Inspiration
- We were inspired by Max Little’s work showing that 30 seconds of voice can contain rich biomarkers of Parkinson’s, and by how hard early diagnosis still is in practice.
- We wanted to explore whether we could package that idea into a simple, explainable tool that clinicians or patients could actually interact with—while being very clear about limitations and ethics.
The datathon theme and the availability of open Parkinson’s voice datasets (UCI, Kaggle, figshare) made it a perfect playground for combining ML, audio, and UX. Expand message.txt 6 KB
Inspiration
We were inspired by Max Little’s work showing that 30 seconds of voice can contain rich biomarkers of Parkinson’s, and by how hard early diagnosis still is in practice.
We wanted to explore whether we could package that idea into a simple, explainable tool that clinicians or patients could actually interact with—while being very clear about limitations and ethics.
The datathon theme and the availability of open Parkinson’s voice datasets (UCI, Kaggle, figshare) made it a perfect playground for combining ML, audio, and UX.
What it does
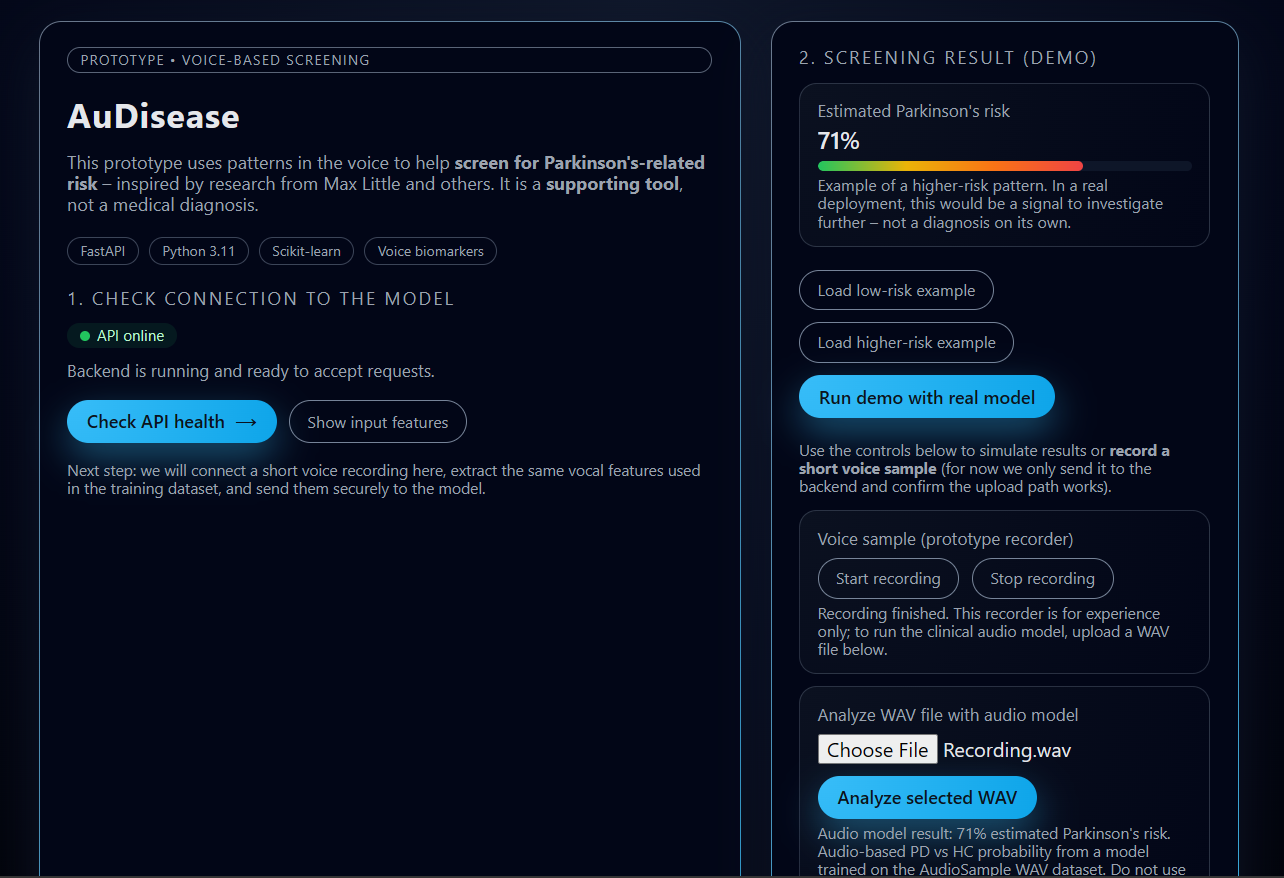
- AuDisease is a small web app where you can:
- Explore a tabular model trained on the classic UCI Parkinson’s voice dataset.
- Upload a WAV recording (healthy vs PD) from an open dataset and get an estimated PD vs healthy probability from an audio model.
- The frontend shows:
- A risk percentage bar with contextual text.
- The input features used by the tabular model.
- Controls to run a demo prediction and to analyze real WAV files.
- Under the hood, it uses:
- FastAPI for the backend.
- scikit‑learn for both tabular and audio models.
- A custom audio feature extractor for time/frequency statistics from WAV files.
How we built it
- Data & tabular model
- Loaded and cleaned the UCI Parkinson’s dataset (
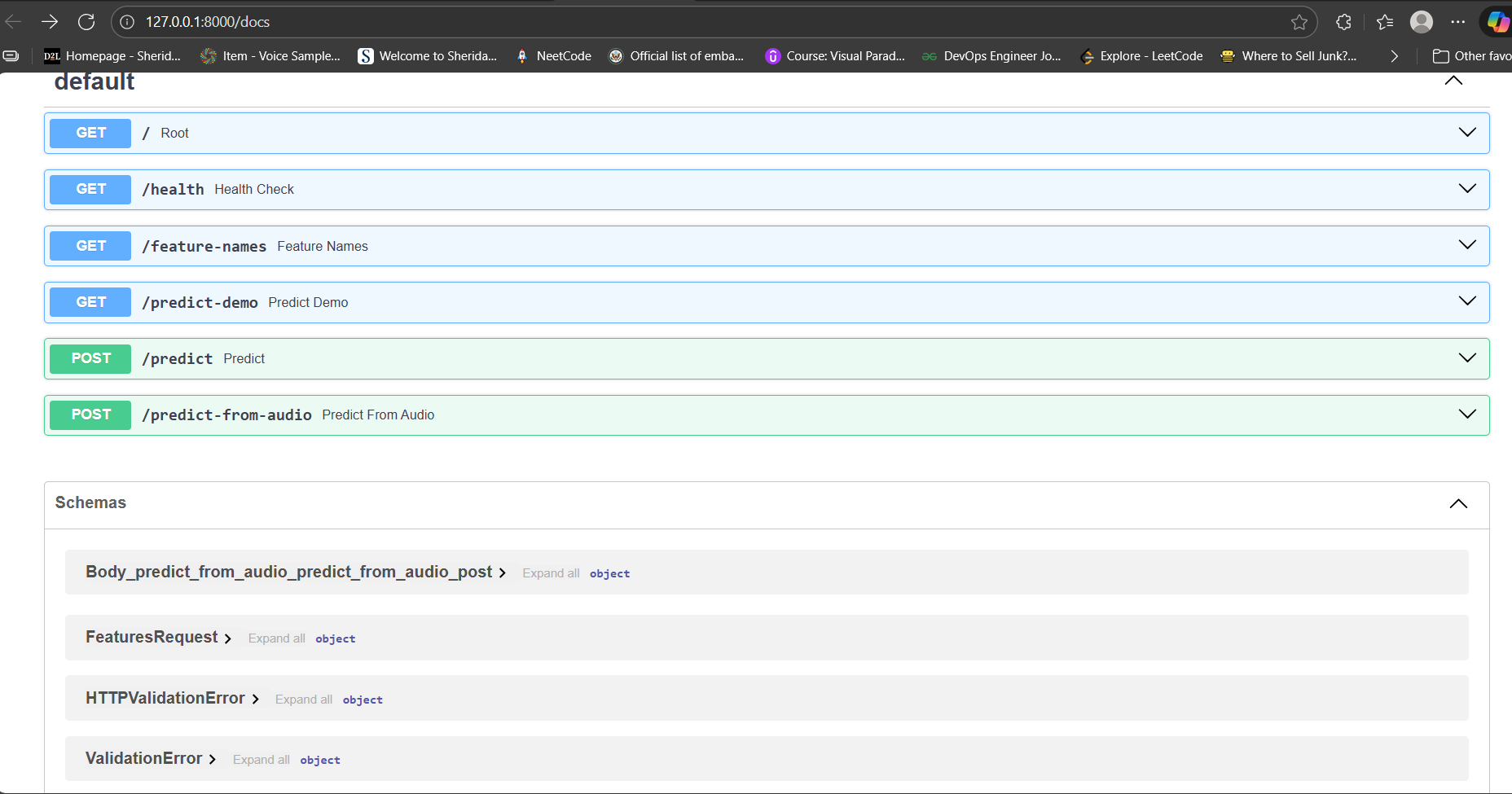
parkinsons.data), standardized features, and trained a logistic regression classifier for PD vs healthy. - Exposed it via endpoints like
/predictand/predict-demo.
- Loaded and cleaned the UCI Parkinson’s dataset (
- Audio dataset & model
- Collected WAVs from two open audio sources: sustained “aaa” vowels and longer read‑text / dialogue clips (HC vs PD).
- Labeled files by folder (
HC*vsPD*), extracted compact features (duration, energy, zero crossings, spectral centroid/bandwidth, etc.), and trained a RandomForest classifier for PD vs HC. - Saved the audio model and wired it to
/predict-from-audio.
- API & frontend
- Built a FastAPI app that serves both the API endpoints and a single‑page static frontend.
- The frontend can hit
/health,/feature-names,/predict-demo, and upload WAVs to/predict-from-audio, then update the UI in real time.
- Engineering practices
- Kept everything in small, readable Python scripts (
data_pipeline.py,train_baseline_model.py,train_audio_model.py). - Wrote a clear README and used
.gitignoreto keep heavy data and venv out of the repo.
- Kept everything in small, readable Python scripts (
Challenges we ran into
- No raw audio in the classic dataset
- The original UCI dataset only has pre‑computed features, so you can’t directly map a new microphone recording into those exact jitter/shimmer/RPDE values. We solved this by separating the tabular model from a new audio‑trained model.
- Audio format quirks
- Some WAVs used advanced encodings (e.g. WAVE_FORMAT_EXTENSIBLE / format 65534) that Python’s standard
wavemodule couldn’t read. We had to switch tosoundfileto robustly load them.
- Some WAVs used advanced encodings (e.g. WAVE_FORMAT_EXTENSIBLE / format 65534) that Python’s standard
- Generalization and calibration
- The audio model can output a high PD probability for a healthy person recorded on a different mic or in a different room. Communicating that this is “similarity to training data”, not a diagnosis, was crucial.
- Time constraints with cloud integration
- We started wiring in GCP (Cloud Storage, Gemini) but prioritized keeping the local demo stable and honest over fully deploying to the cloud.
Accomplishments that we're proud of
- Built a full end‑to‑end pipeline:
- From open Parkinson’s datasets → feature engineering → models → FastAPI API → modern frontend → interactive demo.
- Integrated real audio (not just static tables):
- Trained an audio classifier from open WAV datasets and made it usable through a simple upload interface.
- Maintained a strong focus on clarity and ethics:
- Clear messaging in the UI and README that this is not a diagnostic tool.
- Proper citations and dataset attribution.
- Kept the codebase approachable for non‑ML teammates:
- Small, commented scripts.
- Step‑by‑step README with venv setup, training, and run instructions.
What we learned
- Voice carries a lot of signal, but dataset context matters a lot:
- Models trained on one cohort + recording setup don’t automatically transfer to arbitrary microphones or languages.
- The importance of feature engineering for audio:
- Even simple features (energy, zero crossings, spectrum stats) can separate PD vs HC reasonably well on curated data, but richer features and calibration are needed for anything clinical.
- How to combine traditional ML + web APIs + frontend quickly:
- FastAPI + a static HTML/JS frontend is enough to deliver a very usable demo.
- How crucial it is to frame ML outputs:
- Users (and judges) need explanations, not just percentages.
What's next for AuDisease
- Better audio features & models
- Add more sophisticated vocal biomarkers (pitch tracking, jitter/shimmer approximations, noise ratios) and compare different models (e.g. gradient boosting, shallow neural nets).
- Calibration and evaluation
- Perform more rigorous validation: cross‑dataset tests, calibration curves, and error analysis on different speech tasks (sustained vowels vs read text vs dialogue).
- Cloud‑native deployment
- Finish GCP integration (Cloud Run + model storage in GCS), so the app runs as a hosted demo with proper access control and logging.
- Human‑centric explanations
- Hook in Gemini (or similar) to generate plain‑language explanations for clinicians and patients, summarizing what a given probability means and stressing that it is only a screening signal, not a diagnosis.
Built With
- fastapi
- numpy
- pandas
- python
- scikit-learn
- soundfile
- uvicorn


Log in or sign up for Devpost to join the conversation.