Inspiration
The rapid improvement of generative AI has made deepfakes increasingly realistic and harder to detect using traditional artifact-based methods. In high-stakes settings such as remote hiring, financial verification, and video-based authentication, simply looking or listening is no longer sufficient.
We were inspired by the idea that humans instinctively trust consistency across senses — what we see, hear, and perceive over time — and questioned whether an AI system could reason about those same cross-modal signals. This led to Aura Forensics, a multimodal forensic assistant designed to reason about audiovisual coherence rather than rely on brittle, single-signal checks.
What it does
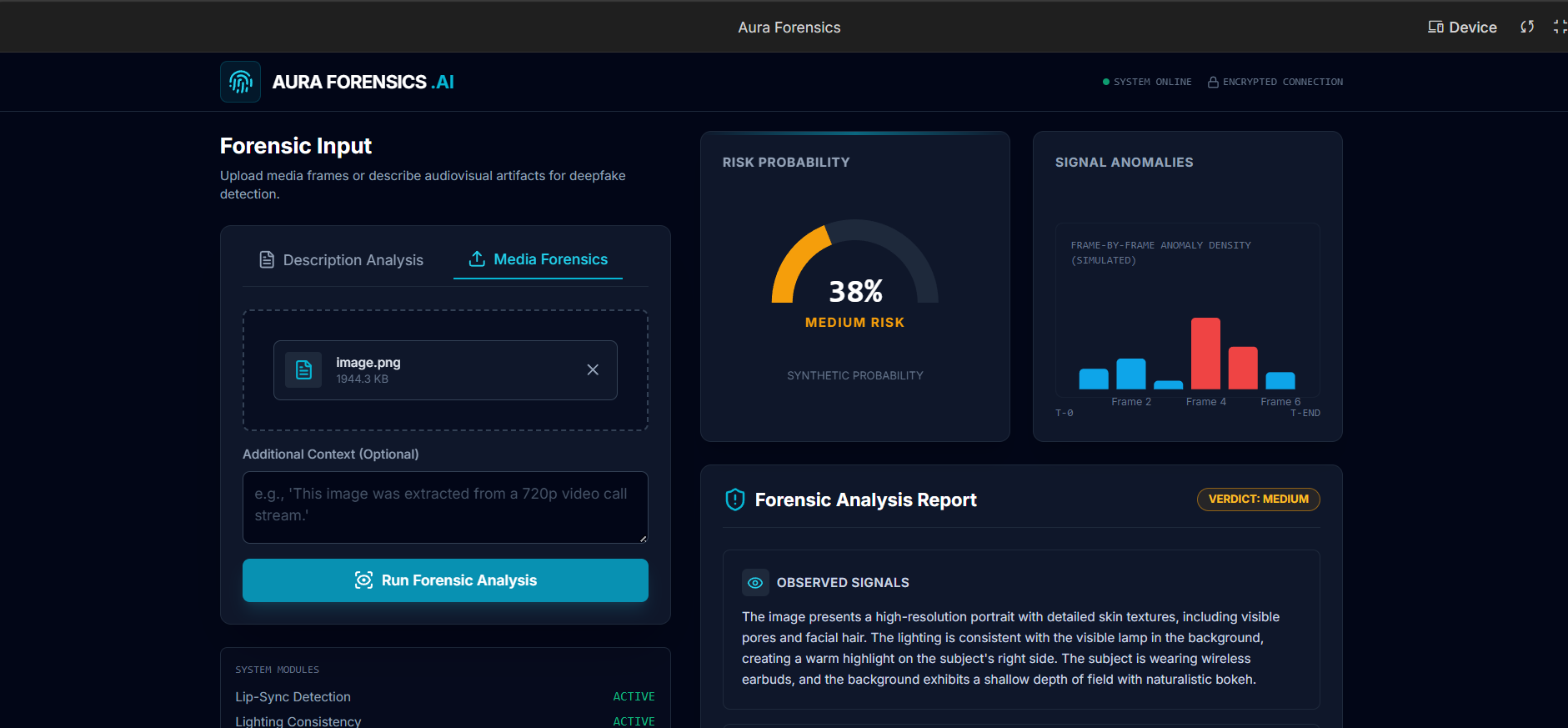
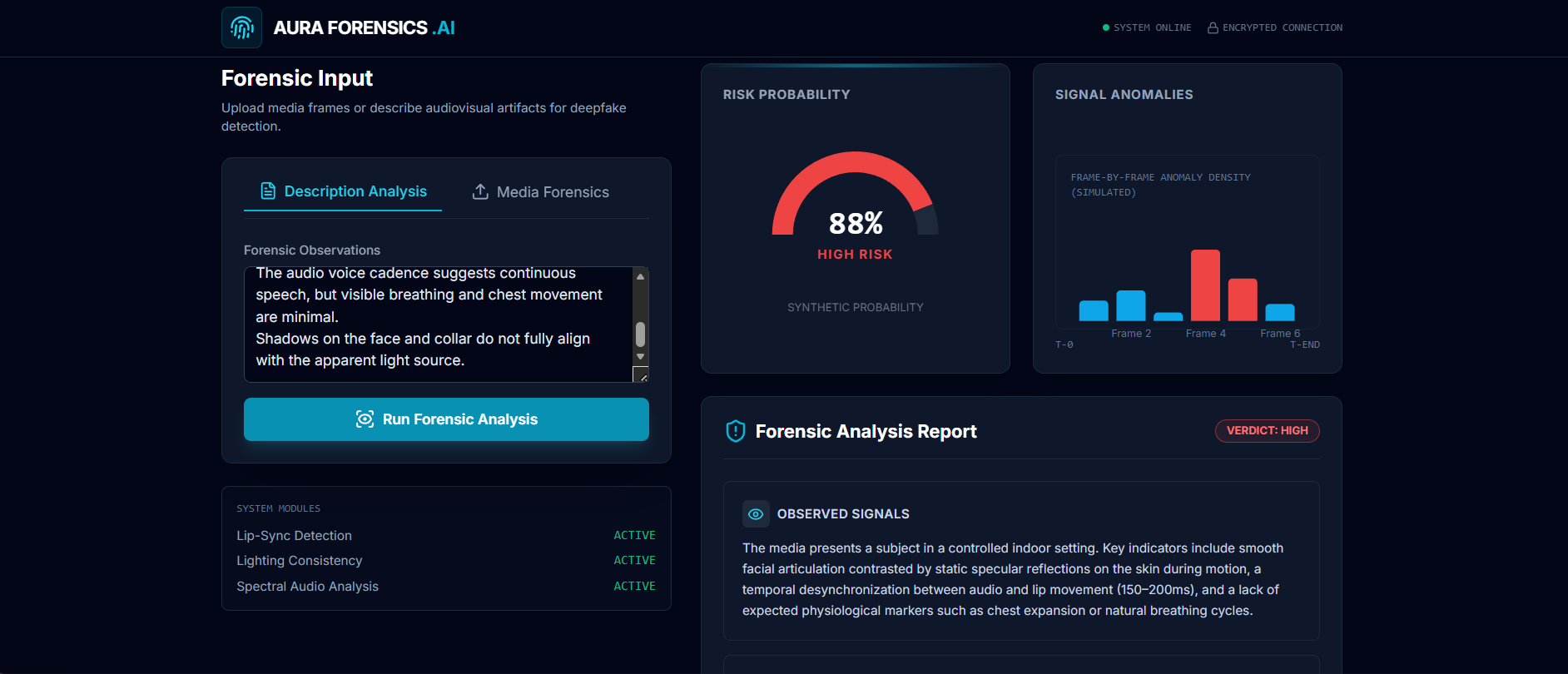
Aura Forensics analyzes visual and audio-related forensic observations from video calls or recordings to assess the likelihood of manipulation or deepfake generation.
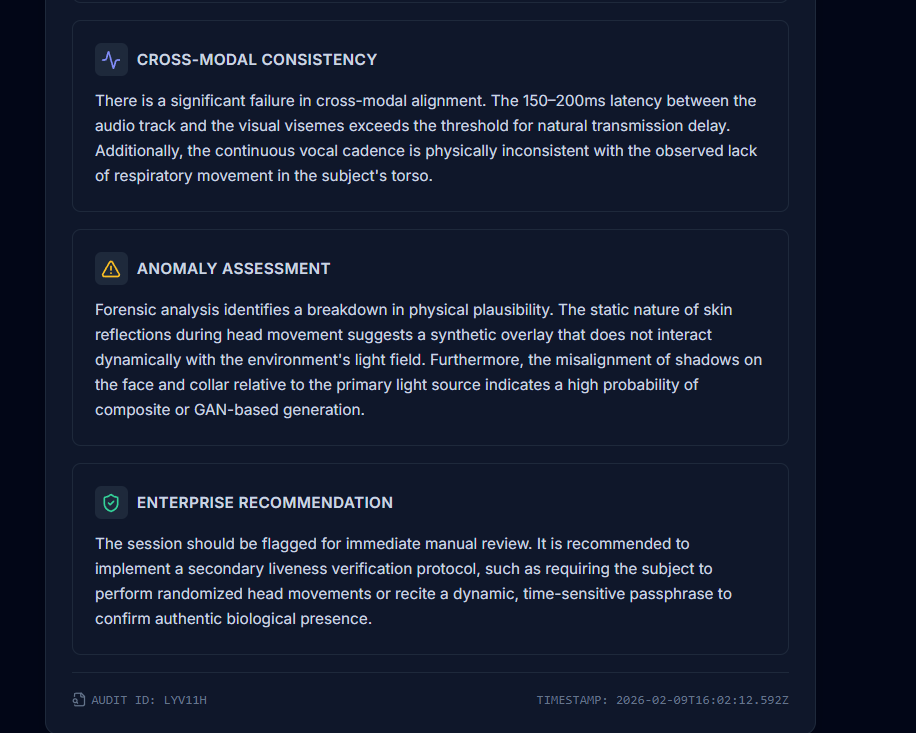
Instead of searching for isolated glitches, Aura reasons about cross-modal consistency, such as alignment between lip movement and audio, lighting and shadow behavior, facial motion plausibility, and temporal synchronization. The system produces a structured forensic report including observed signals, anomaly assessment, a probabilistic risk verdict, and recommended next steps.
How we built it
Aura Forensics is built using Gemini 3 as the core multimodal reasoning engine. The application accepts a representative video frame or image along with textual forensic observations derived from audio or temporal analysis.
Gemini 3 correlates these signals and evaluates their physical, biological, and temporal plausibility using high-level reasoning rather than deterministic rules. The frontend provides a clean forensic interface, while all analytical logic is driven by Gemini’s structured reasoning capabilities.
Challenges we ran into
A key challenge was avoiding overclaiming. Real-world deepfake detection is probabilistic, not absolute. We carefully designed outputs to remain audit-friendly, explain conclusions clearly, and avoid exposing internal chain-of-thought reasoning while still providing transparent justification.
Another challenge was designing a realistic demo without requiring full video and audio processing pipelines, while still representing how such systems would work in enterprise environments.
Accomplishments that we're proud of
- Designing a multimodal forensic workflow aligned with real-world security analysis
- Using Gemini 3 for reasoning across vision, audio, and temporal cues rather than surface-level pattern matching
- Producing structured, enterprise-grade forensic reports
- Demonstrating responsible AI design without misleading biometric claims
What we learned
We learned that the real power of multimodal models lies not just in perception, but in reasoning about consistency and plausibility. Gemini 3 enabled us to move beyond “does this look fake?” toward “does this make sense given how the real world works?”
We also gained insight into the importance of responsible framing when building security-sensitive AI systems.
What's next for Aura Forensics
Future work includes integrating automated signal extraction pipelines for video and audio, expanding temporal analysis across longer sequences, and supporting live call monitoring.
We envision Aura Forensics as a decision-support layer that complements existing detection systems rather than replacing human judgment.
Built With
- 3
- ai
- api
- css3
- gemini
- github
- html5
- javascript
- react
- studio
- typescript
- vite

Log in or sign up for Devpost to join the conversation.