-
-
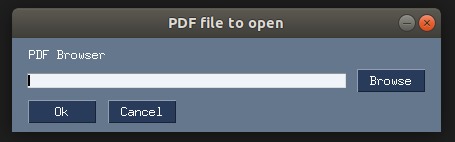
Interface to select a file.
-
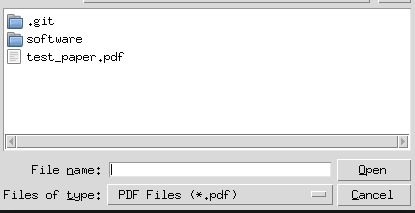
File manager to select the file.
-

The application GUI.


Inspiration
It is always very exhausting reading a lot of papers. But in order to be well-informed about the latest innovations and discoveries in any field it is import to read a lot of papers. Also, we tend to remember a lot more stuff when we listen to it rather than read. This is the reason we tend to like movies more when compared to reading books. :smiley:
What it does
This application GUI can work on any PDF file. Upon selecting a PDF file to use it generates a viewer which can used as a normal PDF viewer. But to activate the speech feature select the part of the text which has to be converted into audio. Once this is done the OCR (Optical Character Recognition) pipeline kicks-in which extracts the text from the selected area. The extracted text is then passed into a text-to-speech pipeline which converts the recognized text into audio. That's it !!. Sit back, Relax and Listen.
How we built it
The programming language used was Python. For the GUI pysimpleGUI is used which is a lighter version with tkinter support used to build beautiful interfaces. For the text-to-speech part google text to speech (gTTS) and the pygame mixer module is used. For parsing the PDF file and text extraction fitz library is used. All the development is done on Ubuntu 18.04
Challenges we ran into
It is always a challenge to parse research papers because of the presence of a lot of images and citations. Performing OCR on papers is also challenging because of the various formats of papers available. Finally, build a good and easy to use user interface is also key in an application like this.
Accomplishments that we're proud of
Never worked on GUI development before this and always wanted to build this particular application as it would make a lot of work easier. Feels proud to execute it like I envisioned.
What we learned
Learnt a lot related to GUI development which can be put to use for any further applications developed in future. Also learnt a lot regarding various libraries like pysimpleGUI, pygame, gTTS, fitz etc. Testing and debugging is also very important whenever a new feature is added.
What's next for AudioPaper
Currently the speech is still very robotic in nature. Would like to use Google's WaveNet which can generate more humanly voices. Also, the application currently does not parse equations which are a lot in research papers. There is still a long road ahead.


Log in or sign up for Devpost to join the conversation.