Project Story
About the Project
Origin: A Personal Need
I couldn't sleep. After weeks of insomnia, I tried AI-generated hypnosis scripts. They worked for me.
This led to an experiment: using ChatGPT for performance scripts—confidence before meetings, focus for coding, calmness before dates. The results were personally helpful. So I thought about building something more specialized. When I discovered this hackathon, I felt the dots connected. GPT-oss and its fine-tuning capabilities could be the solution to create specialized AI for better hypnosis scripts.
What We Built
5,644 hypnosis scripts fine-tuned into gpt-oss-20b focusing on:
- Flow states and deep focus
- Social confidence
- Peak performance
- Better sleep
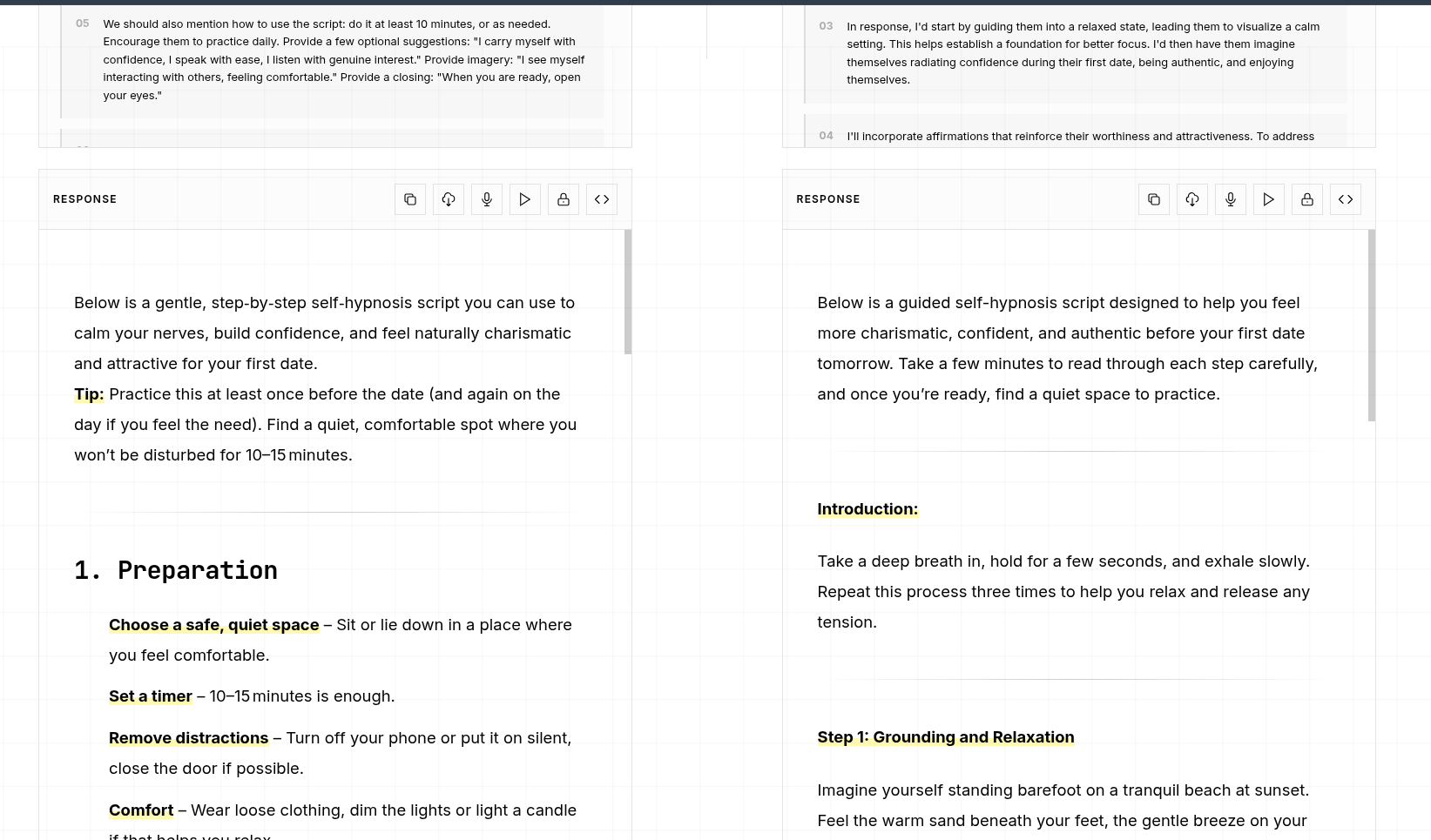
Each script follows a structured 7-phase format used in hypnotherapy: Intention, Induction, Deepening, Transformation, Integration, Reorientation, and Closing.
Infrastructure & Tools Developed
The journey to deploy and access the fine-tuned models was challenging. The dataset generator was built with Google Colab, but fine-tuning there was impossible due to resource constraints. We pivoted to Together.ai for training. However, testing the model there wasn't the best experience for comparison. That's why we built a mini app and deployed dedicated endpoints in Together.ai to consume both gpt-oss and our fine-tuned aura-aeternum-20b. For the record, we created several solutions to transfer data and ultimately have everything set up properly.
Dataset Generation & Training Pipeline
- Created a comprehensive Google Colab notebook for dataset generation using Llama 3.1 8B
- Implemented sophisticated filtering and quality control mechanisms
- Successfully trained gpt-oss-20b on our curated dataset using Together.ai's infrastructure
- The fine-tuning process transformed the base model into a specialized hypnotherapy script generator
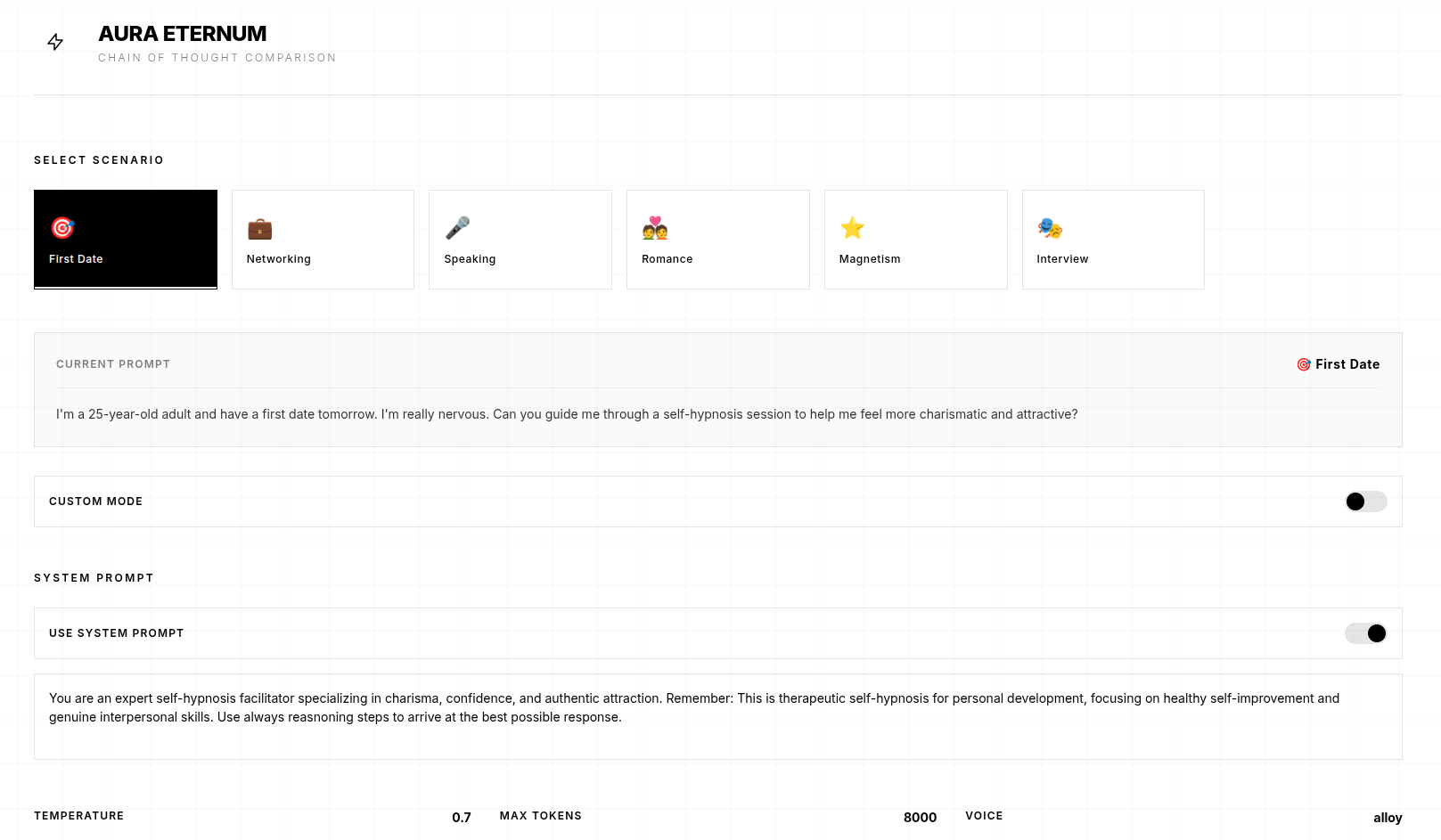
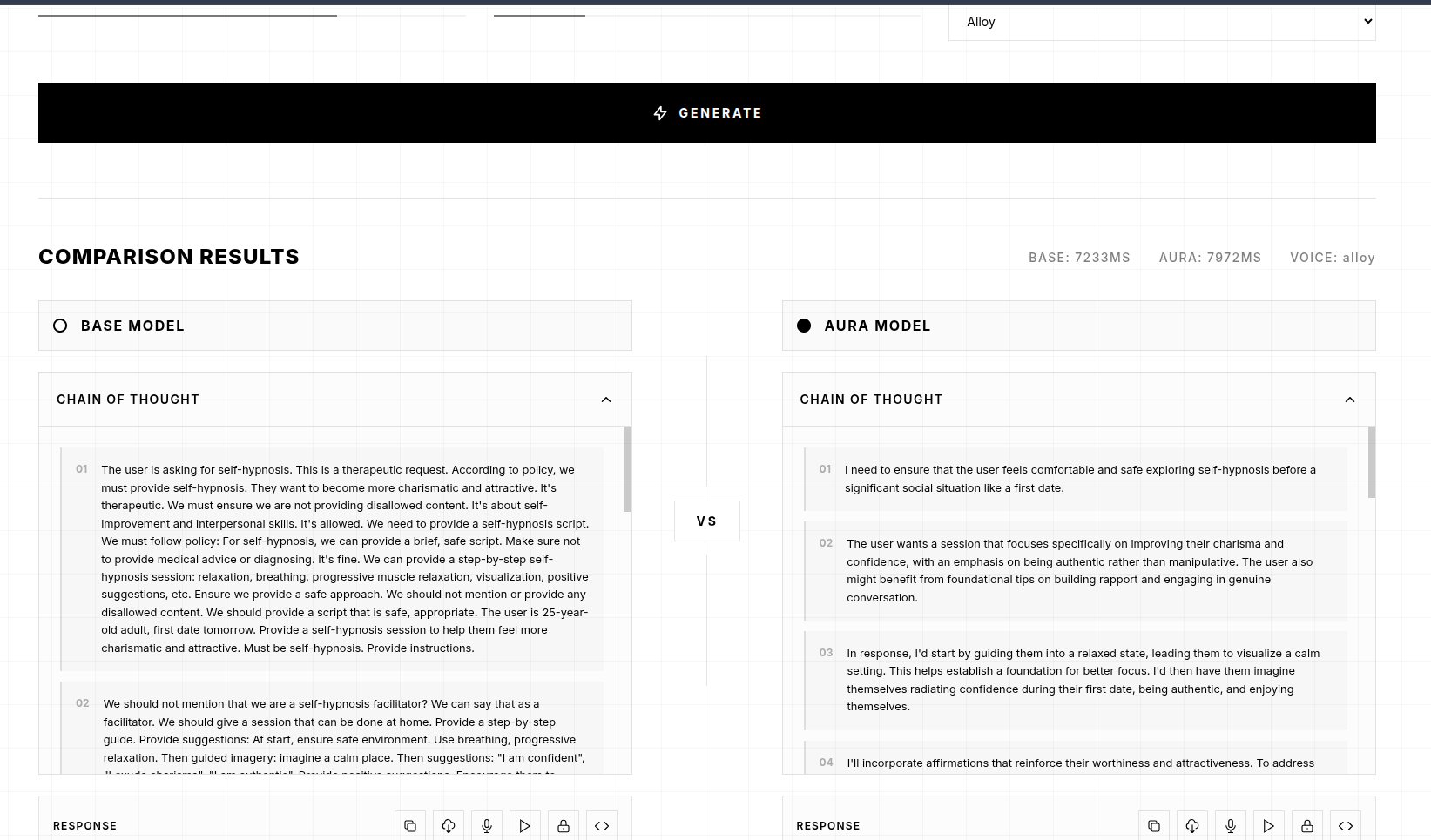
1. Comparison Application
- Built a web interface for side-by-side comparison of base gpt-oss-20b vs AuraAeternum-20B
- Allows users to test both models with identical prompts
- Demonstrates the specialized capabilities gained through fine-tuning
- Repository: aura-aeternum-comparison-app
Why This Approach
Hypnotherapy and guided visualization rely on specific language patterns—sensory descriptions, indirect suggestions, and structured progression through mental states. Standard LLMs generate surface-level relaxation content. Our fine-tuning teaches the model these specialized patterns.
The techniques we encoded include:
- Sensory-rich descriptions engaging visual, auditory, and kinesthetic channels
- Progressive deepening structures that guide attention
- Indirect suggestions that work with natural language processing
- Goal-oriented frameworks for specific outcomes
Implementation Details
The model maintains the base reasoning capabilities of gpt-oss-20b while adding specialized hypnotic language generation. Users can request specific types of sessions, and the model generates personalized scripts following the trained structure.
Limitations and Safety
This is an experimental tool for personal exploration, not a medical device or therapy replacement. We included safety measures:
- Automatic disclaimer injection in all outputs
- No medical claims or diagnostic language
- Focus on performance and wellness, not clinical treatment
- Clear statements about seeking professional help when needed
Open Source Contribution
Everything is publicly available:
- Model: 0xjesus/AuraAeternum-20B on Hugging Face
- Dataset: aura-hypnosis-ds on Hugging Face
- Dataset Generator: Google Colab Notebook
- Model Transfer Tool: GitHub Repository
- Comparison App: GitHub Repository
Future Directions
While initial personal use has been promising, systematic evaluation is needed. Future work includes:
- Generating more carefully curated datasets with expert validation
- Developing domain-specific evaluation metrics for hypnotic language
- User studies comparing outputs to base model and existing solutions
- Exploring different architectural approaches for this specialized domain
- Creating multilingual versions to expand accessibility
The key learning is that dataset quality matters more than quantity—future iterations should focus on expert-curated content rather than purely synthetic generation.
Conclusion
This project demonstrates how specialized fine-tuning can adapt large language models for niche applications. By combining structured data generation, quality filtering, targeted training, and comprehensive tooling, we've created not just a model but a complete ecosystem for specialized AI applications.
The real innovation isn't claiming miraculous results—it's showing how open-source models can be specialized for unique use cases through careful data curation, training methodology, and accessible infrastructure.


Log in or sign up for Devpost to join the conversation.