-
-

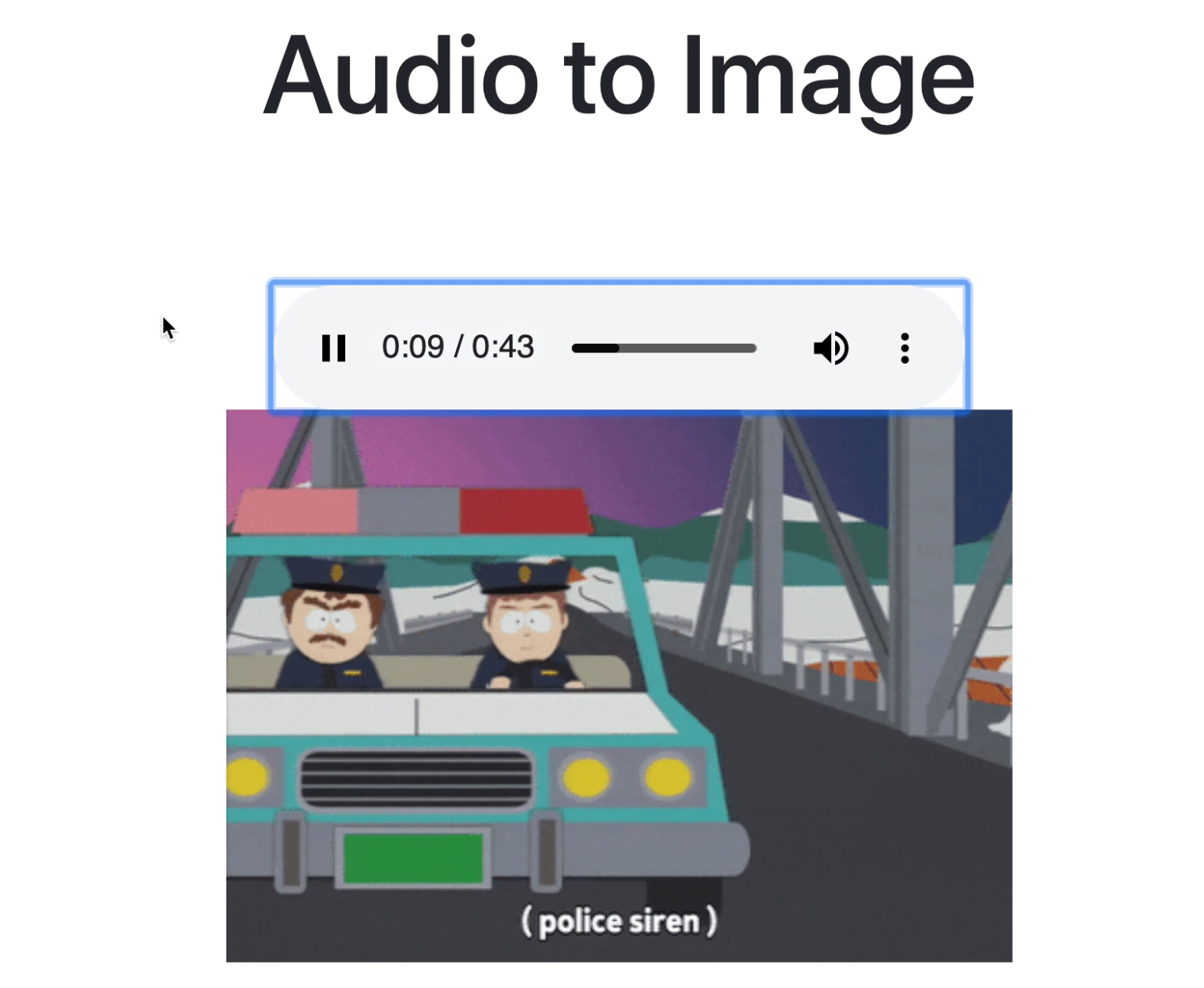
GIF of car shows up when the audio contains a car sound
-

-

-
-



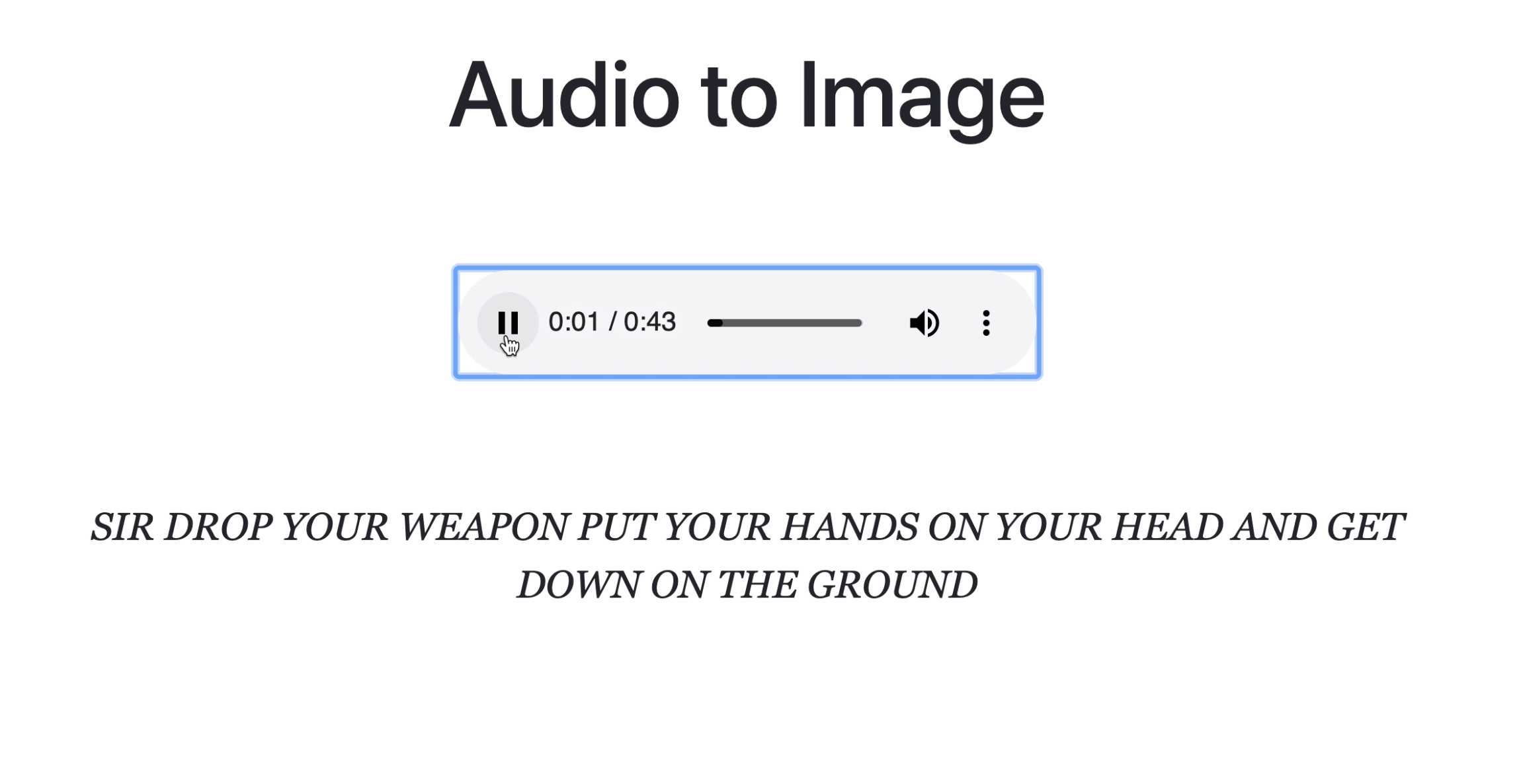
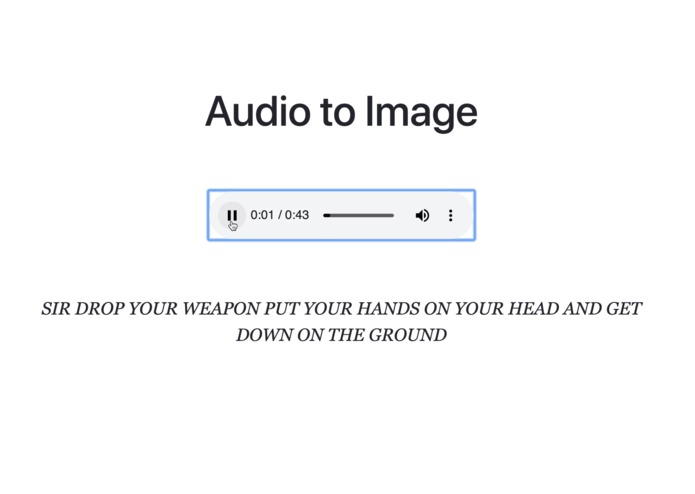
Speech-to-text is great, but why stop there? There's a lot more to audio than just words. That's where AUDIMEXT (AUdio to IMage and T*EXT*) comes in! Just upload an audio file, and watch your screen come to life with text and GIFS based on words & sounds respectively.
We see tremendous utility for AUDIMEXT in the following areas:
For people with hearing impairments, helping them not just understand what is being said, but also showing them what's happening around them visually (cars passing by, dogs barking, police/ambulance sirens, and even gunshots).
To enhance any audio-only form of media by augmenting it with relevant images, GIFs and text (as shown in the example)
Demos:
- Video demo: https://youtu.be/DCGZrzyA1QM
- Live demo: https://pyhack-2019.firebaseapp.com [When you click upload, certain scripts may be blocked because of HTTP-based APIs. Please allow insecure scripts from the URL bar: https://i.imgur.com/NFS20Om.png ]
What it does
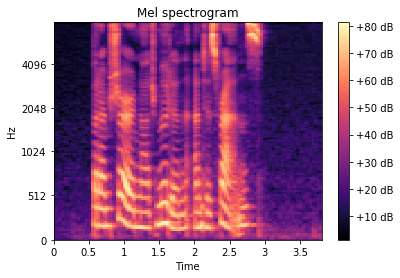
It detects speech and other sounds from audio. Speech is converted to text, and other sounds (cars, dogs, sirens, construction work, gunshots etc.) are displayed as images or GIFs.
How we built it
It's a web application backed with a 2-stage model:
- An audio file is uploaded via a web-application (React JS) and sent to a web-server, which is powered by Flask
- The audio file is split into small clips of 2-4 seconds for further processing
- Each of the clips is classified as someone speaking, or one of 10 sounds using a CNN-based classifiers.
- For speech clips, they are converted to text using a torchaudio model.
Challenges we ran into
- Training a single model for classifying both speech and other sounds was tricky.
- We were only able to train on a dataset where we could detect one type of sound at a time.
- torchaudio was released just yesterday, and it took us some time to figure it out, and integrate it into a webserver.
Accomplishments that we're proud of
- Setting up an end-to-end pipeline with a web application, two deep learning models & multiple levels of intermediate processing in under 24 hours.
- Working together with people we barely know, sharing ideas and helping each other, we were able to achieve much more than any of us individually could have.
What we learned
- Torchaudio - though it was difficult to get started as we were new to it, but it seems like a really powerful addition to the PyTorch family.
What's next for Audimext
- We'll polish it, improve the classification model, possibly add more classes
- We'll train a multilabel classifier to identify overlapping sounds, and also try to segment/separate out individual sounds.







{kind=link}
Log in or sign up for Devpost to join the conversation.