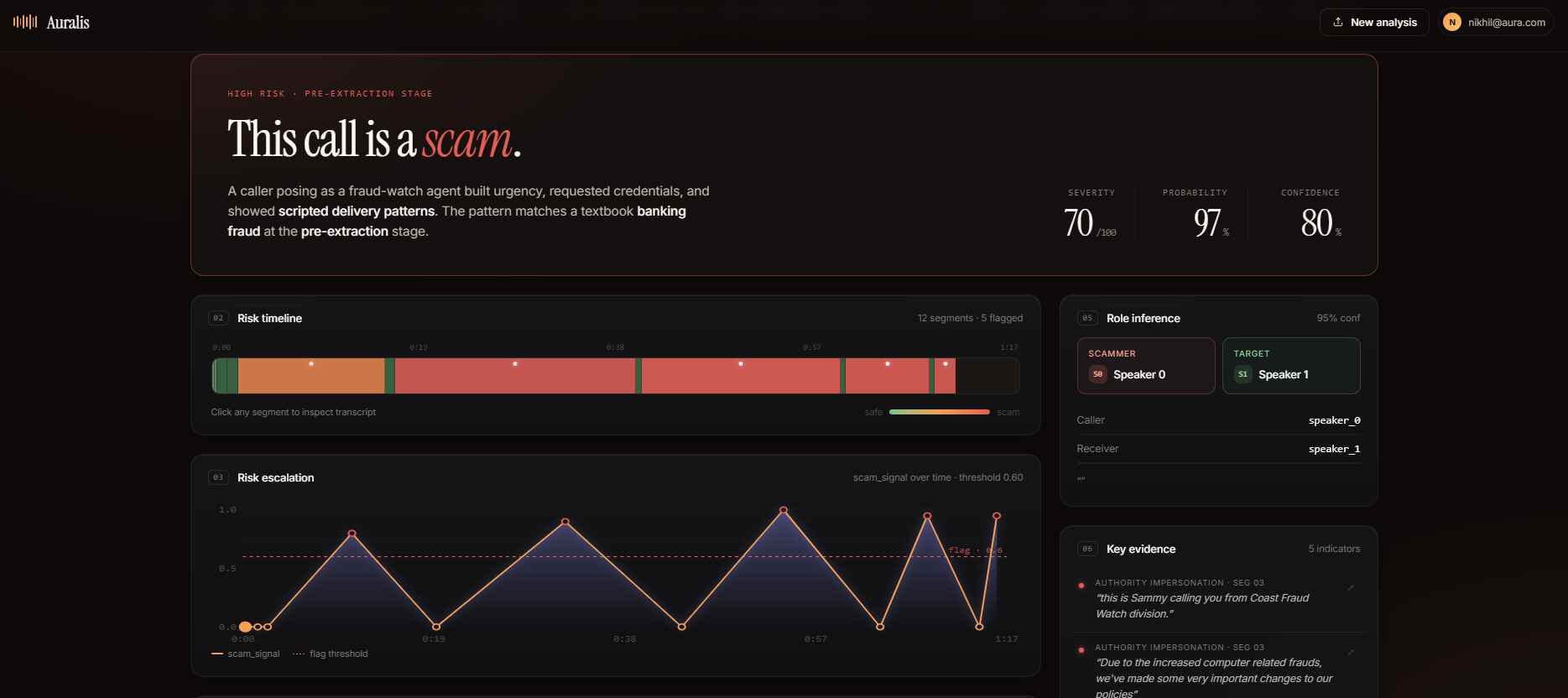
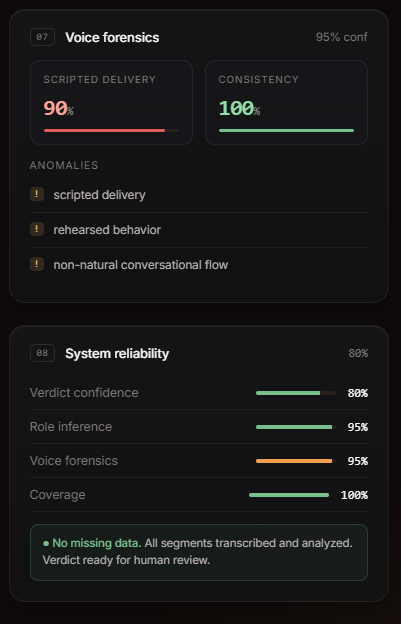
dashboard
-
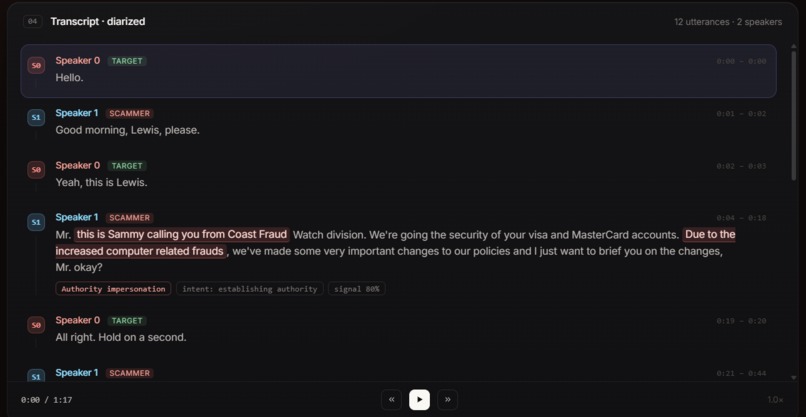
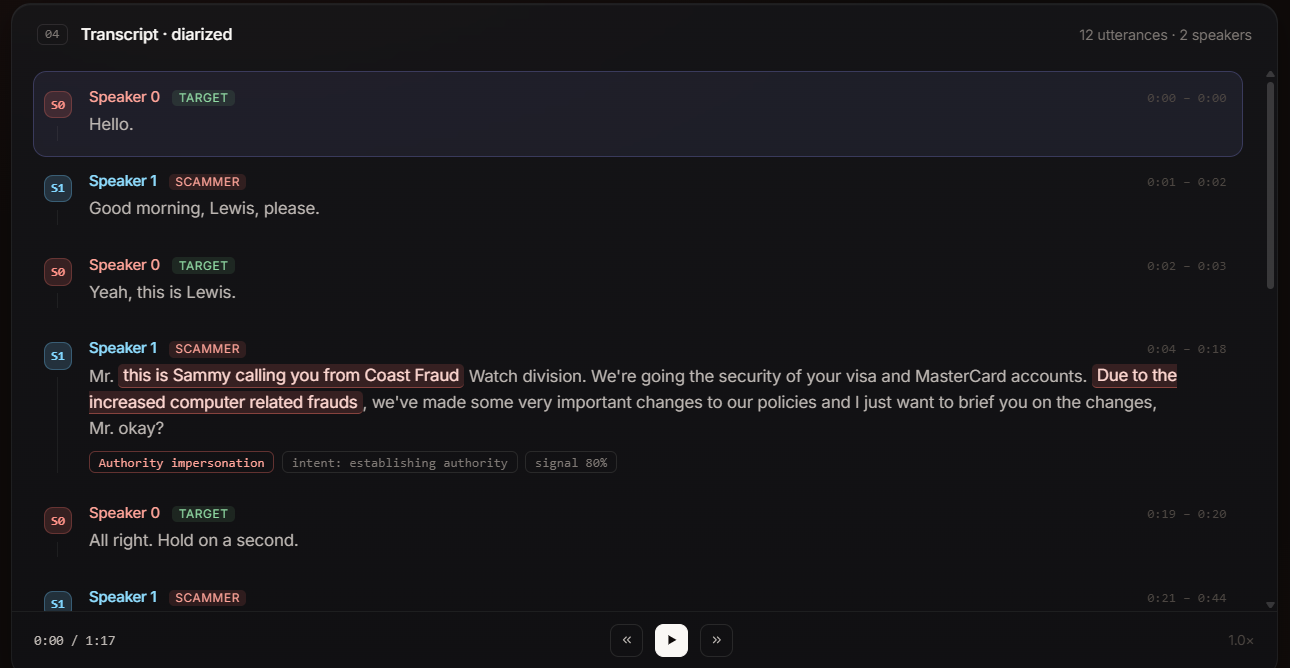
transcript of the scam call
-
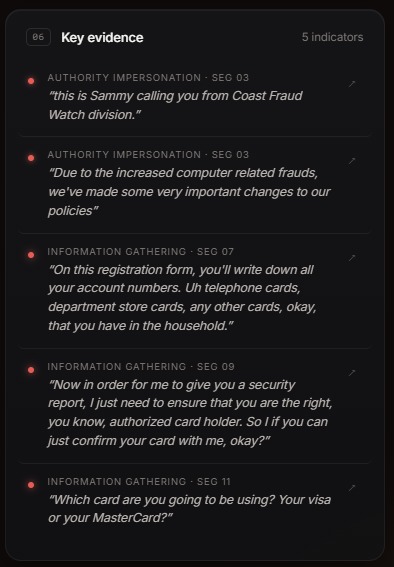
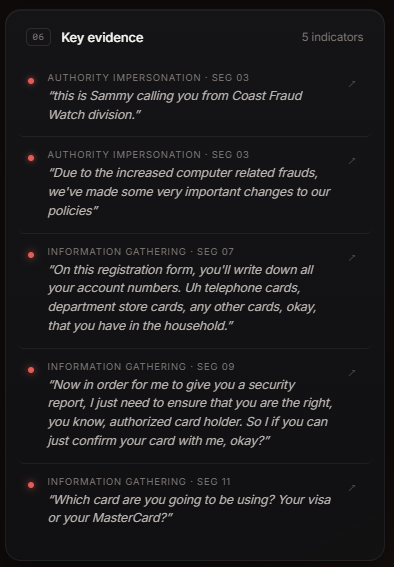
evidences of why it is a scam call
-
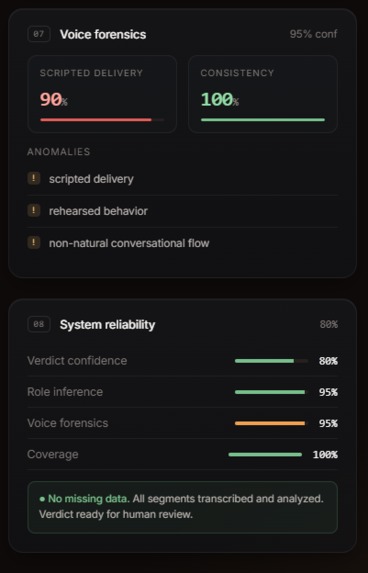
additional flags
Inspiration
We started with a simple frustration.
Most scam detection tools either miss obvious scams or return a score with no explanation. You might get a 0.87 probability, but that doesn’t tell you what actually happened in the call.
When we listened to real scam recordings, it became obvious that scams are not random. They follow patterns. There is structure, escalation, and intent behind every step.
We wanted to build something that captures that structure.
What we built
Auralis is a system that takes a raw phone call and reconstructs it as a sequence of behaviors.
Instead of asking “is this a scam?”, we ask:
- who is driving the conversation
- when does risk increase
- what tactics are being used
- what evidence supports the conclusion
We built a pipeline that combines transcription, diarization, behavioral analysis, and a structured fusion layer to produce a final result that is both accurate and interpretable.
How we built it
We broke the problem into stages and each of us focused on a part, while making sure everything fit together cleanly.
Nikhil handled the core pipeline. He built the transcription and diarization system with silence-aware chunking so long calls stay stable, and made sure timestamps align correctly end to end.
Ojasvi and Praneel worked on the intelligence layer. He built the segment-level analysis to detect intent and scam signals across the conversation, and contributed to role inference so the system can tell who is driving the call and who is being targeted.
Praneel built the frontend and overall experience. He designed the dashboard so everything from the backend is clearly visible through the timeline, transcript, and evidence panels, making the output easy to understand.
Finally, we combined everything using a fusion layer. Instead of relying on one model output, we merge multiple signals to produce a more stable and trustworthy result.
Overall, the focus was to build something that not only works, but is clear, reliable, and actually useful.
Challenges we faced
The biggest challenge was consistency.
At first, timestamps drifted and the timeline didn’t match the actual audio. We fixed this by enforcing chunk-local timestamps and applying offsets carefully.
Another challenge was model bias. The model tended to output similar probabilities for different calls. We addressed this by introducing deterministic penalties and a weighted fusion system.
Diarization was also tricky. Without proper chunking and alignment, speaker switching became noisy. We improved this by stabilizing segment boundaries and preparing for global speaker clustering.
What we learned
We learned that accuracy alone is not enough.
A system can be correct and still be unusable if it cannot explain itself.
We also learned that combining simple deterministic logic with model outputs leads to much more stable results than relying on a single model.
Most importantly, we learned that building something people trust requires showing the reasoning, not hiding it.
What’s next
We are currently running a structured evaluation on real and scam calls with manual annotations.
Next steps include improving speaker consistency across chunks, adding real-time processing, and expanding the dataset.
The goal is to move from a strong prototype to something that can be deployed in real-world scenarios.





Log in or sign up for Devpost to join the conversation.