-
-
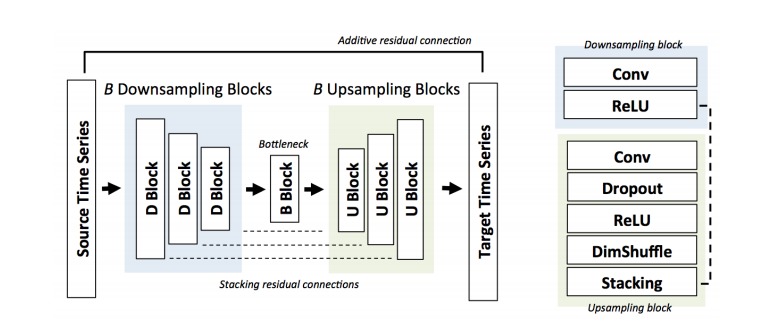
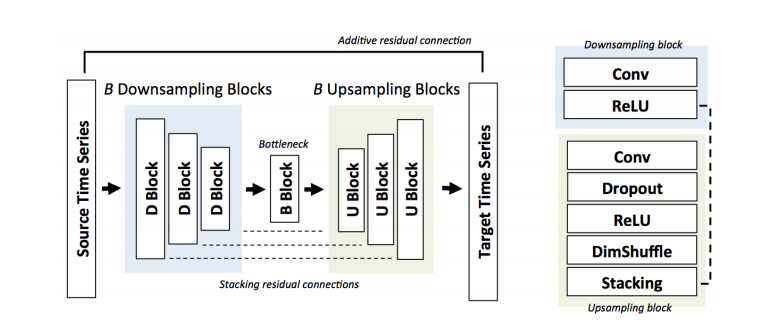
courtesy of Stanford University
-
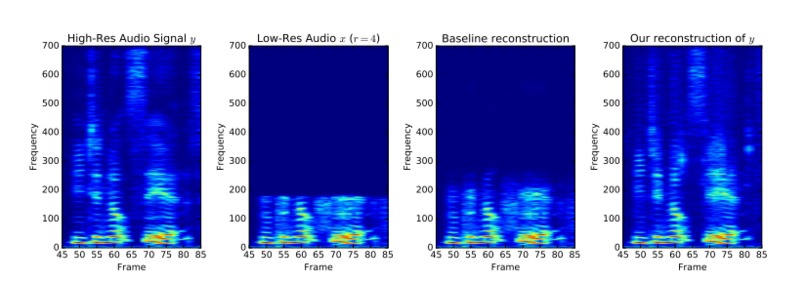
courtesy of Stanford University

Inspiration
It was inspired by the paper Audio Super Resolution presented in ICLR by Kuleshov et al. We feel that this application is an extremely unique and important application of Deep learning. The uses of this code can be extended to everyday issues of inaudibility while talking on the phone, the voice in videos and even in the Justice system.
What it does
It increases the sampling rate of signals such as speech or music using deep convolutional neural networks. Our model is trained on pairs of low and high-quality audio examples; at test-time, it predicts missing samples within a low-resolution signal in an interpolation process similar to image super-resolution. Our method is simple and does not involve specialized audio processing techniques
How we built it
We used the PyTorch framework. We implemented Audio U Net in it from the PyTorch library.
Challenges we ran into
Challenges were processing was extremely computationally heavy. Preprocessing audio signals was tough and uncommon. Handling wav files and sending them through was the neural network was a new experience and something we struggled with alot.
Accomplishments that we're proud of
The model was running successfully, proud to have made an end to end model on Audio Data.
What we learned
Learned alot about PyTorch from implementing model to parallel processing. We Also learned about handling wav files.
What's next for Audio-Super-Resolution
We plan to implement a Variational Autoencoder to upsample the file and compare the results with the current model.
Built With
- anaconda
- audio
- github
- python
- pytorch
- sublime-text

Log in or sign up for Devpost to join the conversation.