-
-
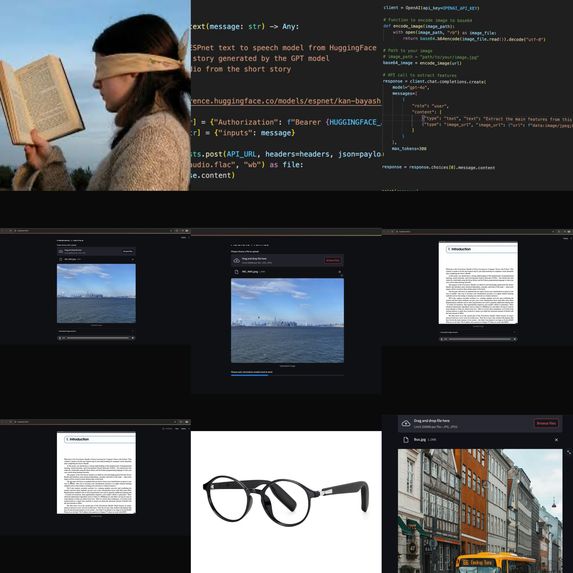
This is a collage of our project with screenshots.
Inspiration
It is useful for the visually impaired.
What it does
The model can generate an audio from the image. It first converts an image to text then to audio.
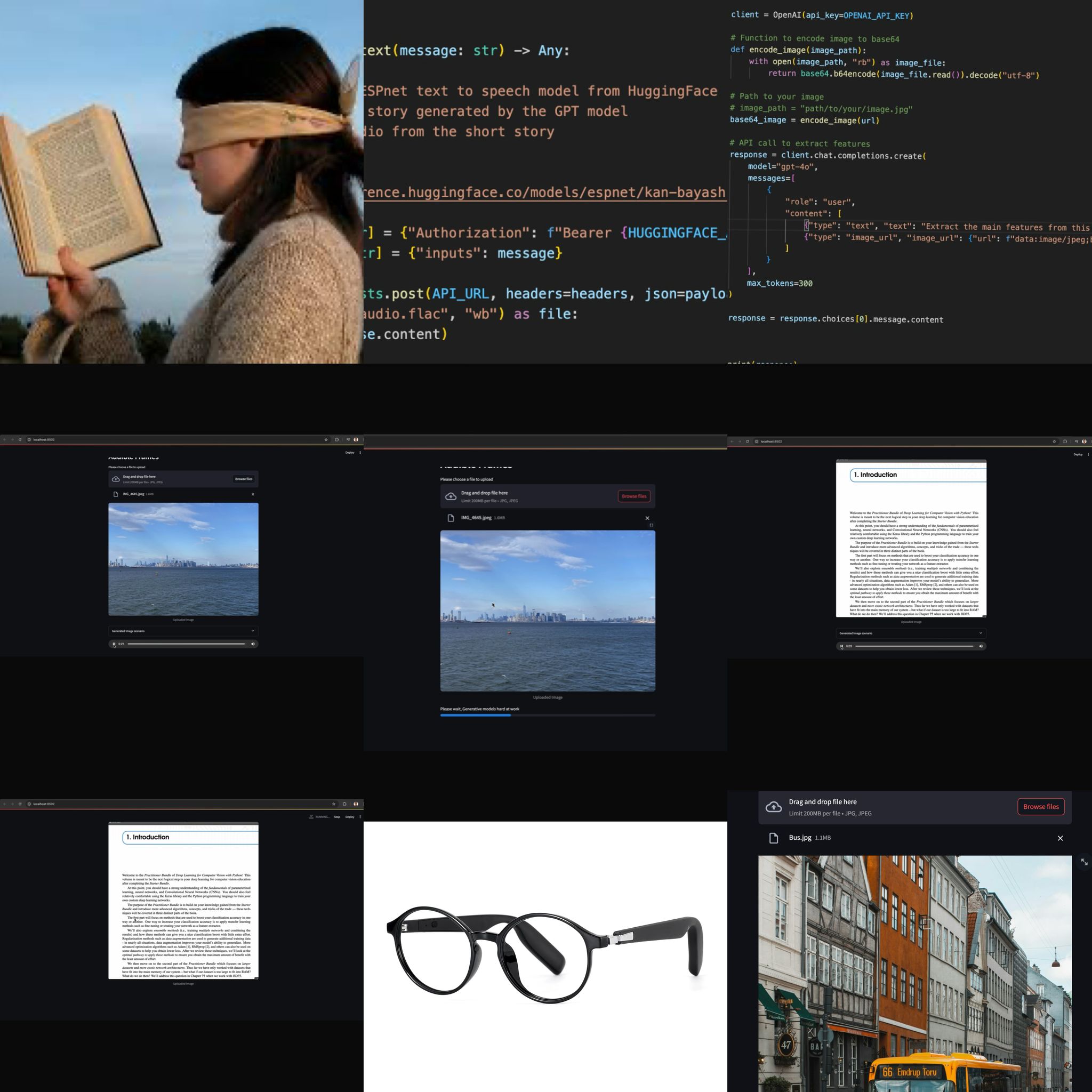
How we built it
We used GPT 4-o model from OpenAI for caption generation on the image. In addition, we used ESPnet model to convert from text to audio.
Challenges we ran into
Accessing a valid API to use Open AI models was a challenging.
Accomplishments that we're proud of
Our model successfully identified and described the Statue of Liberty in an image where it appeared very small.
What we learned
We learned to access API for using OpenAI models and to fine tune large language models.
What's next for Audible Frames
Envisioning smart glasses that capture images and provide real-time auditory descriptions to assist visually impaired individuals.
Built With
- espnet
- gpt
- openai
- python


Log in or sign up for Devpost to join the conversation.