-
-
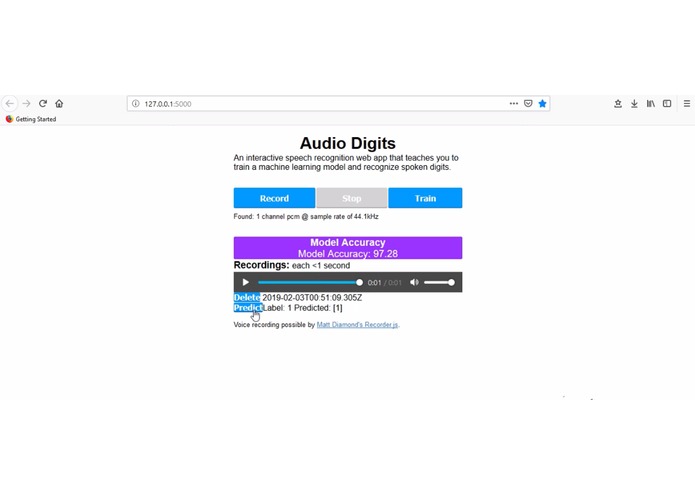
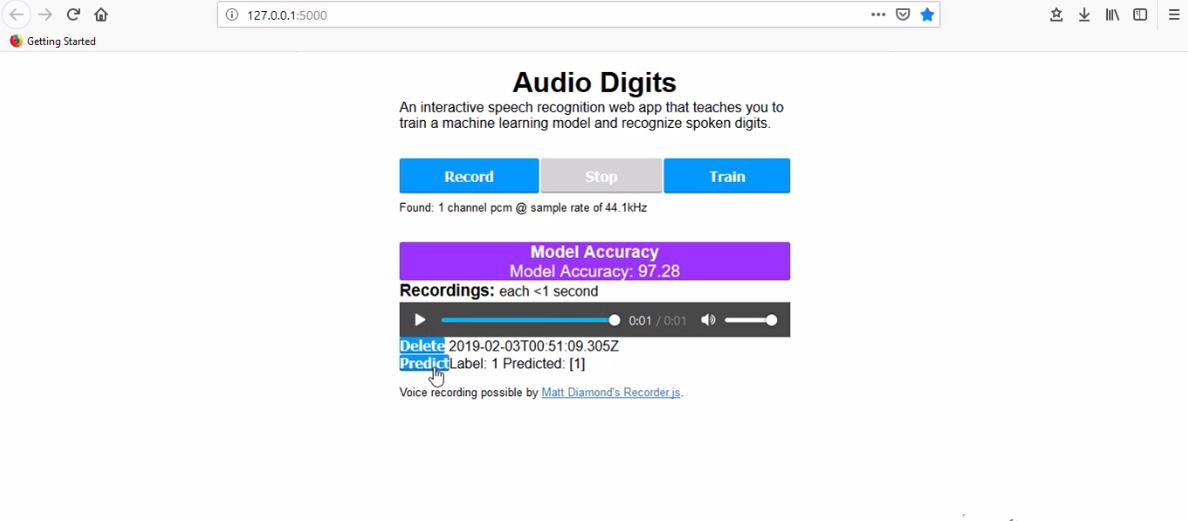
AudioDigits predicting a recording
Inspiration
Any company can leverage data science and machine learning to add value but few succeed. Perhaps this is because decision makers have a misconception that fancy algorithms are self-contained solutions; in goes some data and out comes an answer. It shouldn't be like that. Data science and machine learning techniques are tools that must be understood to be used effectively. If companies better understand these tools then they can make decisions that leverage the value of data science and machine learning.
What it does
Audio Digits is an interactive speech recognition web app that teaches you to train a machine learning model and recognize spoken digits.
How we built it
AudioDigits was built in 1 week by 2 University of California San Diego students who wanted their previous machine learning python research to be more accessible.
Challenges we ran into
There have been many implementation challenges up to this point including a lack of knowledge of javascript, html, and css. There was also a point where we followed a tutorial that included Docker and learning those basics was more than we had asked for. A few design challenges persist. For the moment an inconsistent audio sample rate, audio recording length, and a small training set for the machine learning model prevent the first iteration of this product from predicting well. Moreover the model’s prediction is sensitive to audio sample rate and the choice of software used for recording: audacity v.s. recorder.js
Accomplishments that we're proud of
Alec and Mingcan are proud of completing their goal and delivering an immersive web app that demonstrates speech recognition machine learning. They are also proud to learn about audio signal processing techniques for speech recognition.
What we learned
Alec and Mingcan learned that web development is challenging because a developer must optimize multiple pipelines while also improving user experience and sometimes these two are directly opposed.
What's next for AudioDigits
Future feature improvements include: clipping the audio files only where there is sound (rn sound capture isn’t immediate), allowing user recorded data to be used as training points, and using librosa to compute the mfccs.
Log in or sign up for Devpost to join the conversation.