-
-
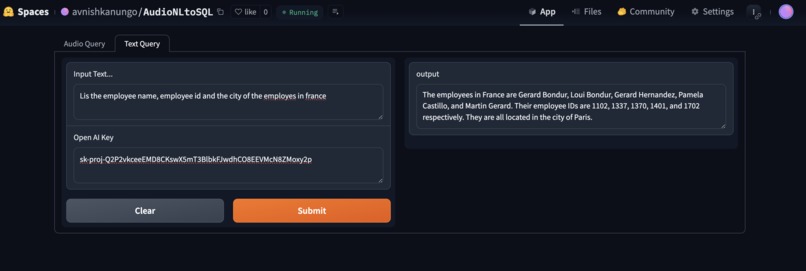
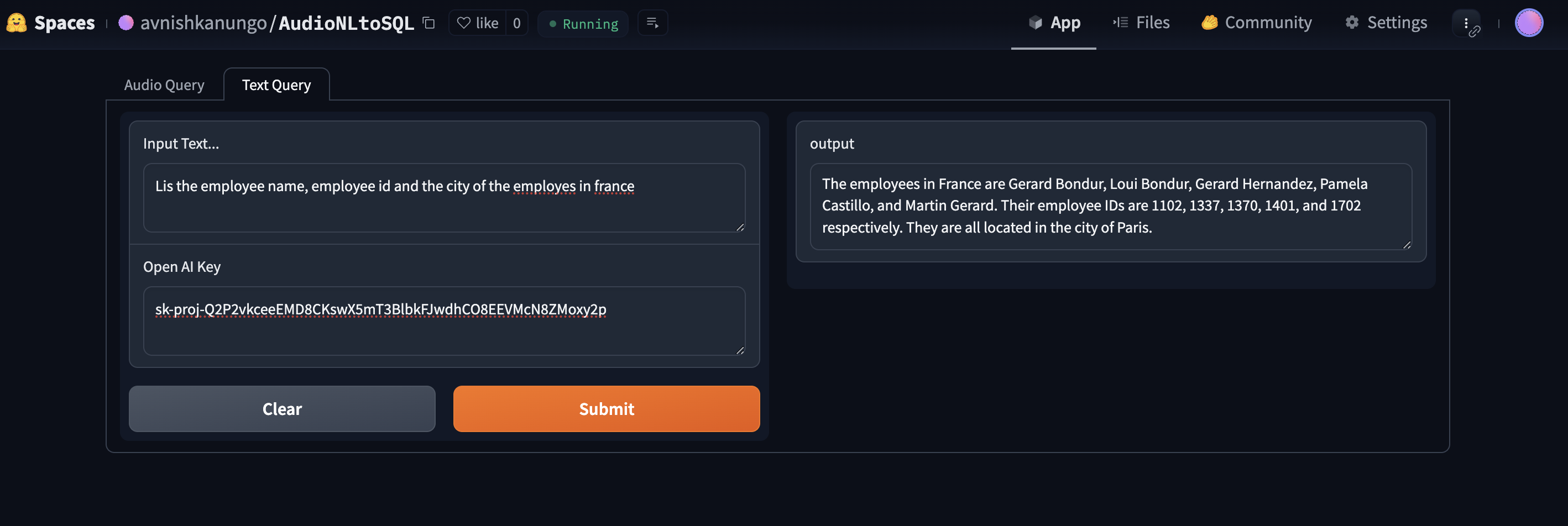
Text Query
-
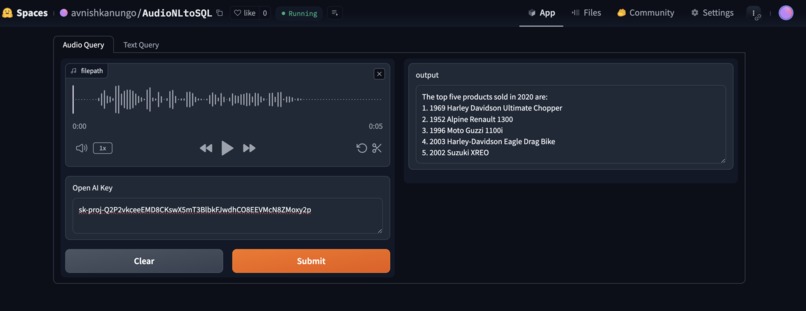
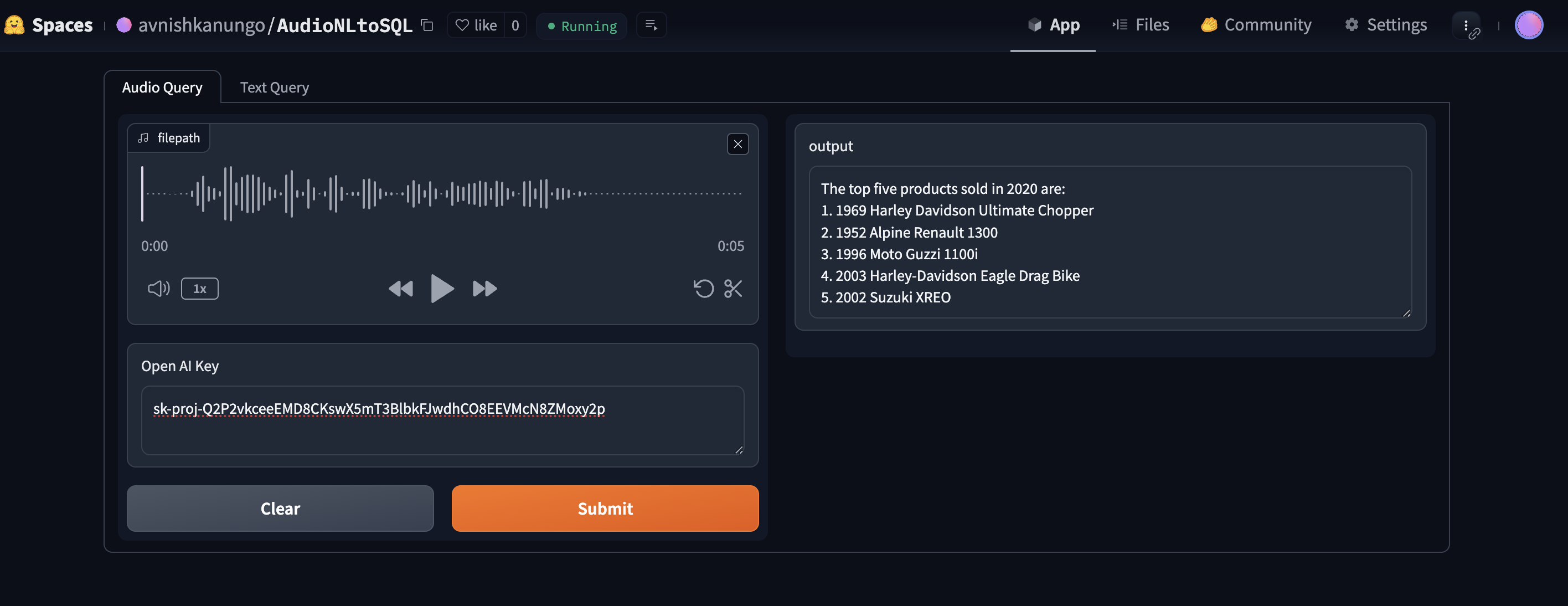
Audio Query
-
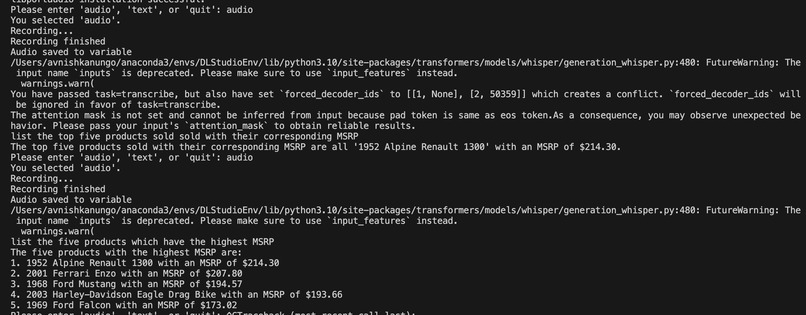
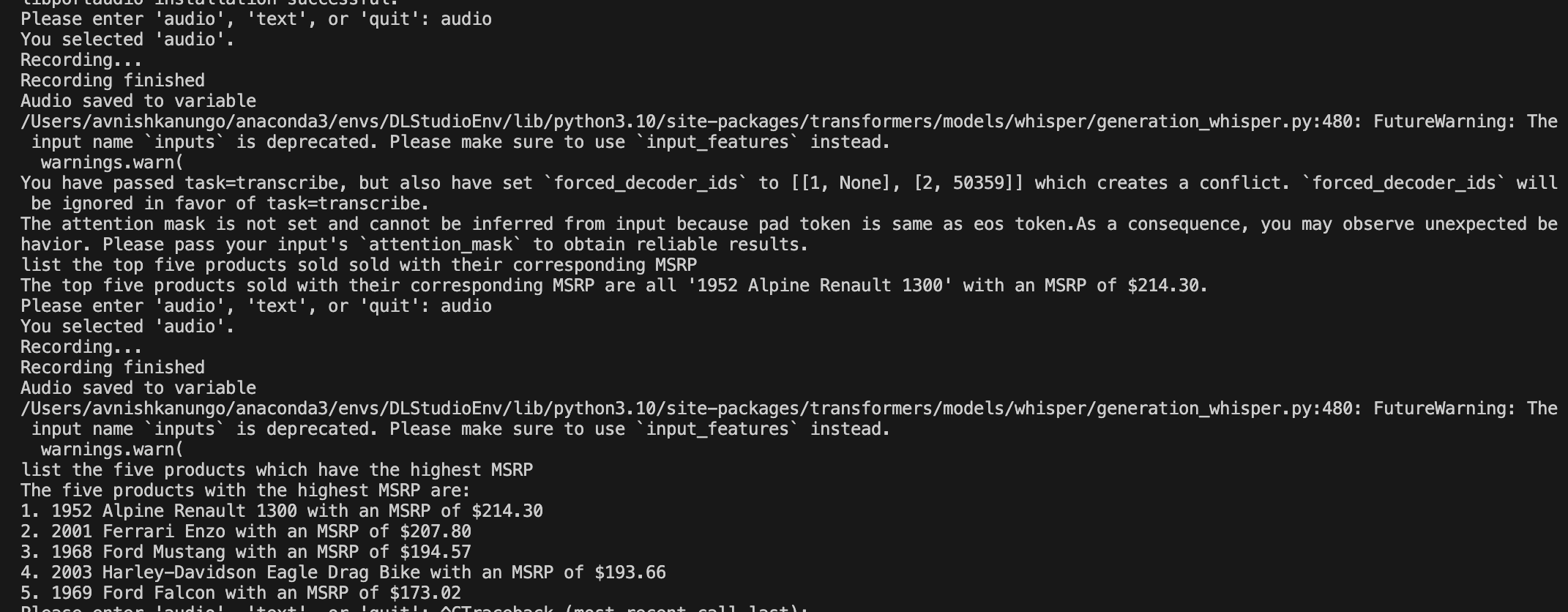
Audio Query in Terminal
-
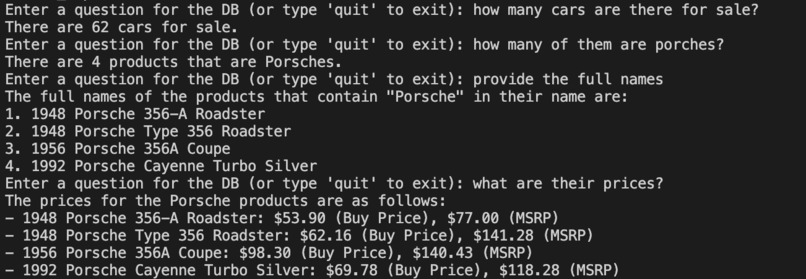
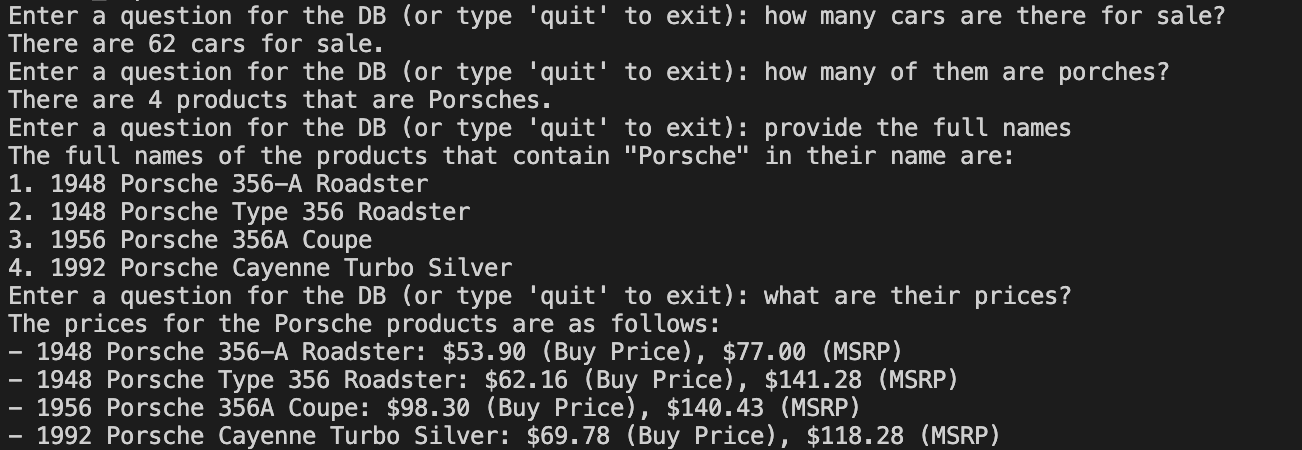
Text Query in Terminal
Inspiration
The inspiration for creating this project was to bridging the gap between natural language and technical database queries and to make the source of truth for information i.e the database more accessible to the layperson.
The idea came to me when I saw one of my friends who is a medical professional with very little technical skills pulling their hair out trying to access previous medical records for one of their patients to match with their current medical records, but the dashboard provided to them was extremely clunky and limited in the type of data that it allowed to be retrieved. Which led them to exclaim, how much better it would be if they could just talk to data that was sitting behind that dashboard.
This approach can even be extended to business environments whether its a sales person looking to get some textual insights from the data to put in a report or an analyst looking to pin point some kind of behavior or observation from the data. It can take up a lot of time to write cumbersome SQL queries.
In the end Free form audio conversation or chat in such cases is a much more efficient way to interact with the data for non-technical audiences, even better than using a dashboard or UI, which in itself also has a learning curve and can still be a source of inconvenience to people not well versed in its operation.
What it does
My project, AudioNLToSQL, provides a way to converse easily with your database. It allows you to directly record audio asking questions to the database which the database responds to with the required information, and it also allows a free form text based approach, where you can just type in your question and it will provide you the required information
How I built it
To build this I have utilized NLP and Audio Processing techniques using the tools, models and APIs provided by OpenAI and HuggingFace. I trained an english transcribing model using HuggingFace Transformers library, the transcribed text from which was fine-tuned using Langchain with OpenAI APIs being used in the backend. The OpenAI model was further fine-tuned using the few shot learning approach by providing it more information about the database and examples of natural language questions and modeling the prompts given to the GPT 3.5 model to increase the context using the examples and information about the database.
Challenges I ran into
The first challenge that I ran into was how I can make the OpenAI model give answers specific to the database that is connected to and not just generic SQL queries which would give an error when run on the connected database. This was solved by fine tuning the model using the few shot learning approach and giving it example queries and information related to the database.
Creating a demo application on the web accessible to all. For this, I have used Gradio, a hosting platform provided by huggingface and a dummy MySQL database hosted on AWS RDS, accessible to the app using Pydantic via its langchain connectors.
The project also has a script, that a user can clone and use on a local mysql database, for the same implementing the correct software package installation validation in our scripts was necessary.
Accomplishments that I am proud of
The accuracy of the transcribing model(Automatic Speech Recognition) which allows for the Audio module to work. It was trained without a GPU on 4 parallel CPUs and provides around 95% WER accuracy.
The seamless automation that has been implemented which handles the flow of information from Audio to text to conversion to SQL Query and finally that query being run on the server and the information being retrieved, with <15 seconds of wait time.
Integration of multiple different modules handling things from speech recognition, natural language understanding and conversion and code automation to provide a user experience that is not cumbersome and easy to understand.
What I learned
The power of langchain in facilitating the automation and integration of disparate technical module in a seamless flow.
How much fine tuning using few shot learning can positively affect the accuracy of an LLM for working on a specific application.
The convenience and speed the HuggingFace platform provides in accessing and preprocessing of even the most complex of datasets, which allows us to focus on optimization and modeling tasks.
Hyperparameter optimization and its importance when working in resource poor environments.
What's next for AudioNLToSQL
I want to train a text to speech model which will then have an option to provide the output in an audio format too.
Build an agentic workflow connecting the database to reporting and visualization scripts to generate full fledged reports and workflows that allow actions to be taken or alerts to be sent on the basis of the queries that are made to the db using the system.
The project works great for basic queries, but for more complex queries requiring nested queries and multiple joins, the accuracy of the output is somewhere around 70-75%. For the same, I would want to perform more extensive finetuning of the LLM being used(GPT 3.5 Turbo in the current implementation).
Current Demo Link: https://huggingface.co/spaces/avnishkanungo/AudioNLtoSQL
You will need an Open AI API Key for running the demo correctly.
Built With
- huggingface
- langchain
- mysql
- openai
- prompt-engineering
- python
- pytorch
- sqlalchemy









Log in or sign up for Devpost to join the conversation.