-
-
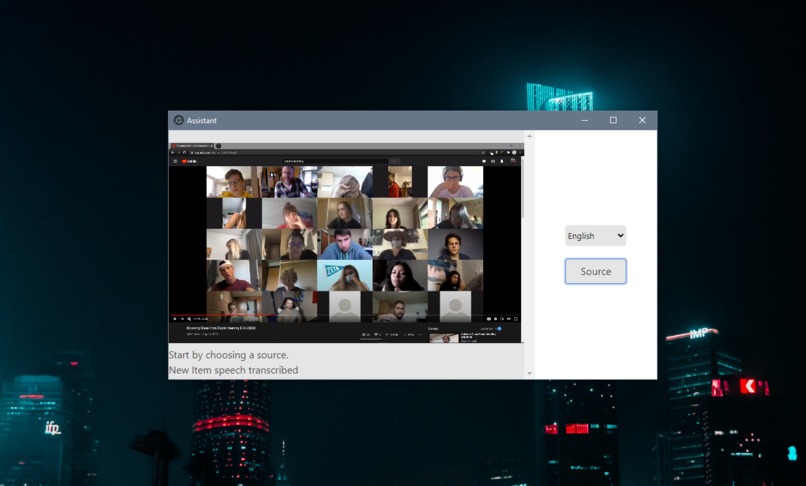
Speech-to-Text from Live Screen
Inspiration 💡
Now on days, every meeting seems to be over the internet. Lectures occur in BlackBoard Ultra, Google Classroom, Zoom, and many other platforms that do not offer live captions.
We wanted this application to focus on three main topics,
- Providing accessibility
- Improving Communications at school and work place
- Increasing diversity in STEM
The current circumstances we now live in have further decreased the accessibility of content for disabled people. According to the National Deaf Center, 3.9% of students are deaf in the United States and because lectures are primarily online they are encountering new challenges.
This application is not only targeted for students but also for professional workers that may have to attend multiple meetings an idea and may have a hard time keeping track of their notes. Lastly, this application offers live speech-to-text translation, allowing users to seamlessly choose the language that generates the captions.
We wanted to allow international students to be able to gain more accessibility to lectures now that everything is online, furthermore, we wanted to provide different languages for non-English speakers.
We feel that in the current state of the world having a personal scribe for our digital life that can also connect the world further through translation and other features will be a powerful tool.
What it does ⚙️
This application lets you choose audio sources and stream the audio to google cloud for live speech to text and translation purposes.
It works by capturing a desktop window in a GUI and streaming the audio of it to a NodeJS server process. It initially accomplishes text to speech but other APIs can be layered on top such as the translation function and other Google APIs.
With the use of Electron, we were able to create a user-friendly GUI that allows users to simply select a language (default English) and an audio source, and then it will start generating captions automatically.
How We built it 🛠️
- Electron JS
- Node JS
- Google Speech-To-Text API
- Google Translate API
Challenges we ran into 🚧
- Fast audio translation requires low latency operations so we had to opt for websockets
- Desktop window capture is OS dependent and we had challenges targeting the app audio stream
- Ultimately we sent our stream contents to google cloud, but due to an encoding error when transforming the app audio stream to a format the Speech to Text API takes we sent data that was unable to be processed (AudioProcessor.js).
- As a fallback to the above problem we wrote a python server (App.py) that caches the audio stream to a file and then sends it over. This works, unfortunatly we did not have time to integrate this server into the desktop application.
What's next for Audio Scribe 🚀
What we would like to accomplish next for Audio Scribe is to offer more productivity features such as
- implementing a keyword highlighter so anytime an important word is said it will highlight it in the scribed
- provide a Record feature that records the video and the captions
- create am user Dashboard to allow personalization



Log in or sign up for Devpost to join the conversation.