-
-

-

AuraLamp
-
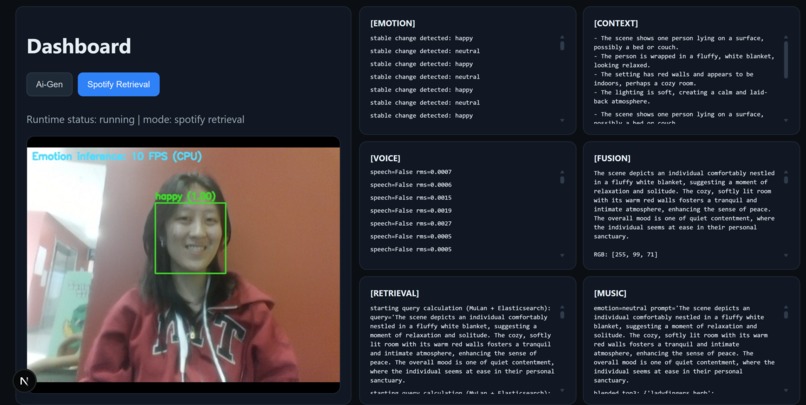
Facial + Voice/Music Analysis Dashboard
-
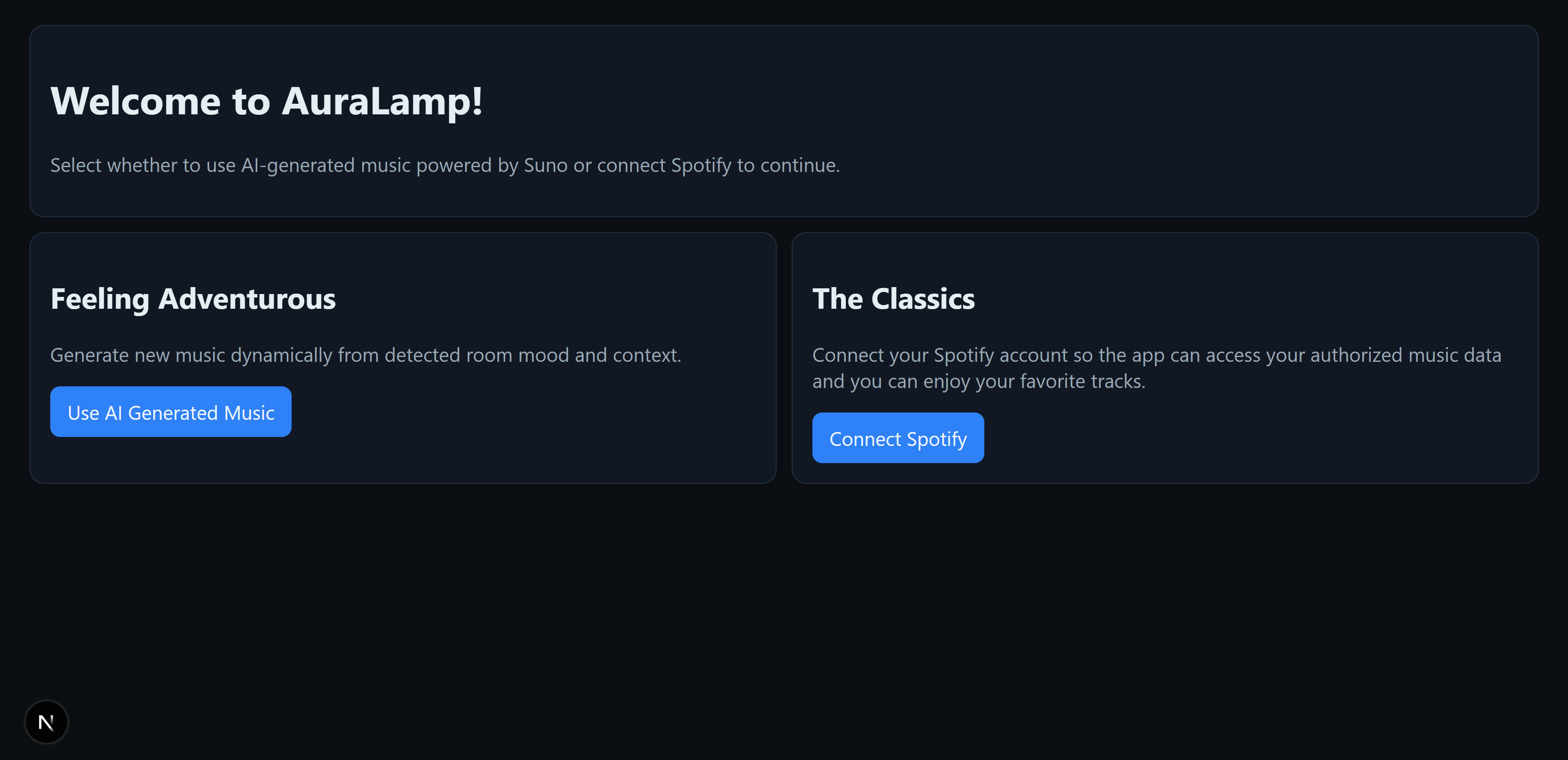
AuraLamp Landing Page
-
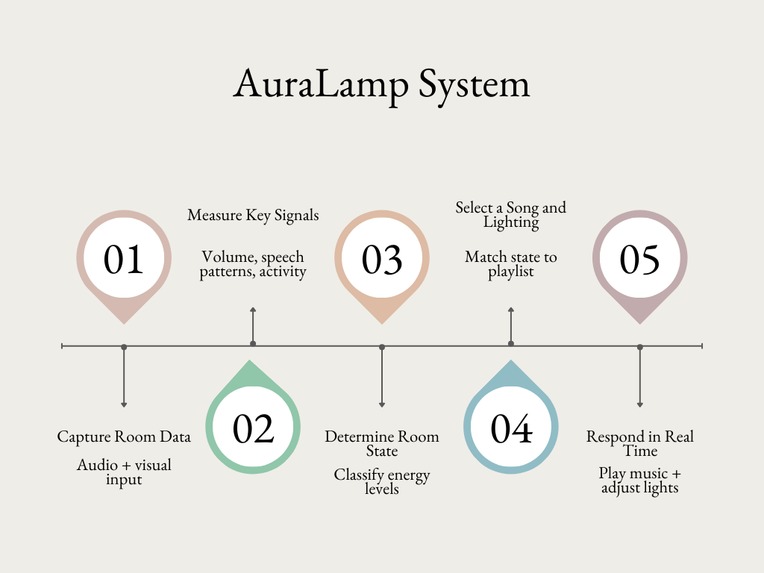
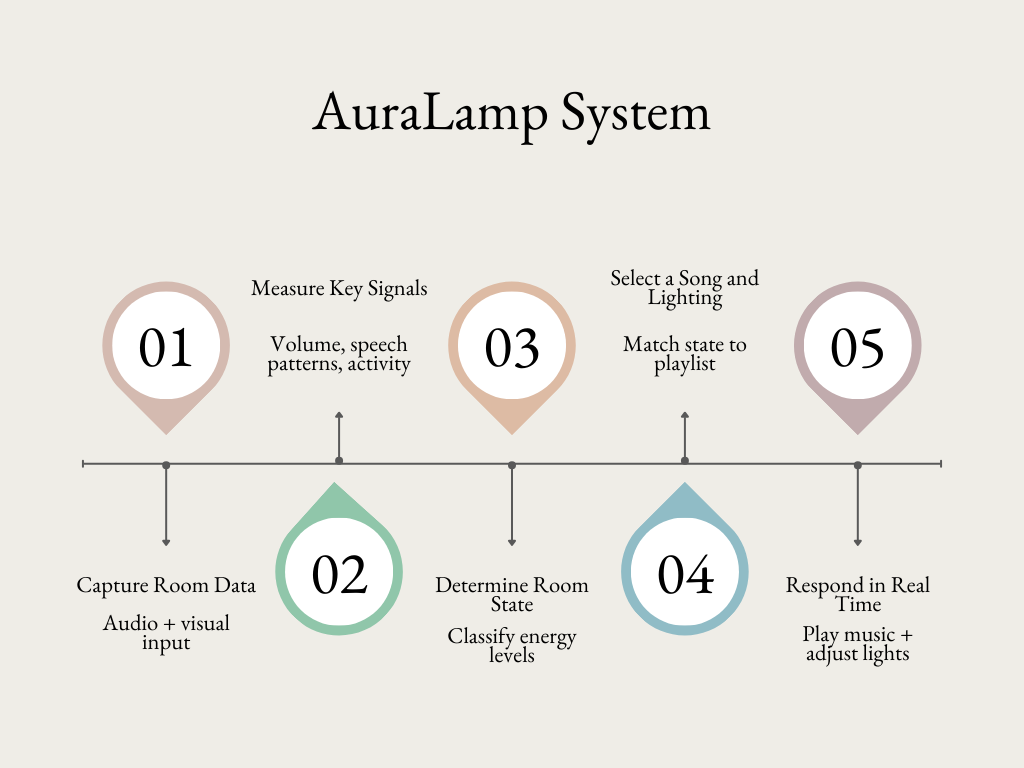
End-to-end flow: from room input to response


Inspiration
We were inspired by the idea of ambient technology that responds quietly and naturally without requiring constant input. AuraLamp explores how shared spaces can adapt to the people in them, automatically adjusting the soundtrack to match the room’s energy.
What it does
AuraLamp is an ambient lamp that analyzes live audio and visual cues to estimate a room’s energy level. Using microphone input and visual activity detection, the system categorizes the environment into energy states such as calm, focused, or lively. It then selects a song from a curated playlist that best matches the moment. Instead of manually choosing music, AuraLamp responds to the room in real time and sets the tone automatically.
How We Built It
Front End
- Built with
Next.js+TypeScriptfor a responsive web interface and fast iteration. - Dashboard shows a live camera stream plus categorized runtime logs (
[EMOTION],[CONTEXT],[FUSION],[VOICE],[RETRIEVAL],[MUSIC]) to make system behavior transparent. - Added a live toggle between
SunoandSpotify Retrievalmodes so users can switch music strategy without restarting the sensing pipeline.
Back End
- Built with
FastAPI+Uvicornfor API routes, orchestration, and runtime control. - Implemented Spotify OAuth and session-based auth for account connection.
- Added runtime endpoints for start/stop, mode switching, logs, and MJPEG camera streaming.
- Integrated Elasticsearch sync for lyrics at runtime startup (upsert + stale-delete) to keep retrieval data current.
CV / FER (Facial Emotion Recognition)
- Used
OpenCVfor real-time frame capture and stream handling. - Used
MediaPipeface detection for practical, low-latency face localization. - Used a Hugging Face FER model (e.g.,
trpakov/vit-face-expression) on CPU for emotion classification. - Stabilized emotion triggers over time to avoid noisy emotion flicker causing unnecessary music changes.
MER (Music Emotion Retrieval / Matching)
- Implemented dual music paths:
Suno mode: generate instrumental tracks from fused scene context using Suno’s TreeHacks API and begin playback as soon as status reachesstreaming.Spotify Retrieval mode: use local song files and rank candidates with MuLan audio-text similarity blended with Elasticsearch lyric relevance.- Used
MuLan(OpenMuQ/MuQ-MuLan-large) for semantic audio-text alignment and cached embeddings on disk to avoid recomputation. - Used
Elasticsearchfor lyric indexing and semantic text matching, then blended with MuLan scores for final selection.
Voice Analysis
- Captured mic audio using
sounddevice. - Extract vocal features using librosa library to estimate mood and emotion from pitch, words per minute, volume
- Extract content of speech using Whisper OpenAI API for transcription
- Use spaCy NLP to extract key topics and infer the mood of speech from the content
- Returns an object with information on speech features and content, along with a vector of probable emotions.
Context Shot
- To contextualize the emotions detected from the other input, we also take a “context shot”.
- We pass in a static image of the room to ChatGPT to describe the location and the occasion.
- We update this shot relatively infrequently to reduce redundant calls.
Sensor Fusion
- Combined speech features (mood, transcript emotion, keywords/topics) with face and room context in the fusion layer, amplifying and dampening emotions from context with information collected from the vocal features.
- Pass each of the three outputs of the voice analysis, facial analysis, and context shot to ChatGPT to produce a 5 sentence description of the room’s atmosphere and mood.
By continuously updating these inputs, the system selects music that reflects the current atmosphere of the space.
Hardware
- Used ‘Arduino Uno’ to connect mood lighting inputs to an LED array.
- Created a 3x3 array of RGB LED’s to control light (instead of a color changing bulb, which wasn’t available to us).
- Used arduino IDE to control lighting inputs for each mood using RGB color setting for each mood.
- Designed and 3D printed a stylish lamp cover in “onshape” to diffuse the LEDs and make the light more aesthetically pleasing.
Challenges we ran into
Our biggest challenge was scope. We initially planned to build a more complex adaptive music system, but quickly realized that creating a stable, real-time hardware prototype within 36 hours required focus.
We intentionally reduced scope to a curated playlist to ensure reliability and a smooth demo. Integrating hardware inputs with live processing also introduced latency and synchronization issues that required careful debugging. Optimization and parallelization was especially important, as we loaded our models and song data all on CPU. Though transferring to GPU would speed things up, we also optimized our code by doing expensive work only when needed and then reusing results. Voice and retrieval models are lazy-loaded once, MuLan song embeddings and downloaded preview audio are cached on disk to avoid recomputation/network calls, and the server reuses a single embedder and Elasticsearch client instance. It also skips redundant indexing when a user’s index already exists, deduplicates tracks across playlists so each track is embedded once, and ignores repeated identical emotion events to prevent duplicate processing.
Since we did not have access to a color changing LED, we had to create a 3 x 3 array of individual red, blue, and green LEDs to mimic this functionality. To make the lighting more uniform, we diffused it using fabric and the 3D printed lamp shade.
Accomplishments that we're proud of
We are proud that we built a functioning hardware-software prototype within a limited timeframe. All four of us are first-time hackers, and this was our first experience integrating live hardware sensing with real-time decision logic. Successfully delivering a working system while adapting our scope was a major milestone for our team.
What we learned
This project taught us how to turn an ambitious idea into a focused, achievable prototype.
We learned how to:
- Break down abstract concepts like “room energy” into measurable signals
- Debug hardware-software integration under time pressure
- Communicate and collaborate effectively across different experience levels
Most importantly, we learned that clarity and execution matter more than complexity.
What's next for AuraLamp
- Improve the accuracy and nuance of our energy classification system
- Expand beyond a fixed playlist and incorporate adaptive, personalized music selection
- Introduce mood-aware responses, such as calming music during stressful moments or ambient sounds during rest
- Explore subtle support features for studying, social settings, and sleep environments
- Refine the lamp’s physical design to incorporate a speaker, microphone, and raspberry pi to work remotely without a computer.
References
Research suggests that music can meaningfully influence anxiety and emotional state, supporting our vision of AuraLamp as a system that responds thoughtfully to how people feel in a space.
- Sung, H. C., et al. “The Effects of Calming Music Listening Intervention on Anxiety-Related Outcomes in College Nursing Students under Stress.” International Journal of Evidence-Based Healthcare, 2012.
Built With
- claude
- elasticsearch
- fastapi
- github
- huggingface
- mediapipe
- mulan
- natural-language-processing
- next.js
- openai
- opencv
- python
- spacy
- spotify
- suno
- typescript
- uvicorn
- whisper





Log in or sign up for Devpost to join the conversation.