Inspiration
A.U.R.A. grew from a simple idea: modern assistants are too chat-centric and brittle for real automation. Instead of treating the app as a conversation-only UI, we wanted a goal-first orchestrator — a system where a single natural-language goal (e.g. “Movie night”, “Focus mode”, “Prepare for bed”) becomes a structured, executable plan that coordinates devices, routines, and services.
We also wanted a hackathon-friendly architecture: something that showcases cutting-edge AI + a robust, type-safe backend — but that still works perfectly in an offline demo. That led to the combination of:
- Flutter for a polished, cross-platform frontend (web & desktop demo targets),
- Riverpod for clear, testable state flows,
- Serverpod for Dart-first, type-safe backend bindings (optional so judges can demo without hosting),
- and an AI-provider abstraction so the same orchestration logic works with OpenAI, Anthropic, Gemini, or a provider.
What it does
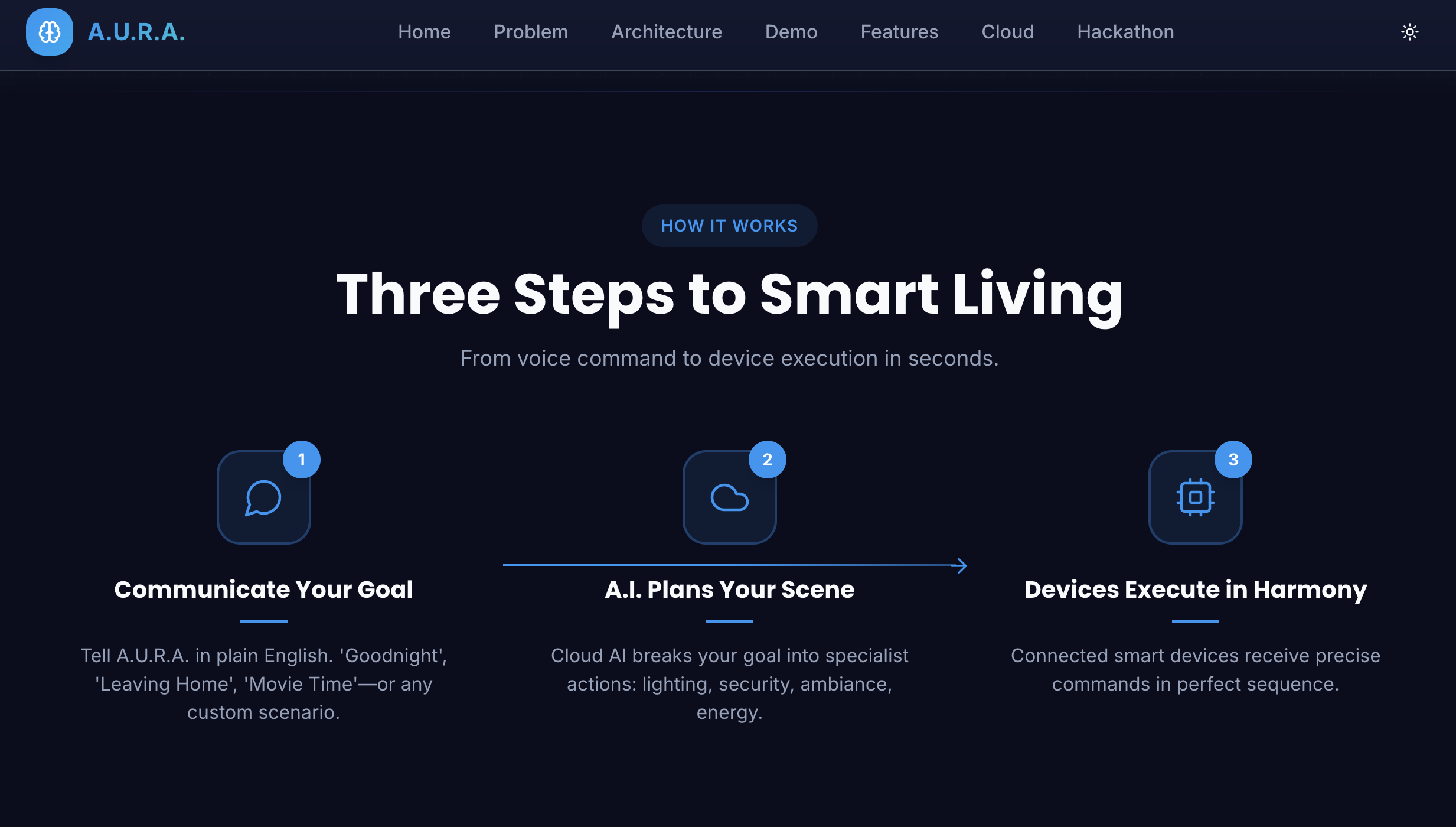
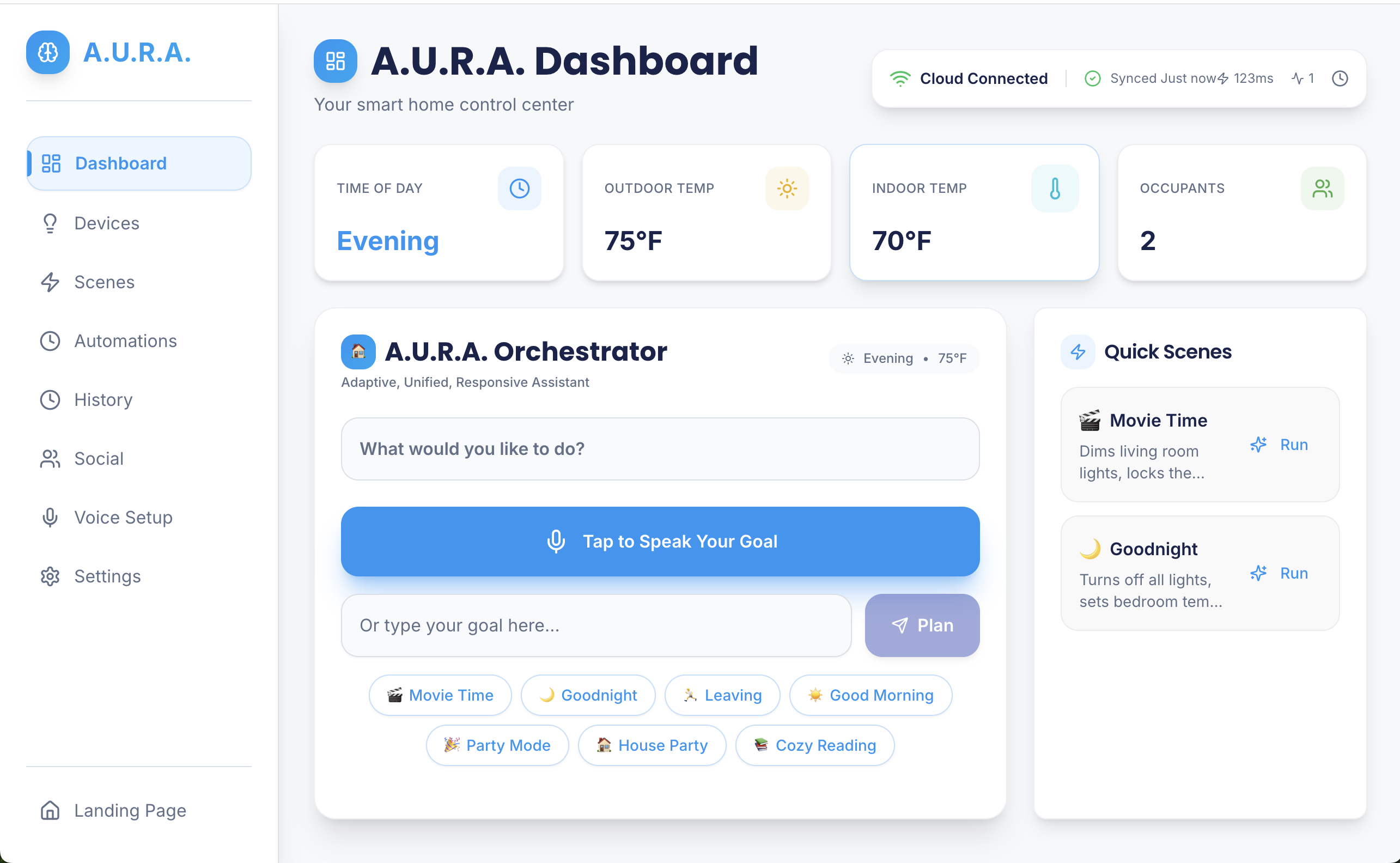
A.U.R.A. accepts a single goal from the user and resolves it into an actionable plan that can do things like:
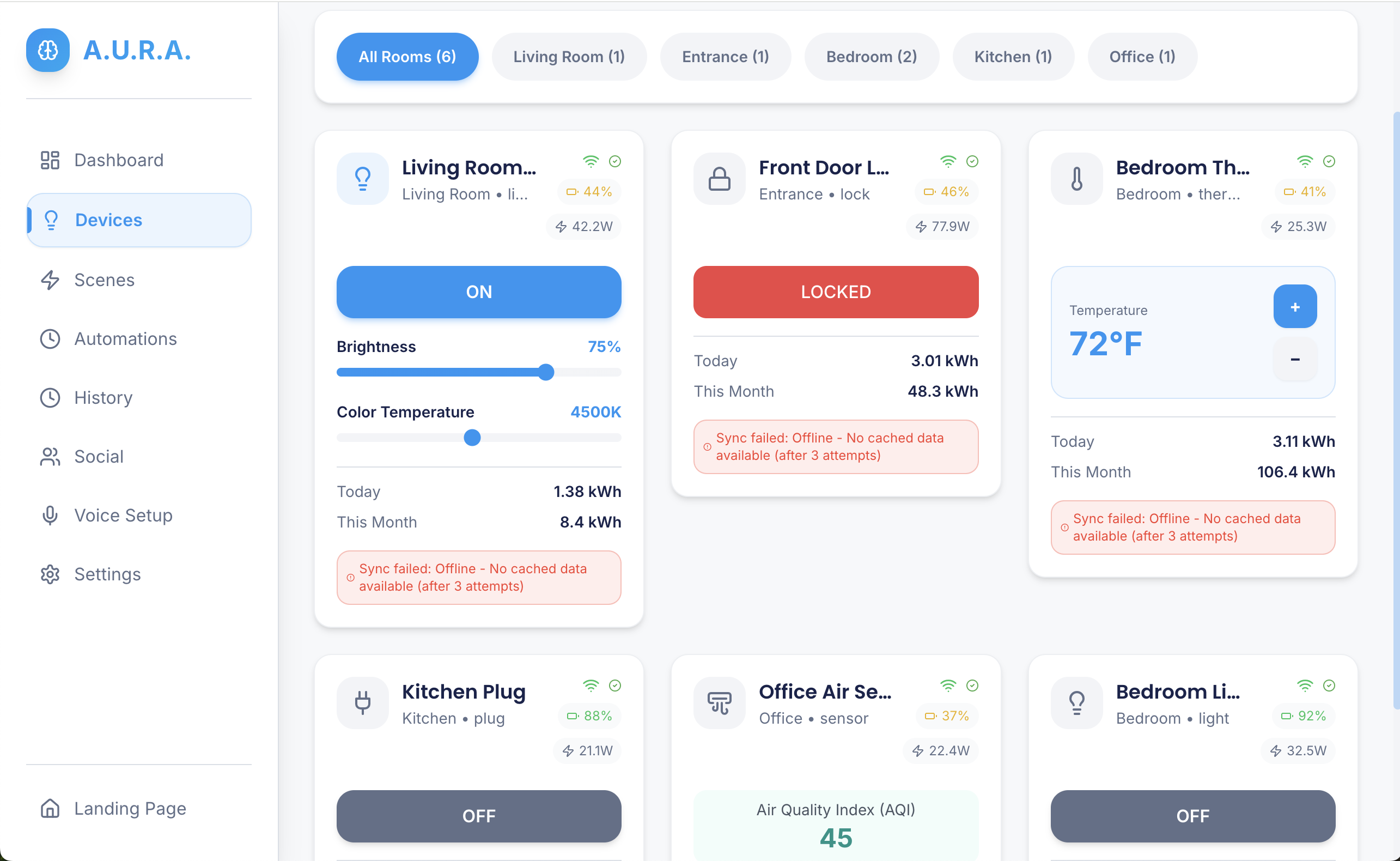
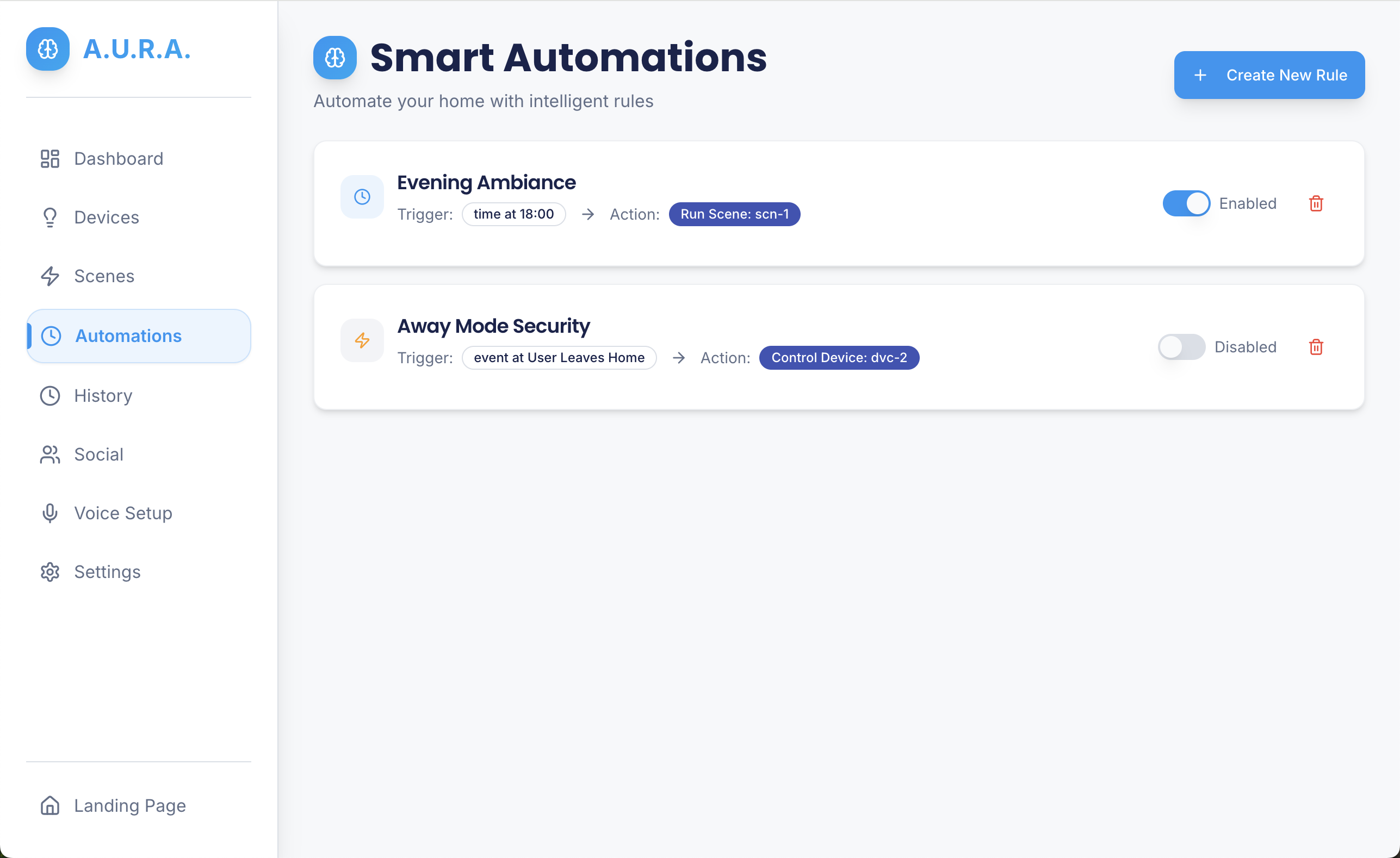
- discover and manage devices (simulated or real),
- run or compose routines (e.g., dim lights, change thermostat, launch playlist),
- persist state to a backend (typed Serverpod RPCs),
- fall back to a provider when external services are unavailable,
- and expose a simple routine editor for reusing complex automations.

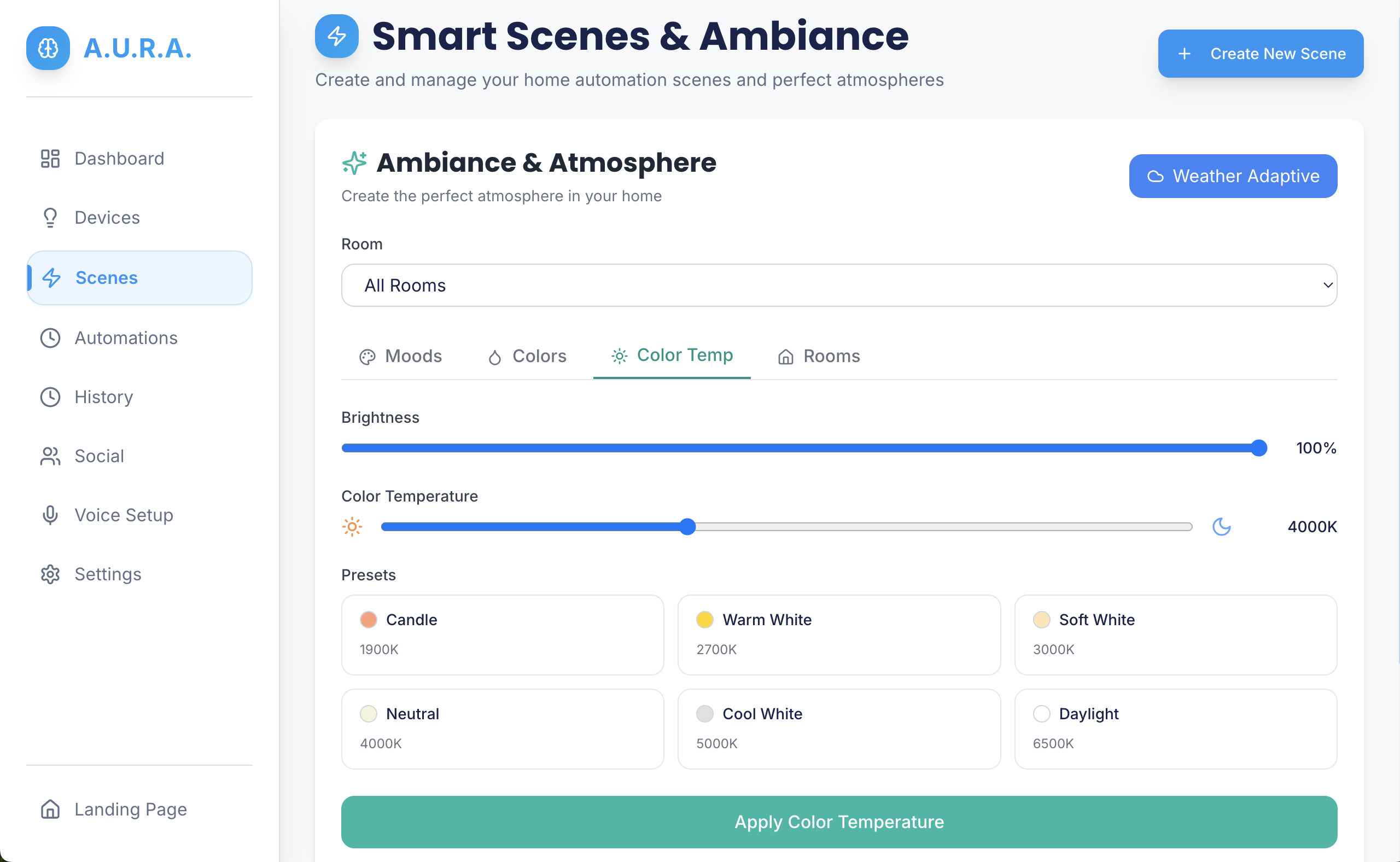
Concrete demo examples:
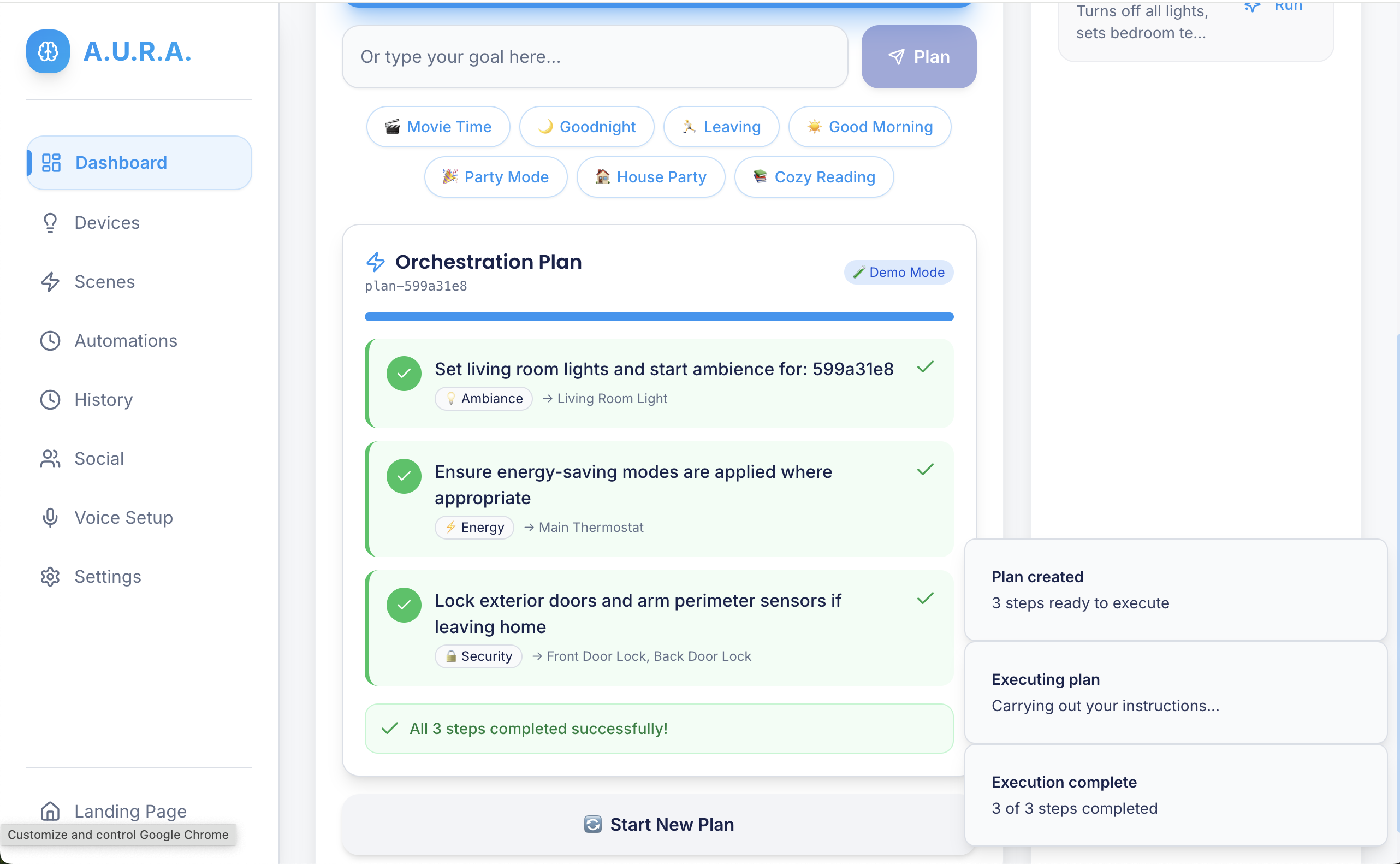
- Movie night: dims lights, closes blinds, sets TV to HDMI2, and starts a playlist — triggered from one goal.
- Morning routine: gradually raises thermostat, plays a short briefing, turns on the coffee maker.
- Focus mode: silence notifications, set Do Not Disturb, route smart lights to warm white.
Modes:
- mode (default) — complete offline demo using simulated devices.
- AI mode — use configured AI keys to resolve goals into plans.
- Goal API mode — forward goals to an external orchestrator (
AURA_BACKEND_URL). - Serverpod mode — use generated Serverpod bindings for typed RPCs and persistence.
How we built it
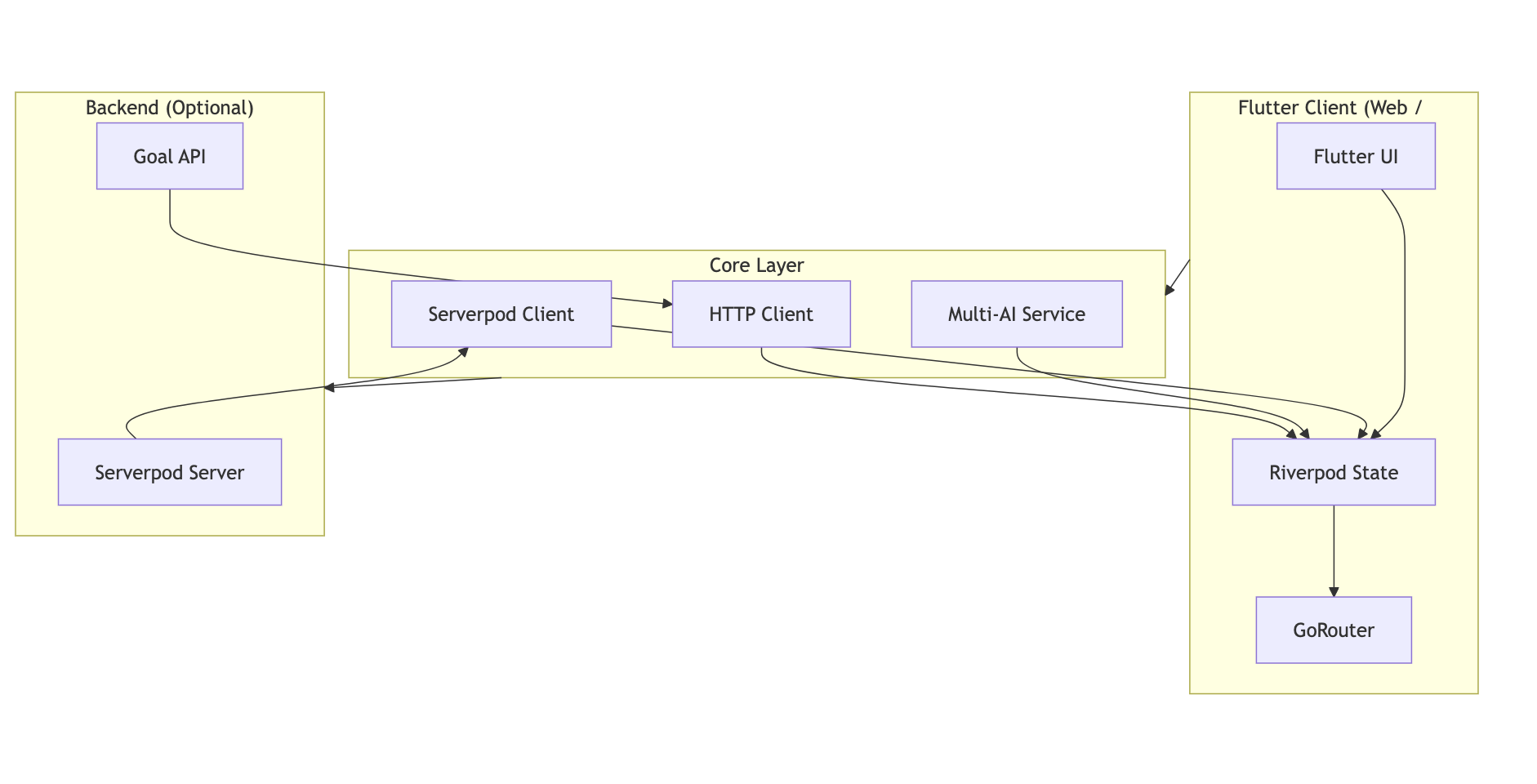
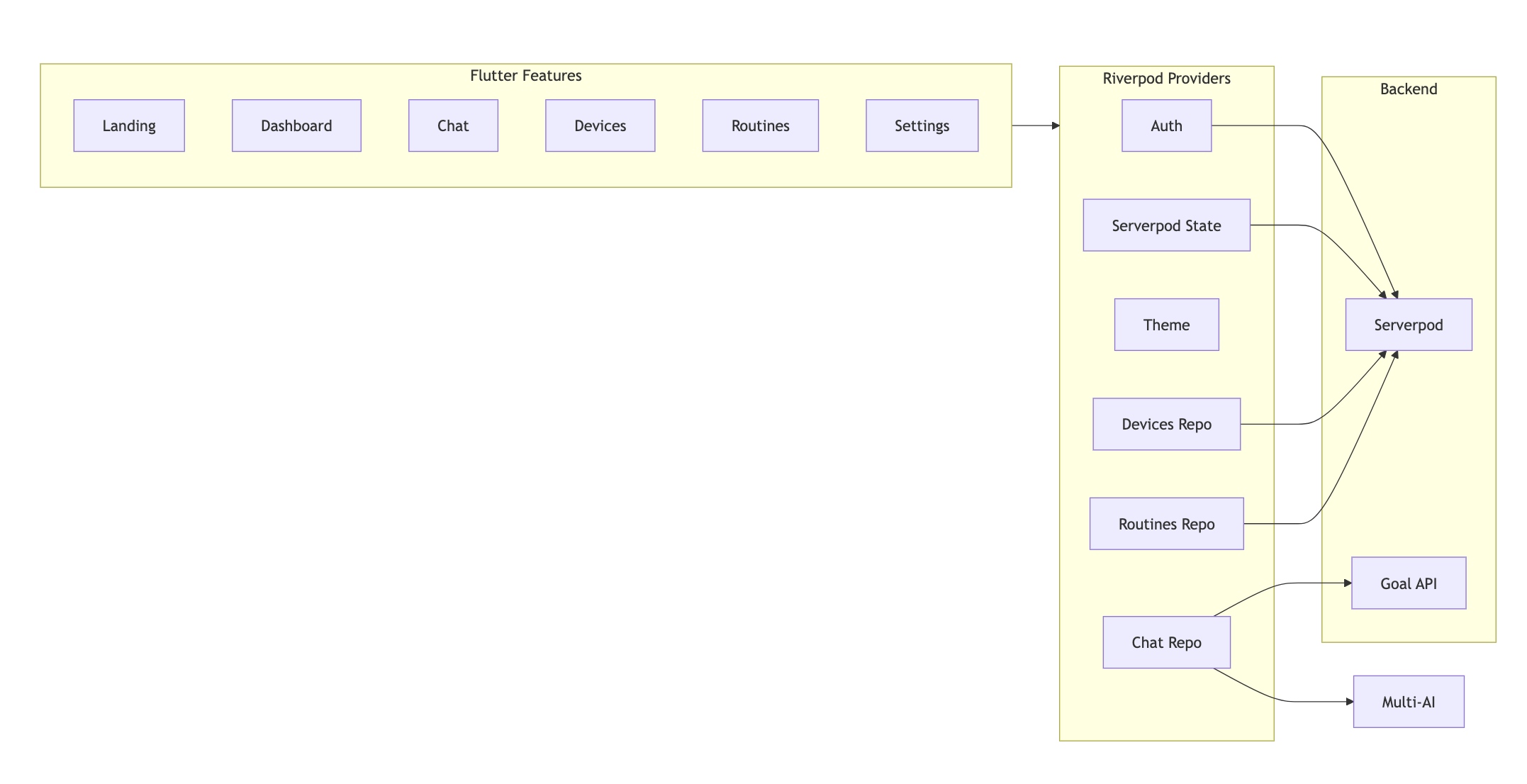
High level tech stack
- Frontend: Flutter (web & desktop), GoRouter for navigation.
- State: Riverpod (providers for AI, networking, devices, routines).
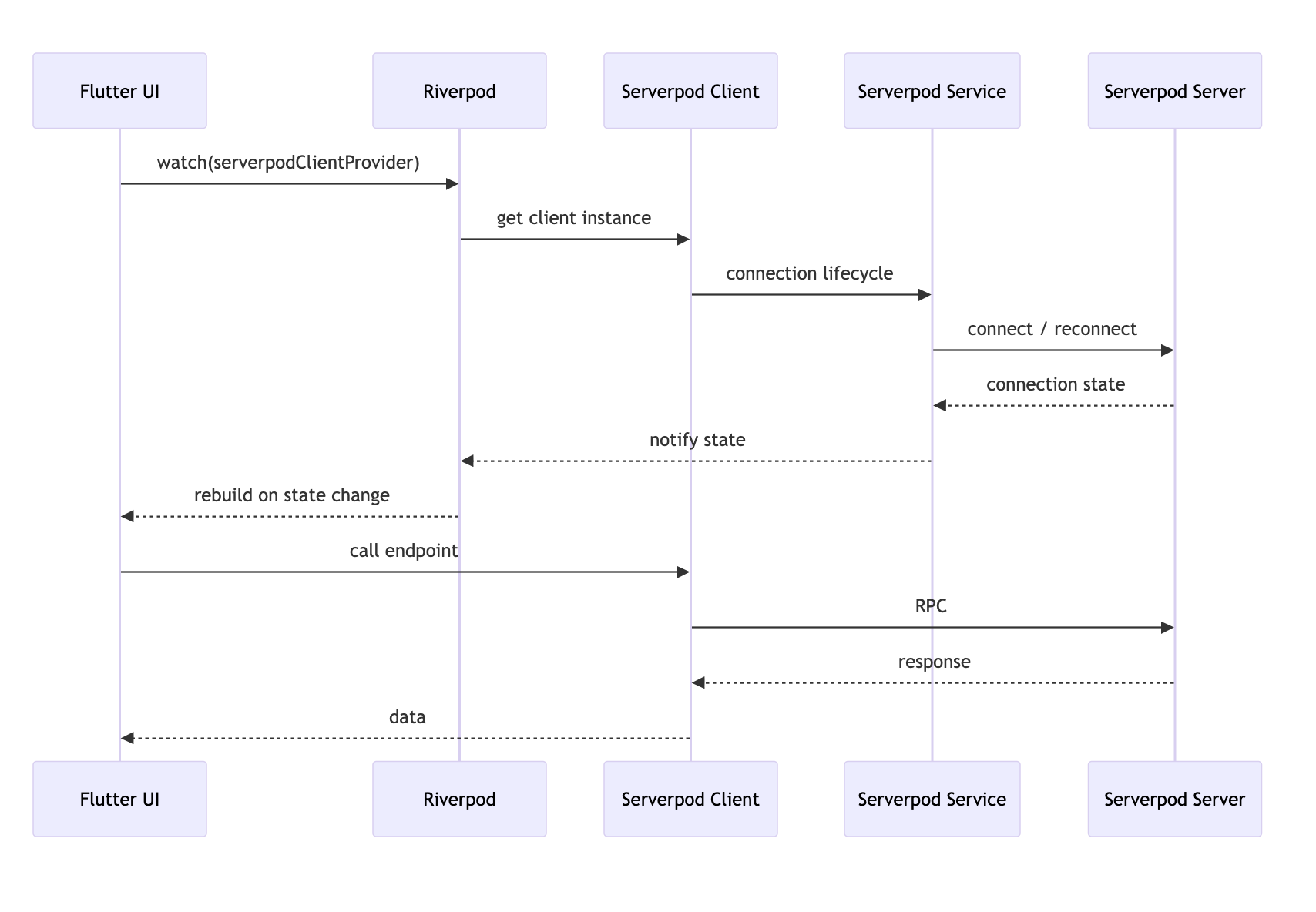
- Backend: Optional Serverpod server with generated Dart client.
- AI: Provider abstraction supporting OpenAI, Anthropic, Gemini, plus a provider.
- Data store (server): Postgres (via Serverpod) when Serverpod is enabled.
Key design patterns
- Goal abstraction: everything flows through a
Goalobject →GoalRouter→Plan→Executor. - Provider-agnostic AI adapter:
IAiProviderinterface with implementations for each provider and a. - Typed client/server interface: Serverpod generates DTOs and RPC endpoints so the Flutter client calls RPCs with real types instead of raw JSON.
- Demo-first approach: default and device simulators so judges can try the full UX without keys or servers.
Important files & directories
lib/features/chat/— goal input and chat UI components.lib/features/devices/— device models, simulators, and control surface.lib/features/routines/— routine editor and executor.lib/core/network/serverpod_client.dart— Serverpod wiring (instantiate whenSERVERPOD_URLis set).dart_defines.local.example— sample runtime config for local development.
Useful commands
# clone + deps
git clone https://github.com/lucylow/flutter-butler-aura.git
cd flutter-butler-aura
flutter pub get
# run in web (mode)
flutter run -d chrome
# run with AI key (example)
flutter run -d chrome --dart-define=OPENAI_API_KEY=sk_...
# run with Serverpod URL
flutter run -d chrome --dart-define=SERVERPOD_URL=https://your-server.com/
Serverpod scaffold (optional)
dart pub global activate serverpod_cli
serverpod create aura_server
# implement endpoints, then:
cd aura_server
serverpod generate
# add the generated client as a dependency to the Flutter app
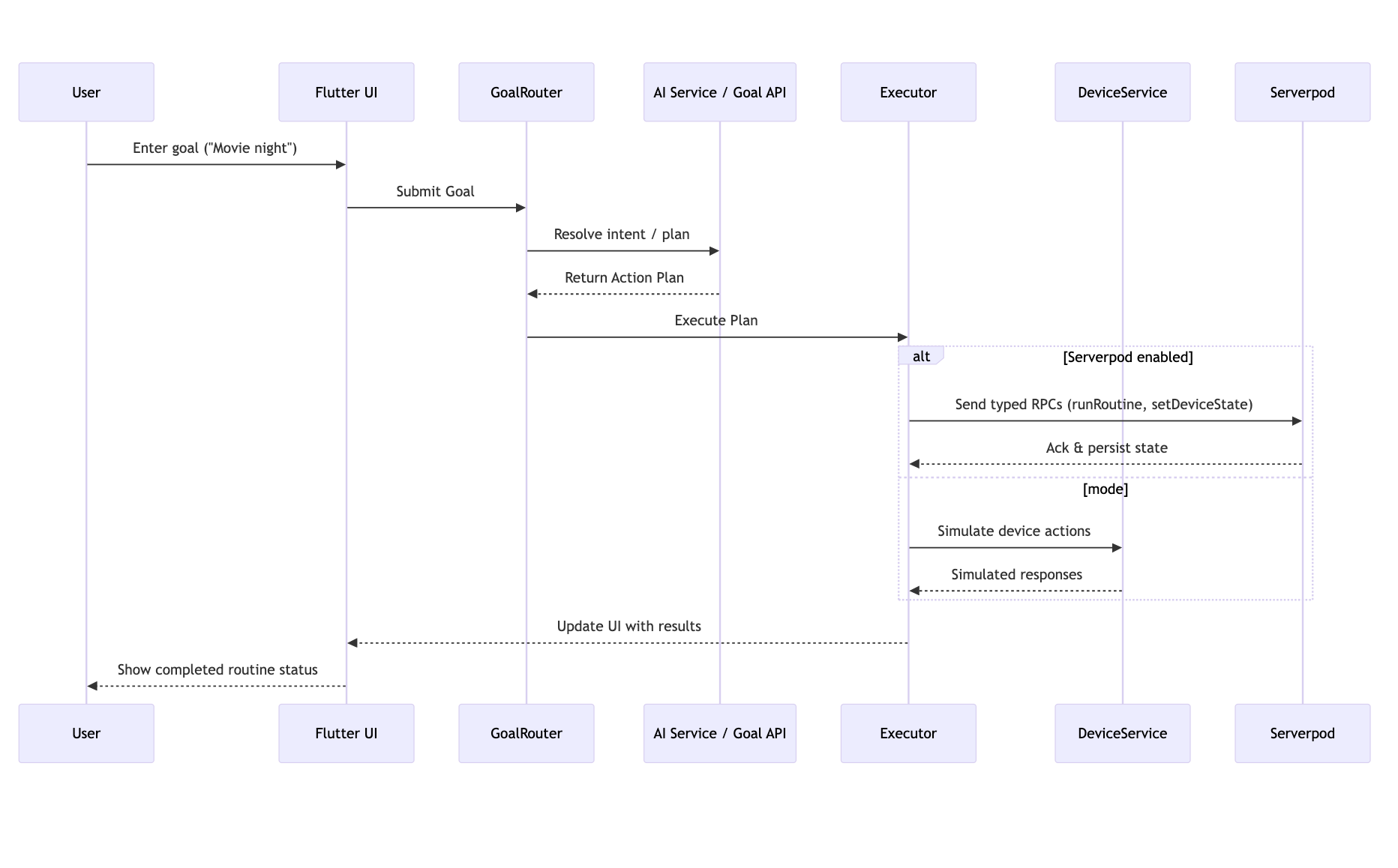
Challenges we ran into
- Demo reliability vs. production realism
- Judges need a reproducible demo, but production features rely on external AI and hosted backends. We solved this with a robust provider and simulated devices — but maintaining parity between and real behaviour took design effort (ensuring the produces realistic plans and edge cases).
- AI variability and prompt engineering
- Different AI providers return different plans and reply shapes. Designing a stable
Planschema and writing prompts that produce structured outputs across providers required multiple iterations and guardrails (parsing, validation, and schema enforcement).
- Typed client/server integration
- Integrating Serverpod to get generated types and client bindings is a great win for safety — but it required additional build steps and CI changes (run
serverpod generatebefore client builds). Managing path dependencies during local development added friction.
- State consistency and concurrency
- Executing multi-step routines raises partial-failure scenarios (one device fails). We implemented idempotent device commands, state reconciliation, and an Executor that supports partial rollbacks or compensating actions.
- Cross-target UI polish
- Designing controls and layouts that look good on both desktop and web required extra work: responsive layout, keyboard/clipboard support, and different input affordances for the demo.
- Secrets & security in demos
- Embedding API keys into builds is unsafe; we opted for
--dart-defineruntime values and documented how judges can demo locally without any keys using mode.
Accomplishments that we're proud of
- Goal-first orchestration architecture: a clear separation between user intention (Goal), planning (Plan), and execution (Executor). This made feature additions (new devices, routines, or provider integrations) much simpler.
- Multi-mode demo capability: judges can run the full app without any external services thanks to the provider and device simulators — while reviewers can also test the real integration paths.
- Serverpod typed bindings: when enabled, the client uses generated Dart types for RPCs, eliminating a class of runtime errors and making server interactions strongly typed.
- AI-agnostic service layer: swapping providers is a configuration change, not a code rewrite.
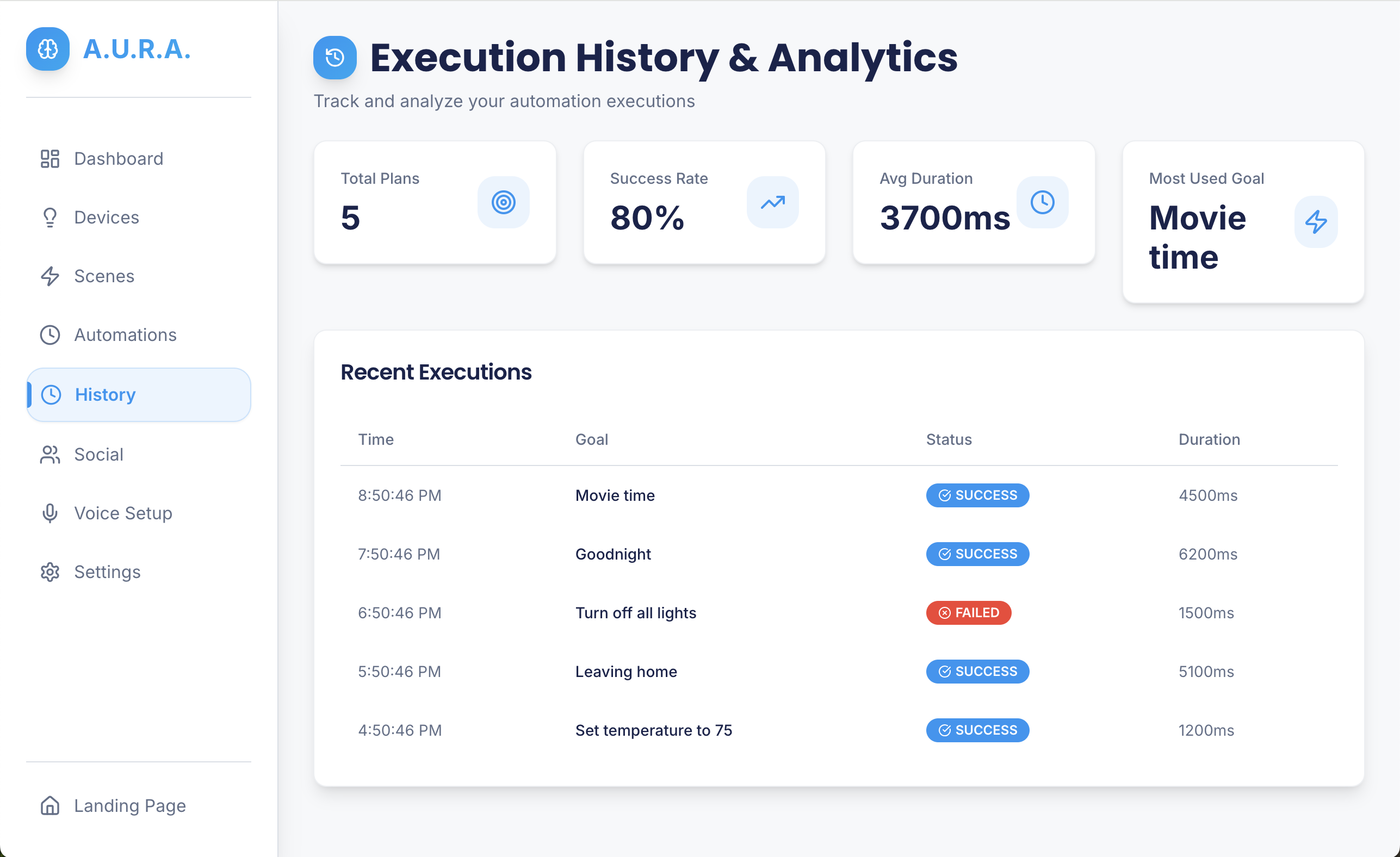
- Resilient execution model: the Executor handles partial failures, retries with exponential backoff, and reconciles device state with server persistence (when Serverpod is used).
- Test coverage for core logic: unit tests target the goal→plan translation logic and the Executor’s core behaviours to reduce regressions during rapid hackathon iteration.
- Hackathon-ready README & diagrams: documentation and visual diagrams that show judges where responsibilities live and how to demo each judging criterion.
What we learned
- Design for demoability early — building a dependable layer from day one made our demos stress-free. If you expect external dependencies (AI, servers), design clear fallbacks.
- Typed contracts speed debugging — Serverpod’s generated types reduced time spent debugging serialization/parsing issues; investing in type safety paid off quickly.
- Abstracting AI reduces vendor lock-in — designing an interface layer for AI providers allowed rapid switching and made it easier to A/B test prompts and providers.
- Be explicit about failure modes — real devices fail; simulate and report failures intentionally so UX and retry logic are robust.
- Keep prompts and schemas small and structured — simpler schema-validated outputs are far easier to map to an executor than raw free-form text.
- Riverpod makes complex derived state manageable — computed providers and scoped overrides simplified testing and feature toggles
What's next for A.U.R.A. (Adaptive, Unified, Responsive Assistant)
Short-term (next sprint / hackathon polish)
- Implement a small set of device adapters (e.g., Philips Hue, MQTT bridge) so users can toggle between simulated and real devices easily.
- Add voice input and wake-word support to make goal entry faster for demos.
- Create a
deployscript and include CI steps toserverpod generateautomatically so contributors don’t have to run it manually. - Add an end-to-end demo preset that runs a series of goals and captures a single screencast-ready run (for Devpost).
Mid-term (post-hackathon)
- Harden the Serverpod server for production: auth (short-lived tokens), role-based rules for routines, and improved observability (tracing + logging).
- Add scheduling and task queue support for deferred routines and scheduled automation (e.g., “start movie night at 8pm”).
- Create a library of prompt templates and a small rule engine to blend deterministic business rules with generative planning (reduce costly API calls).
- Build a modular adapter system so third-party integrations (IoT vendors, calendar providers) are plug-and-play.
Long-term (productization)
- Mobile packaging and app store deployments with secure key management and server pairing flows.
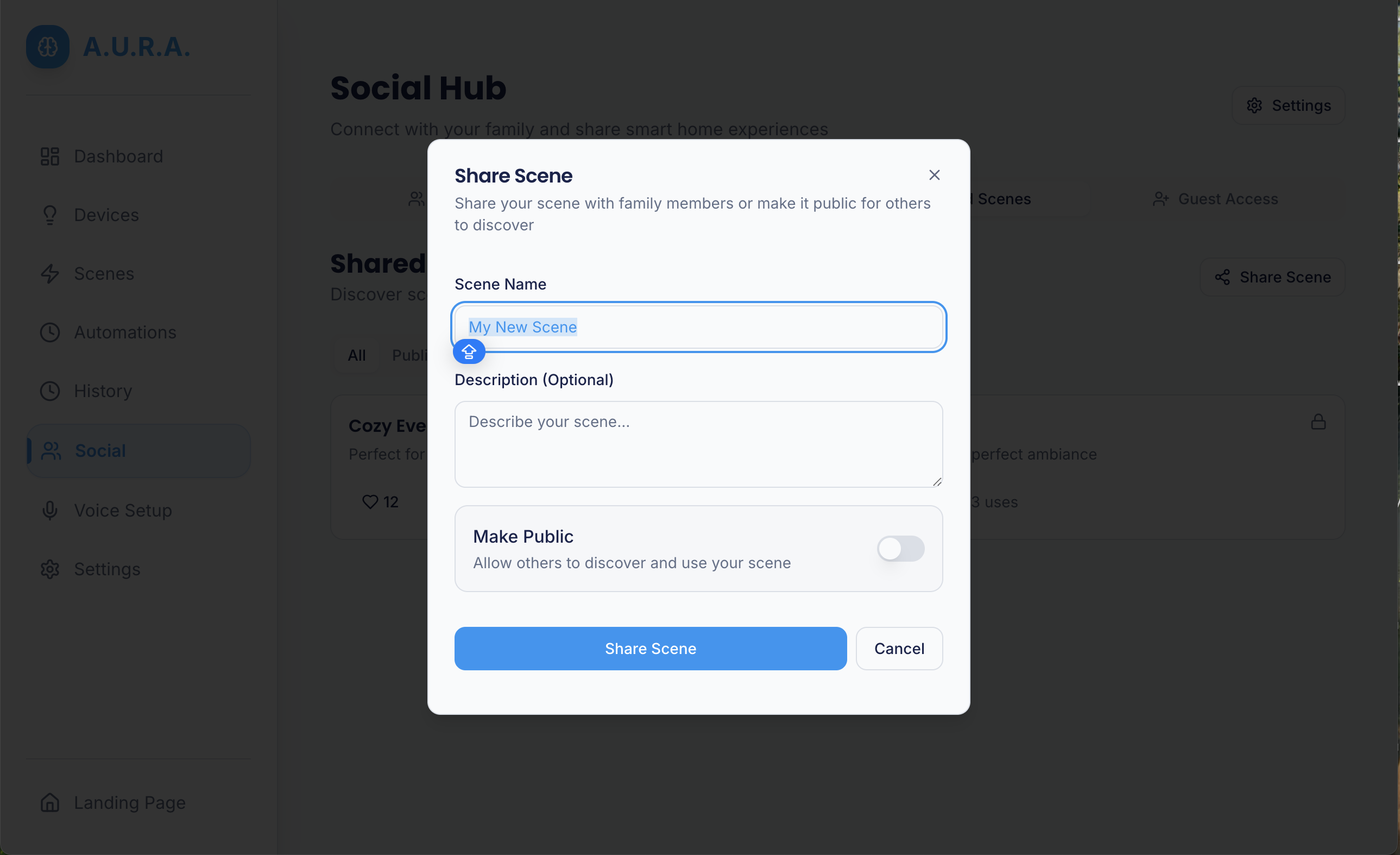
- A community marketplace for sharing routine templates or device adapters.
- On-device inference options (smaller LLMs) for privacy-sensitive workflows and lower latency in core planning tasks.
Built With
- flutter
- serverpod

Log in or sign up for Devpost to join the conversation.