-
-
Landing page
-
Watermark page
-
Verification page
-
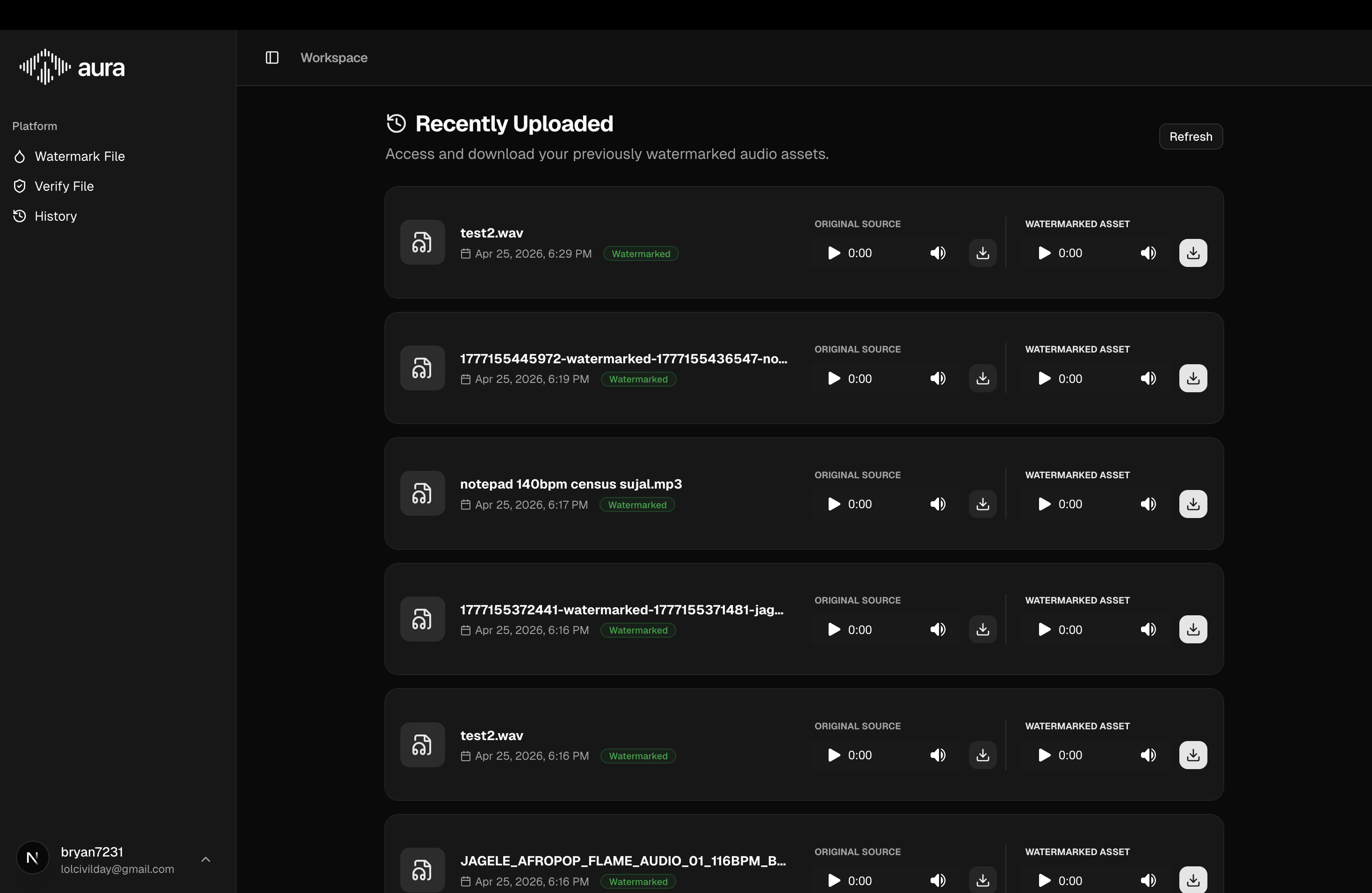
Recently uploaded page
-
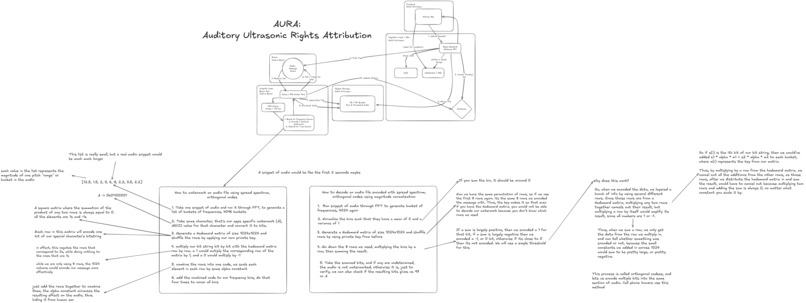
Architecture
We are Advanced and in the General Track.
Inspiration
Recently, with the rise of AI-generated music, it has become increasingly difficult to tell between what's human and what's not. We specifically remembered the song "I RUN" by HAVEN, which recently topped billboard charts around the world, despite it being 100% generated by AI. As avid musicians, we felt that the inability to distinguish a real produced song and a song made by AI is alarming and frightening. To solve this issue, we decided to incorporate cryptography, acoustics, linear algebra, and commercial signaling in a project to watermark AI songs, allowing listeners to easily differentiate between AI and genuine artists!
What it does
Our project allows a user to sign in and upload their music or songs. After uploading their song, we watermark the song with a hidden signature, which is imperceptible to the human ear; the song sounds exactly the same afterwards. Later on, users can easily identify if a song has been watermarked through our system too; we can scan the song again, checking for the data we encoded in the audio. Thus, our app could let models like Suno watermark generated songs, ensuring that people know it's made by AI and not humans!
How we built it
All architectural planning was done in Excalidraw, as shown above (at the top of the page).
We have three layers: the frontend, ingestion layer, and compute layer.
To start with, our frontend layer is comprised of a Next.js app. The frontend has BetterAuth, allowing users to authenticate with GitHub accounts. The auth is synced with our backend, which is written in Javascript via Bun.js, with the help of Elysia.js and Prisma DB ORM. We have a Postgres database to store the users, and we also have an S3 bucket on AWS to store the audio files that users uploads. This S3 database lets us store the recently uploaded songs of all users, allowing users to view what they've watermarked previously, and download the songs again securely!
After users authenticate through our BetterAuth & Prisma DB systems, they are able to upload a file to add an AuraTag or check for an already existing tag. This creates a Redis job in our Python Compute Layer, where a Celery worker tags the audio and returns it to the user through Redis. Redis ensures that our system is fast and responsive; it will queue tasks through Celery, running them asynchronously so users can simultaneously get fast responses!
Finally, our compute layer has two Flask endpoints for processing incoming audio files: one for encoding and one for decoding data from audio files. These endpoints accept requests from the backend, queuing jobs and downloading the audio from our S3 buckets to return the results to the frontend.
Our encoding and decoding process is quite complex, involving spread spectrum, orthogonal codes, Fourier transforms, magnitude normalization, pseudo noise sequences, and cryptographic shuffling.
Starting with the encoding process, we first take the audio file and break it down into chunks. Each chunk will have the same data encoded into it, and this redundancy ensures that it's very obvious if our watermark has been injected into the audio or not. On each chunk, we conduct a Fast Fourier Transform, breaking down the sound information into magnitudes and phase shifts. Storing both of these lets us recreate the full audio again after we encrypt data into the audio file. The Fourier transform enables us to bucket the frequencies of sound, enabling us to apply a change to a range of frequencies at once, spreading the information out. This process is called spread spectrum, and ensures that our changes to the audio are essentially imperceptible to the human ear.
After that, we take our watermark, which is a specific character, and convert that character's ASCII value to binary. Then, we generate a Hadamard matrix, which is a square matrix where the summation of the product of any two rows is 0. This specific matrix is very essential for implementing orthogonal codes, a common technique employed by cellphone towers to send information to phones around the globe! Because different rows essentially cancel out when you multiply them, we can easily decode the information later on. We then take rows from the Hadamard matrix, and multiply them with the bit string; each row in the matrix corresponds to one bit in our string. Since a Hadamard matrix is made of 1s and -1s, we translate the bit string to be 1s and -1s, where 0s are -1s. Thus, a 0 in the bit string would flip the sign of one of the selected rows from our Hadamard matrix. After obtaining the rows from the Hadamard matrix and multiplying them with the bit string, we combine the rows together into one combined code. We can achieve this simply by just adding the rows together element by element. Finally, we add this combined code to the magnitudes from the Fourier Transform, scaled by some alpha constant to ensure that we can find it later when decoding. These steps seem to be arbitrary, but its lets us decode the information reliably later on.
A large concern of ours was to make the watermarking secure, preventing others or AI from decoding the water mark and removing it from watermarked audio files. To solve this, we implemented several cryptography techniques. First, we have a seed in our Python compute layer that we compute several things from; without this seed, no one can possibly reverse engineer the data. We first generate a list of random indices; these indices correspond to indices in the Hadamard matrix. Each row in the matrix is unique, so by picking random indices, someone trying to decode the data has absolutely no idea which rows we used to encode the data. Then, we generate a random index to apply the code to, as the Fourier Transform returns more buckets than the length of our code. As such, someone else would not know where we hid the message in the audio if they don't know this index. Finally, we also apply a Pseudo Noise sequence to the code after we combine the rows. The sequence is essentially a series of 1s and -1s, thus flipping some sections of the code. By multiplying the sequence again, those sections are flipped back, thus allowing us to discern the original code. As a result, people without the specific noise sequence that we generated with our seed would be unable to even use the code, even if they found the combined code. Psuedo Noise sequencing is another technique commonly used by spy technology and radio.
For the decoding section, we start off the same, dividing into chunks and conducting FFT. Then, we take the magnitudes and apply a flattening process, preserving the data on the audio still. After that, we multiply the buckets by our PN mask, and since the PN mask cancels out with itself, multiplying it would reverse the masking process we did on the code. Finally, we go through row by row of the selected rows from our Hadamard matrix, multiplying the row to the audio, then taking the sum of the columns. This process generates a correlation value. Thinking about it mathematically, the scaling and flattening processes we did with the alpha constants are just constant multipliers on the original code. Since the rows of a Hadamard matrix cancel out when you multiply them and sum, we cancel out all the other rows of information from the other bits encoded onto the audio when we multiply by one row. Thus, the remaining info on the audio would just be the singular row that we multiplied it by. When we encoded information, it would basically apply slight nudges to the magnitudes of certain frequencies in the audio, we add those nudges together to get one final positive or negative number depending on if the bit is 1 or 0. This reason why this is so effective is because on an unmarked file, multiplying the row to the audio essentially does nothing, and summing it would get you a correlation close to 0. However, on a marked file, when we multiply the row again, all the negative nudges would turn to positive, amplifying the nudges and making it very clear that the audio was watermarked. Finally, we string together these correlations and output the data the was encoded into the file!
Challenges we ran into
One challenge we initially ran into was that the correlation from watermarking did not make a noticeable difference in the audio file, so that when we attempted to decode, we could not make out any noticeable change. Thus, we scaled our alpha constant more, and added the repeated the process more across the audio, ensuring the the minuscule changes we made would add up and become more apparent. This solved our issues, allowing us to successfully watermark the audio!
Accomplishments that we're proud of
We’re proud that we built something aimed at a real and growing problem: it is becoming harder to tell whether music was made by a person or generated by AI, especially as AI songs keep spreading online. Creating a way to help verify human-made work made the project feel meaningful beyond just the technical challenge.
We’re also proud that we were able to take difficult math-heavy ideas and make them work in a real system. Using techniques like Fast Fourier Transforms, spread spectrum methods, orthogonal coding, and hidden signal embedding pushed us far beyond basic app development and made the project much more advanced than a typical upload-and-download platform.
What we learned
We learned a lot about how math and signal processing can be applied to real-world problems. In particular, we got hands-on experience with Fast Fourier Transforms and saw how converting audio into the frequency domain makes it possible to carefully modify sound in ways that are hard to notice but still detectable later.
We also learned that these ideas are much harder in practice than they seem on paper. Small choices like scaling, chunking, redundancy, and correlation strength made a huge difference in whether the hidden signal could actually be recovered reliably. This taught us how important experimentation, tuning, and testing are when working with audio, linear algebra, and other mathematical methods.
What's next for AURA: Auditory Ultrasonic Rights Attribution
We hope that this technology can be adopted by generative AI companies such as Suno, such that differentiating between their models' creations and human art is easy. We hope to also be able to encode more bits of information or data into audio files.
Built With
- celery
- elysiajs
- flask
- python
- redis
- typescript

Log in or sign up for Devpost to join the conversation.