-
-
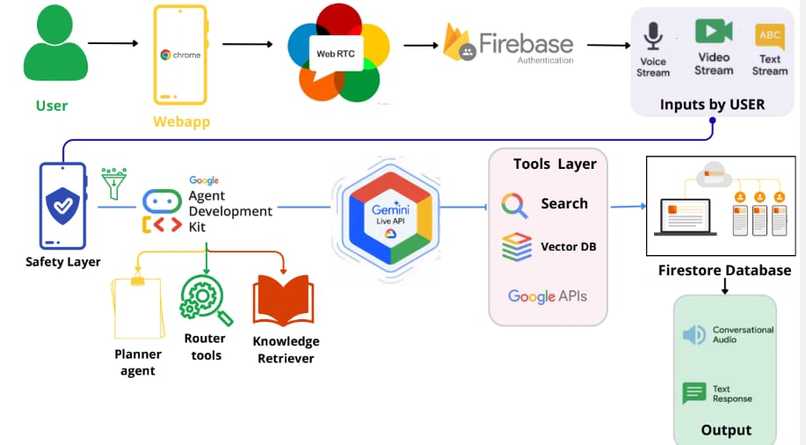
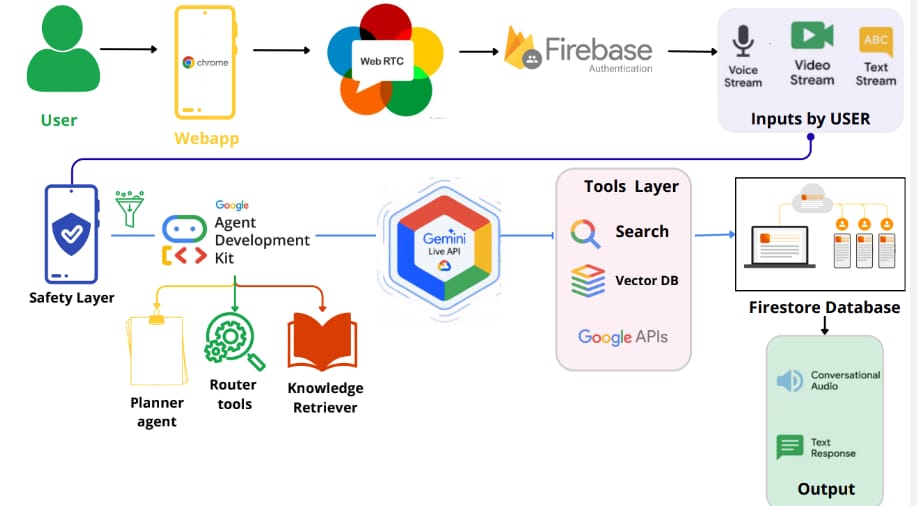
Architecture of Aura AI
-

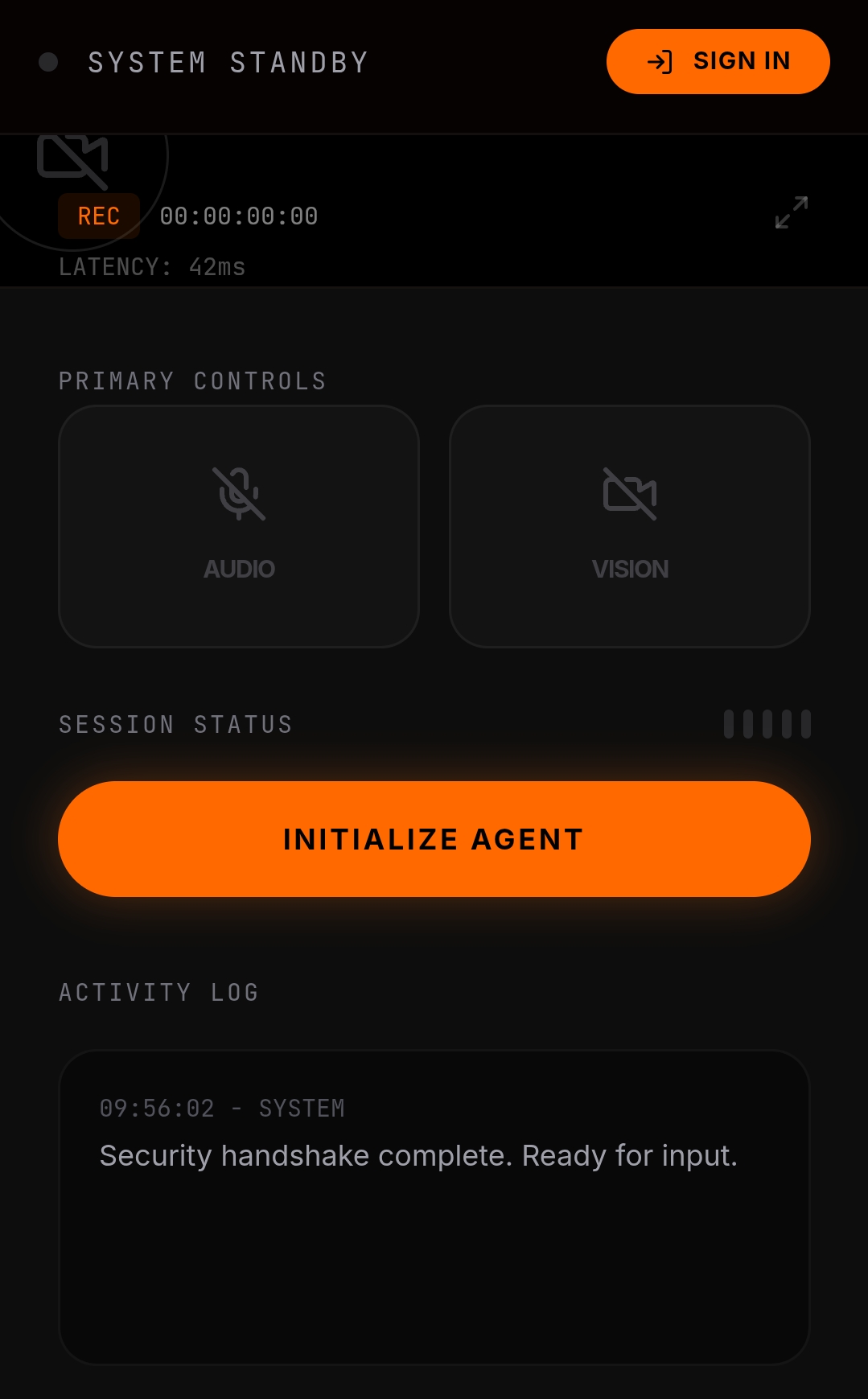
Initialisation screen
-
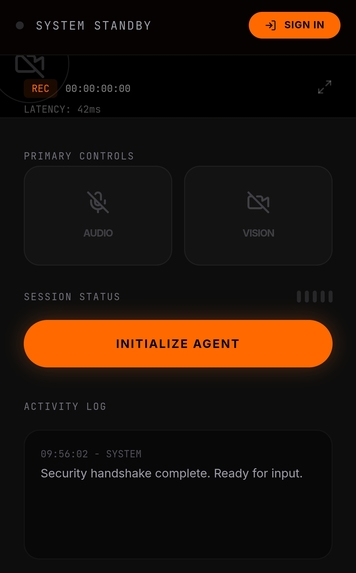
UI UX Design
-

Logo


Inspiration
The way we interact with AI is broken. You type. You wait. You read. It feels like sending emails to a robot.
We asked a simple question: what if AI could just... talk with you? Not at you — with you. Interrupt it when you have a thought. Show it your screen, your homework, your broken code. Have it see what you see. Speak in your language. That vision became AURA AI.
We were also deeply moved by a real problem — 285 million people worldwide are blind or have low vision. They navigate a world built entirely for sighted people, every single day. With a phone camera and Gemini's live vision capabilities, we realized we could build something that genuinely changes their daily life. That became NurAI (نور) — embedded right inside AURA — named after the Urdu word for Light, because that's exactly what it gives people who live without sight.
What it does
AURA AI is a real-time multimodal live agent — you talk to it, it talks back, and it sees through your camera. No typing required. No waiting for responses.
Core capabilities:
- 🎤 Live Voice — speak naturally in any direction, AURA listens and responds in real-time with a natural voice
- 📹 Live Camera — point your camera at anything — homework, objects, text, your surroundings — AURA analyzes it and responds instantly
- ⚡ True Barge-in — interrupt AURA mid-sentence by just speaking. It stops immediately and listens to you. Say "wait" or "stop" and it pauses on the spot
- 💬 Text Input — type when voice isn't an option
- 🌐 Multilingual — English, Urdu, Hindi, Spanish, Arabic — switch languages naturally mid-conversation
- 🎵 Media Tools — say "play [song]" and YouTube opens. Say "search [topic]" and Google opens
- 🔐 Persistent Sessions — Google Sign-In with full conversation history saved to Firestore
5 specialized agent modes in one app:
| Mode | What it does |
|---|---|
| ✦ Assistant | General-purpose AI companion for anything |
| 📚 Tutor | Point camera at homework → step-by-step explanation |
| 🌐 Translator | Real-time voice translation across languages |
| 👁 Vision | Live scene analyst — describes everything the camera sees |
| نور NurAI | Accessibility companion for blind/low-vision users — proactive hazard detection, spatial guidance, text reading |
How we built it
The core stack:
- LLM Brain: Google Gemini 2.5 Flash Live (
gemini-2.5-flash-native-audio-preview) via@google/genaiSDK — the only model with native real-time audio + vision streaming in a single WebSocket session - Frontend: React 19 + TypeScript + Vite 6 — component-based UI with Framer Motion animations and Tailwind CSS
- Audio Pipeline:
getUserMedia→ScriptProcessorNode→ PCM16 Float32 conversion → base64 →sendRealtimeInputto Gemini. Response audio: base64 PCM →AudioContextbuffer queue with precisestartTimescheduling - Video Pipeline:
getUserMedia(video)→<canvas>drawImage()at 1fps →toDataURL(image/jpeg, 0.6)→ base64 →sendRealtimeInputasimage/jpeg - Barge-in Engine: Two layers — server-side
serverContent.interruptedsignal from Gemini + client-sideSpeechRecognitionAPI watching for keywords ("wait", "stop", "hold on"). Both immediately callstopPlayback()which kills all activeAudioBufferSourceNodes - Auth + DB: Firebase Authentication (Google OAuth + anonymous guest fallback) + Firestore for user profiles and conversation history
- Infrastructure: Docker multi-stage build (Node 20 Alpine) → GitHub Actions CI/CD → Google Container Registry → Google Cloud Run with auto-scaling
The entire system runs as a single bidirectional WebSocket stream — audio in, video frames in, audio + text out — with no intermediate transcription step. This is what makes it feel instantaneous.
Challenges we ran into
Real-time audio synchronization was the hardest problem. Gemini sends audio in chunks. If you simply play each chunk as it arrives, you get gaps and stutters. We built a precise scheduling queue using AudioContext.currentTime and nextStartTime tracking — each buffer starts exactly where the previous one ended, creating seamless playback.
Barge-in felt fake at first. The server sends an interrupted signal, but there's a network delay. We added a second layer — client-side SpeechRecognition running in parallel that detects keywords instantly, giving the perception of zero-latency interruption even before the server signal arrives.
Camera + audio simultaneously required careful async coordination. Both streams need to run in parallel without blocking each other or throttling Gemini's rate limits. We settled on 1fps for video — frequent enough to be contextually aware, conservative enough to stay within limits.
Cross-browser AudioContext restrictions — browsers block audio playback until a user gesture occurs. We had to carefully track user interaction state and resume the AudioContext at the right moment, otherwise AURA would "speak" silently.
Building 5 distinct agent personalities that feel genuinely different — not just different system prompts, but different voices (Charon, Aoede, Fenrir, Puck, Kore), different conversation styles, and different proactive behaviors required significant prompt engineering and testing.
Accomplishments that we're proud of
- 🏆 True zero-latency barge-in that actually feels like talking to a person — not a chatbot with a stop button
- 🌍 NurAI (نور) — a genuine accessibility tool that can describe surroundings, warn about hazards, read text aloud, and guide low-vision users through space — built in hours, useful for millions
- ⚡ Single WebSocket stream carrying simultaneous audio + video + text — no polling, no REST calls, no transcription middleware
- 🎭 5 fully realized agent modes with distinct voices and personalities, all in one seamless app
- 🚀 Full CI/CD pipeline — one
git pushdeploys the entire app to Google Cloud Run automatically - 📊 Production-grade architecture — Firebase Auth, Firestore persistence, Firestore security rules, Docker healthchecks, multi-stage builds
What we learned
Real-time AI requires a completely different mental model. Traditional AI is request → response. Live AI is a continuous stream with state — you have to think in terms of buffers, queues, timing, and interruption states, not request handlers.
Gemini 2.5 Flash Live is uniquely powerful. No other model today can stream native audio in and native audio out with simultaneous vision — no transcription step, no TTS step, just direct multimodal I/O. This is the architecture that makes a truly natural conversation possible.
Voice UX is 10x harder than text UX. When something goes wrong in text, the user sees it. In voice, they just hear silence or a weird artifact. Every edge case — mic permission denied, AudioContext locked, WebSocket dropped — needed a graceful fallback that sounds natural, not just looks like an error state.
Accessibility is an underserved AI frontier. 285 million people need this. The technology exists today. The barrier isn't capability — it's that most developers don't think about these users first. Building NurAI made us realize this should be a default mode in every voice-capable app, not a special feature.
The browser is a surprisingly capable real-time AI terminal. Between getUserMedia, AudioContext, SpeechRecognition, and WebSocket — everything we needed was already in the browser. No native app required.
What's next for AURA AI - Your Personal Live Assistant
Immediate (next sprint):
- 🔧 Tool use / function calling — connect AURA to real APIs: calendar, weather, smart home, reminders
- 📱 Mobile PWA — install on Android/iOS for always-available assistant access
- 🌍 More languages — French, German, Chinese, Portuguese, Bengali
Near-term:
- 🗺️ Navigation mode for NurAI — GPS + camera fusion for outdoor walking directions with real-time hazard narration
- 🧠 Long-term memory — vector-based conversation memory across sessions using Firestore + embeddings
- 👥 Multi-user sessions — share a live agent session with others for collaborative tutoring or support
Vision:
- 🥽 Wearable integration — smart glasses with bone conduction audio for truly hands-free, always-on NurAI
- 🤝 Enterprise modes — customer support agent, medical intake assistant, real-time meeting transcription and Q&A
- 🌐 Offline mode — on-device Gemini Nano for basic scene description and voice responses without internet
AURA started as a hackathon project. But NurAI convinced us this needs to be a real product. We're building it.
Built With
- clsx
- docker
- express.js
- firebase-authentication
- firebase-firestore
- framer-motion
- github-actions
- google-cloud-build
- google-cloud-run
- google-container-registry
- google-gemini-2.5-flash-live-api
- html5-web-audio-api
- lucide-react
- node.js
- speechrecognition-api
- tailwind-css
- tailwind-merge
- typescript
- vite
- webrtc





Log in or sign up for Devpost to join the conversation.