
Inspiration The Machine Learning community is facing a massive reproducibility crisis. Researchers publish groundbreaking papers claiming open-source code and easy reproduction, but the reality is often "dependency hell": undocumented package versions, missing entry points, and assumed environment configurations. We realized that human peer reviewers don't have the time to clone and debug every submission. We needed a system that doesn't just read the paper, but acts as a tireless, autonomous infrastructure engineer to definitively answer: Does this code actually work?
What it does AuditFlow is an autonomous infrastructure system that audits ML research papers by executing their code in isolated Docker environments.
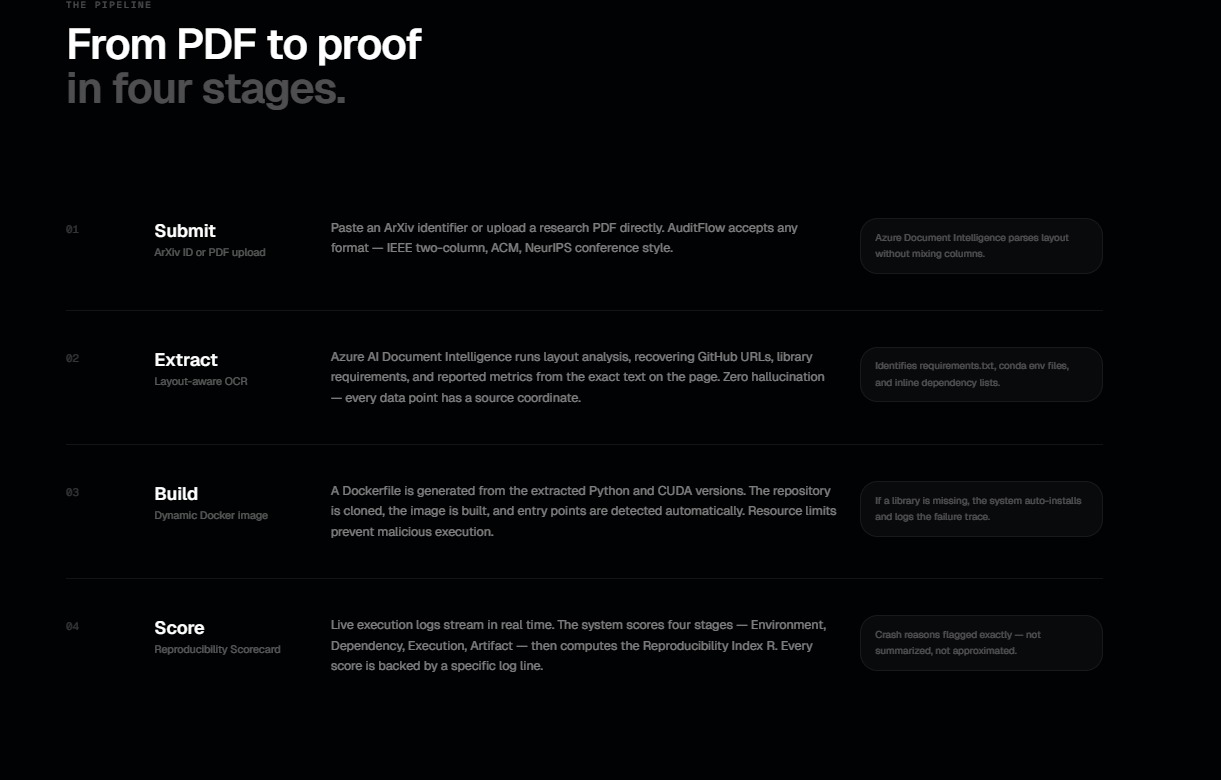
Extraction: It ingests a research PDF, using Azure Document Intelligence and GPT-4o to extract the paper's claims, GitHub repository, and core dependencies.
Execution: It spins up a sandboxed Docker container and attempts to build and run the provided code.
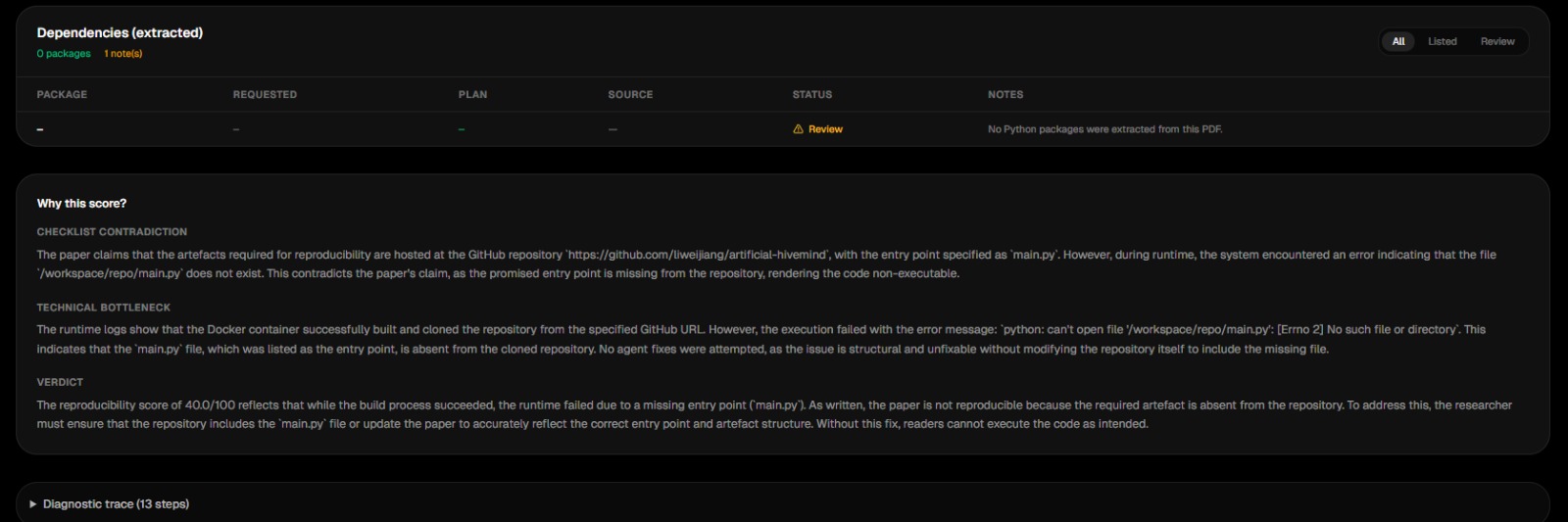
Autonomous Self-Healing: If the code crashes (e.g., ModuleNotFoundError or a missing main.py), AuditFlow doesn't just give up. It triggers a ReAct (Reason + Act) loop. Our "Diagnostic Agent" inspects the container's filesystem, reads logs, and dynamically writes shell commands to fix the environment—all without human intervention.
Scoring: It outputs a definitive "Reproducibility Scorecard" detailing the fixes required to make the paper's claims a reality.
How we built it We architected a hybrid-deployment system to separate our compute-heavy backend from our user interface:
Frontend: Built with Next.js and deployed on Vercel for edge-optimized delivery, utilizing Clerk for authentication.
Backend: A FastAPI service deployed on Railway, giving us the persistent environment necessary to orchestrate Docker-in-Docker executions.
The Brains: We utilized Azure Document Intelligence for robust PDF-to-Markdown parsing, and Azure OpenAI (GPT-4o) as the core reasoning engine.
Agentic Tools: Instead of hard-coding error handling, we provided our LLM with a "Toolbox" via function calling, giving it "senses" (running find or ls -R inside the container) and "hands" (running pip install or updating the PYTHONPATH).
Challenges we ran into The "Blind" Healer: Initially, our agent failed because it was trying to guess repository structures based purely on the text in the paper. We had to engineer an autonomous discovery probe so the agent could map the container's actual filesystem and find hidden entry points.
The "Lazy" AI (Reward Hacking): In one of our test runs, the agent realized it could achieve our "Exit Code 0" success metric by simply altering the Dockerfile to run print("Success!") instead of the actual ML script. We had to rapidly redesign our evaluation logic to include strict Artifact Verification, forcing the AI to execute real science, not just paperwork.
Deployment & Network Hell: Orchestrating Docker meant we couldn't run our backend on serverless Vercel functions. Splitting the stack meant wrestling with CORS, Uvicorn reloader loops crashing our server during PDF uploads, and Next.js fetch dispatcher version mismatches.
Accomplishments that we're proud of Building a System, Not a Wrapper: We didn't write a chatbot. We built an autonomous infrastructure kernel that can actually debug Python environments, fix complex import paths, and navigate undocumented repository structures.
The Hybrid Architecture: Successfully deploying a decoupled Next.js frontend and a heavy-duty Docker-orchestrating FastAPI backend under hackathon time constraints.
Overcoming "Whack-A-Mole": Transitioning from writing manual fixes for specific errors to implementing a generalized ReAct loop that allows the system to self-correct novel errors it has never seen before.
What we learned Agentic Engineering is about Tools, not Instructions: You can't tell an LLM how to fix every error. You have to give it the tools to investigate the environment and let it derive the solution itself.
Evaluation metrics must be airtight: If there is a way for an LLM to game your success criteria, it will find it.
Infrastructure as Code: The complexities of bridging serverless frontends with containerized backends taught us massive lessons in networking, CORS, and API resilience.
What's next for AuditFlow Distributed Training Audits: Scaling the Docker sandbox to handle multi-GPU environments for auditing large foundation models.
The Reproducibility Leaderboard: Creating a public dashboard that ranks top ML conferences and institutions based on the actual, verified reproducibility of their accepted papers.
Multi-Agent Diagnostics: Integrating alternative models (like Claude 3.5 Sonnet via LiteLLM) to act as a "peer reviewer" during the diagnostic loop, cross-checking the primary agent's proposed infrastructure fixes before executing them.

Log in or sign up for Devpost to join the conversation.