-
-
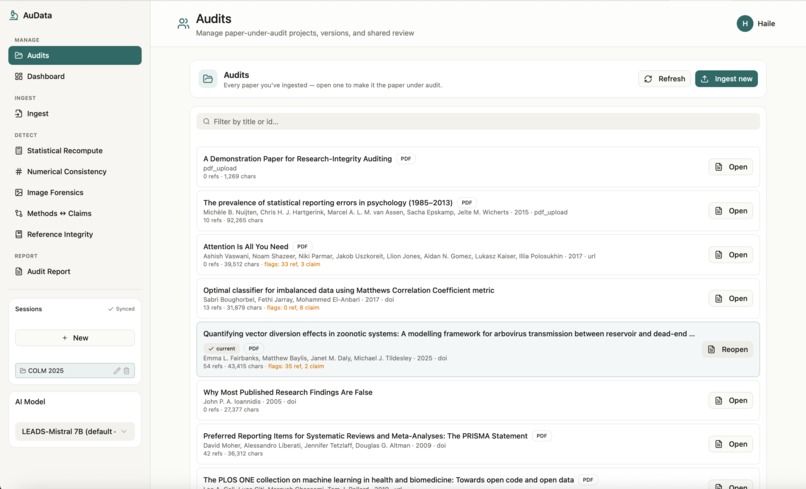
AuData
-
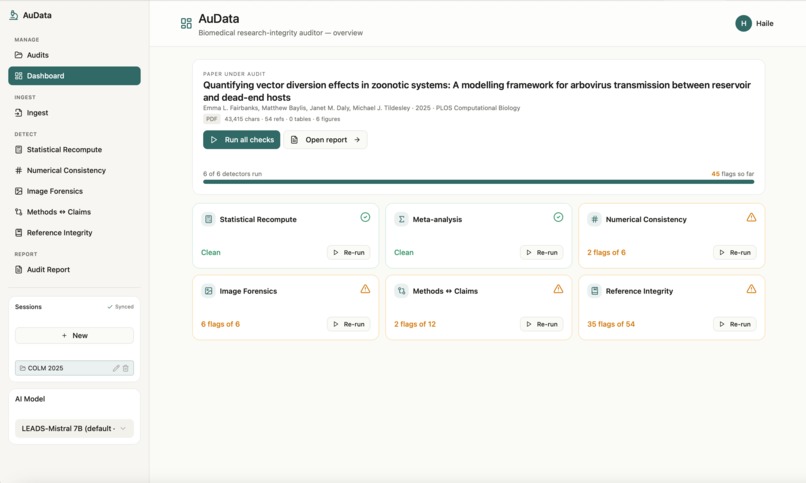
Dashboard
-
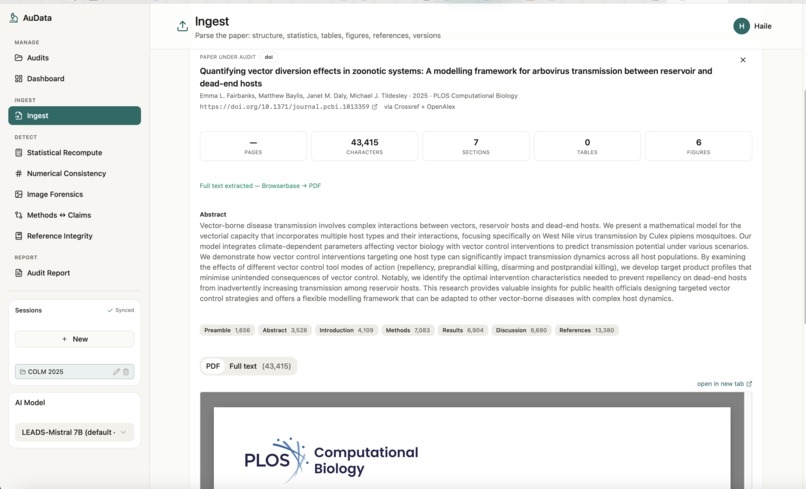
Ingest Page
-
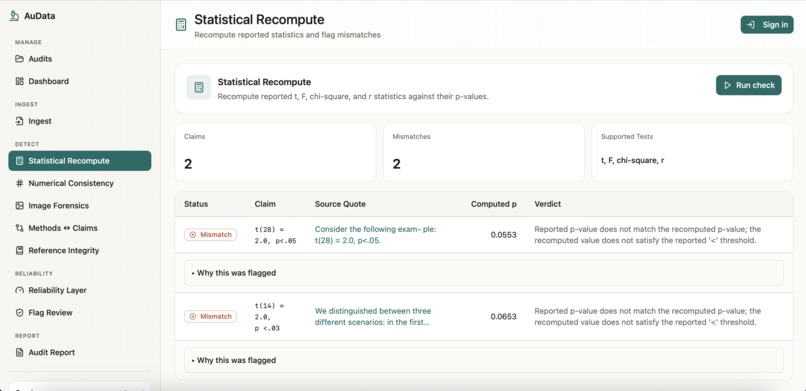
Statistical Recompute
-
Numerical Page
-
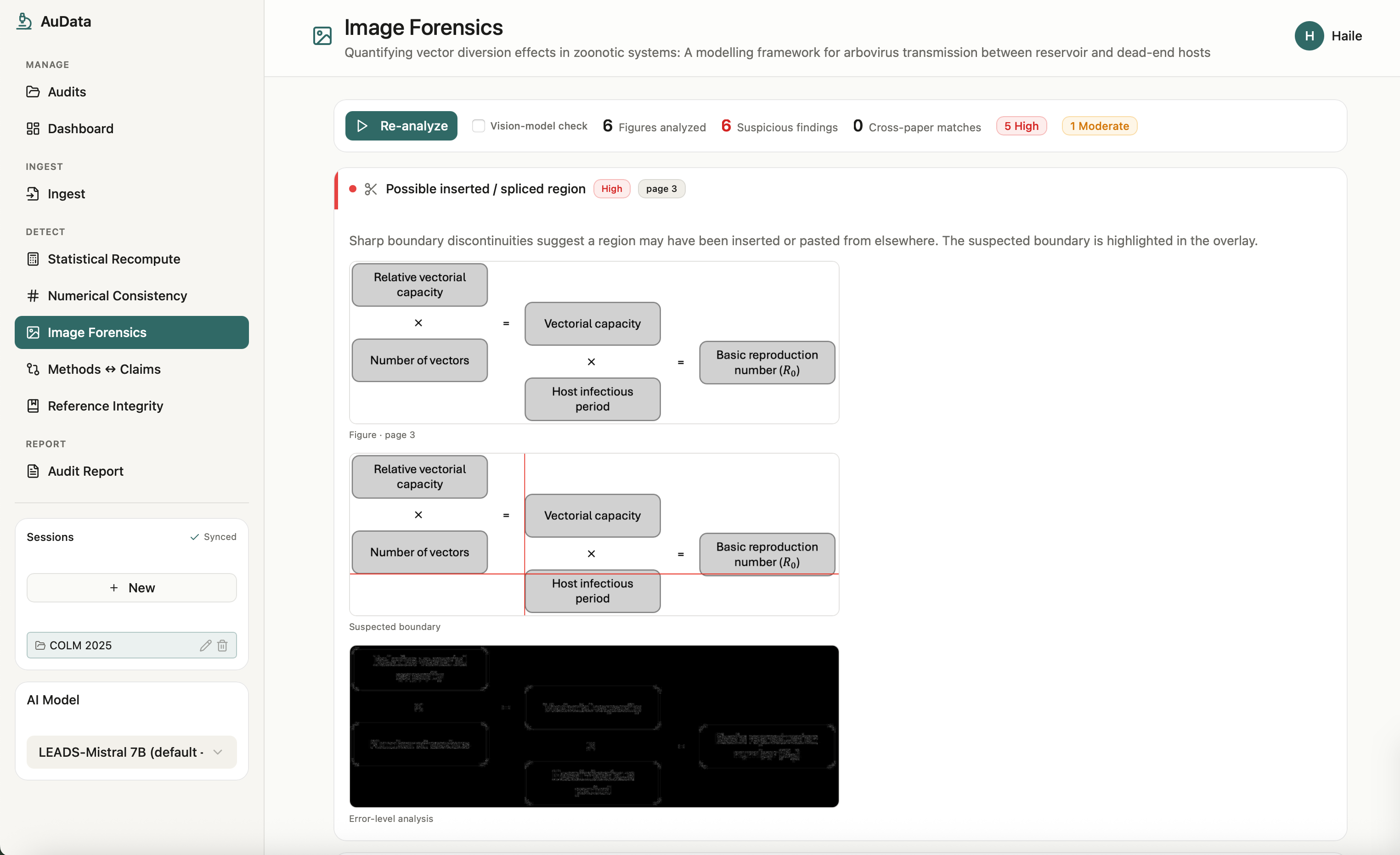
Image
-
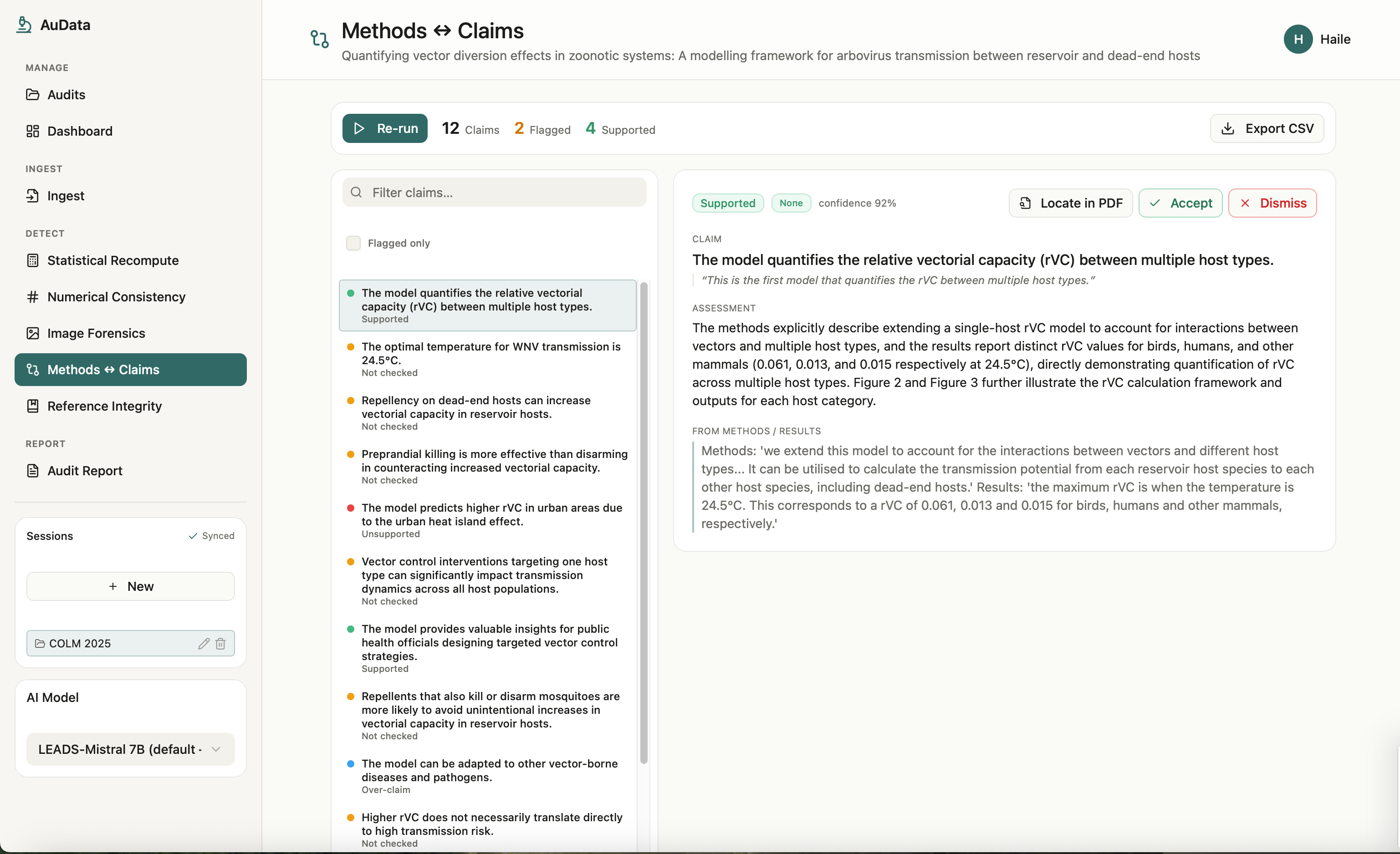
Methods and Claims
-
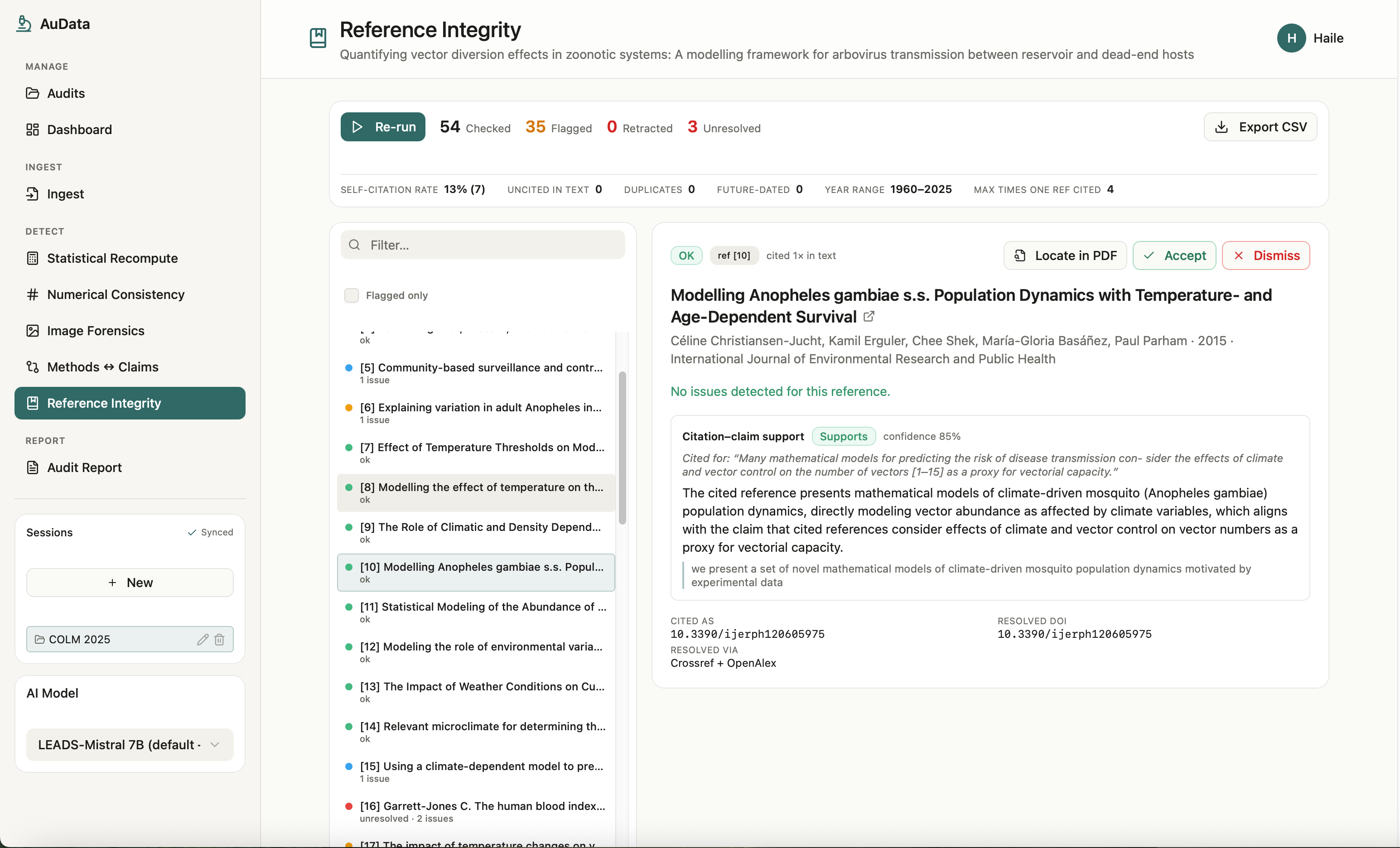
Reference
-
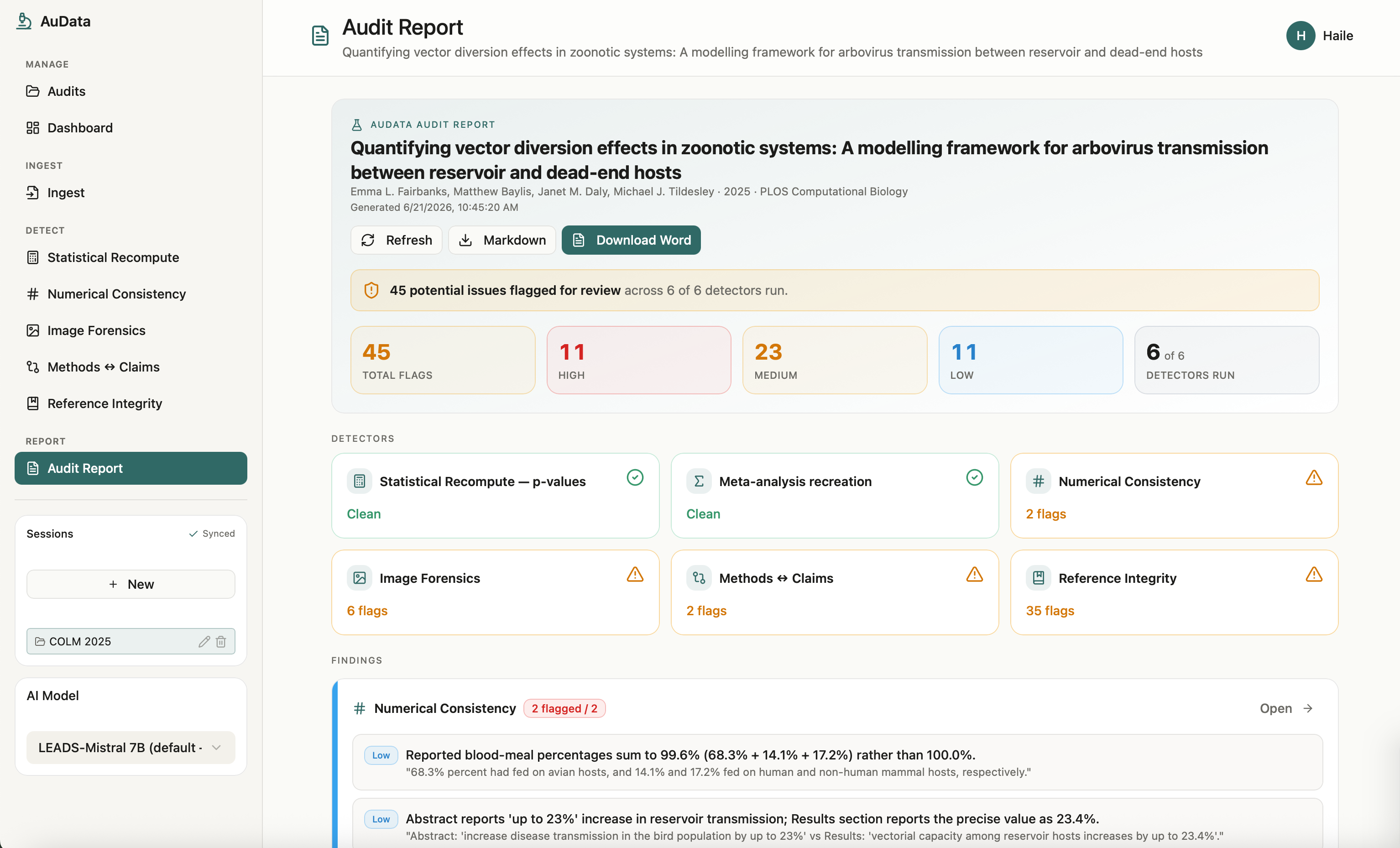
Audit Reports
-
Reports
-
Technical Architecture
Inspiration
Science runs on trust, but that trust is getting harder to verify by hand. Some of the most consequential errors of the last two decades hid in plain sight: the 2006 Nature paper that helped anchor the amyloid hypothesis of Alzheimer's disease was found in 2022 to contain manipulated figure panels, after steering years of work and enormous funding. Stanford's president stepped down in 2023 over image-integrity problems in his labs' papers, and in 2024 Dana-Farber moved to correct or retract dozens of studies flagged for duplicated images. These are not one-offs. The automated tool statcheck found that roughly half of psychology papers contain at least one statistical reporting inconsistency, and Retraction Watch now tracks more than 50,000 retractions.
At the same time, the volume of research has outrun our ability to read it. Millions of papers appear every year, PubMed alone adds over a million, and generative AI is accelerating both legitimate writing and outright fabrication, including industrial-scale paper mills. Peer reviewers are unpaid and overstretched, and no human can realistically recompute every p-value, re-derive every meta-analysis, or visually compare every figure against the prior literature. The community is starting to respond: venues like ICLR and NeurIPS have begun piloting AI-assisted peer review, and research shows large language models can already give useful, structured feedback on manuscripts. AuData was built for exactly this gap. Small inconsistencies, a wrong p-value, an impossible sample size, a misleading citation, a duplicated figure panel, quietly corrode the scientific record, and catching them at the scale science now operates demands machines working alongside human reviewers.
What it does
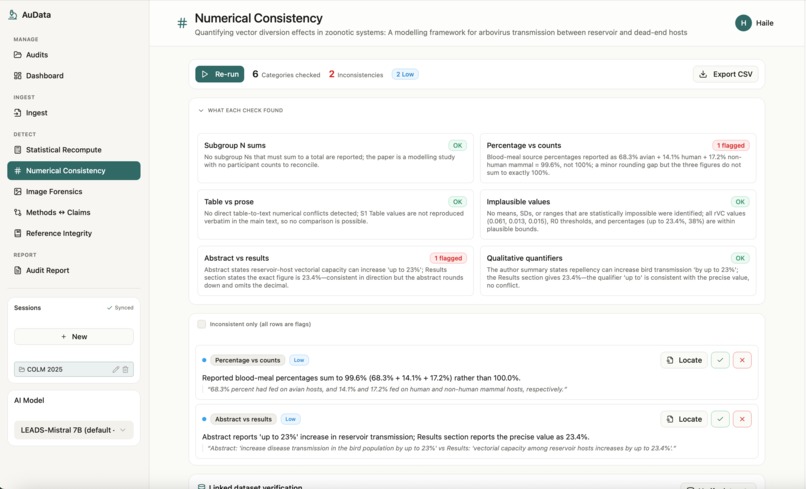
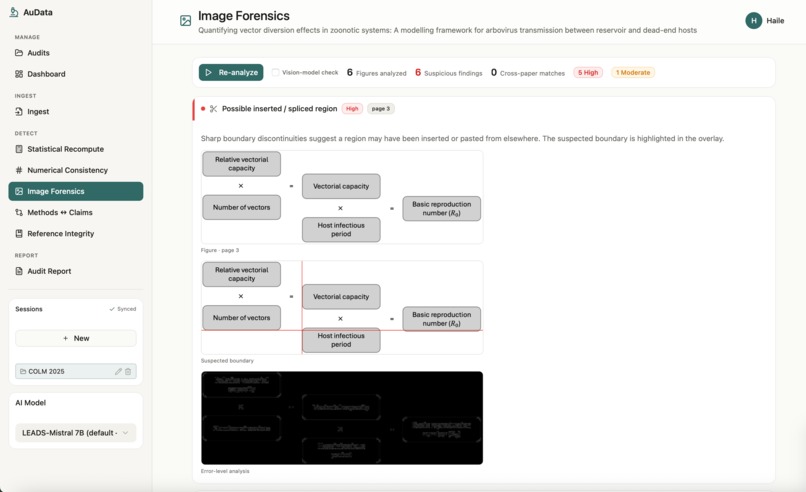
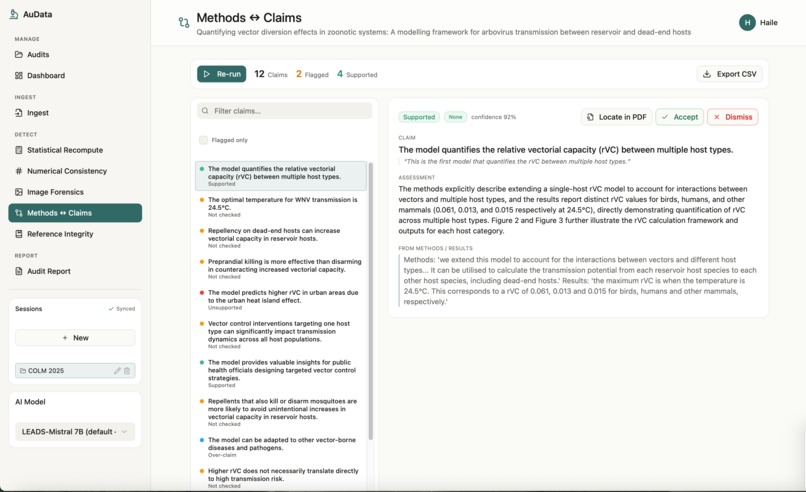
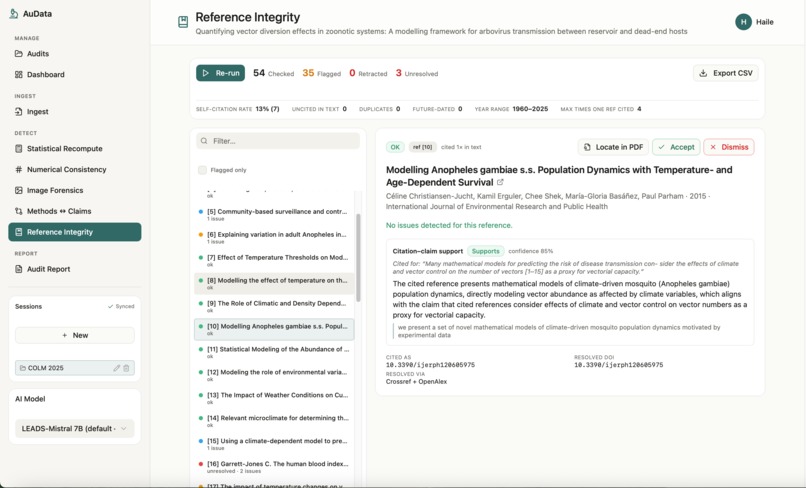
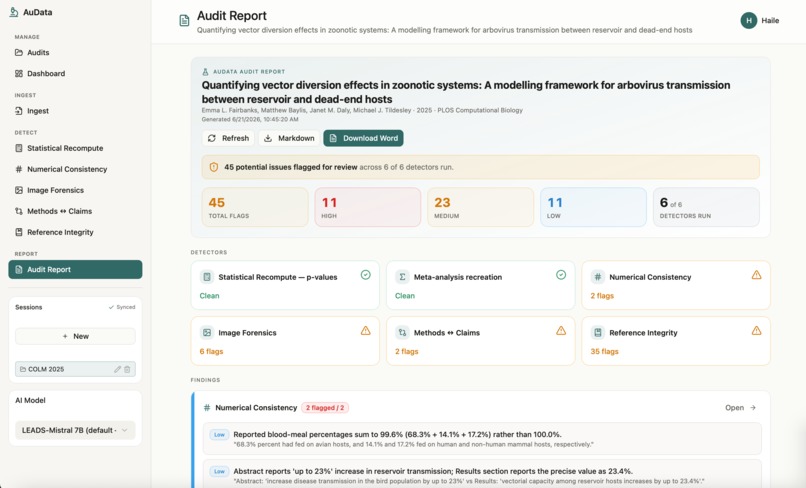
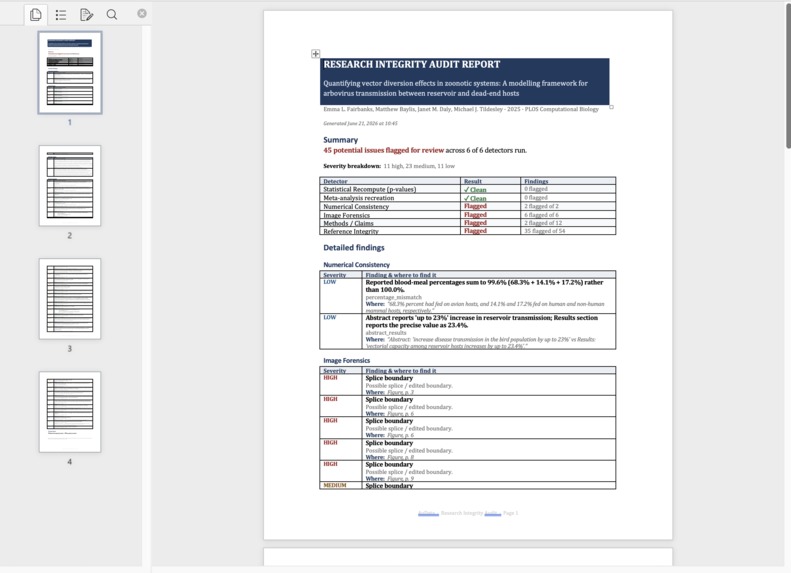
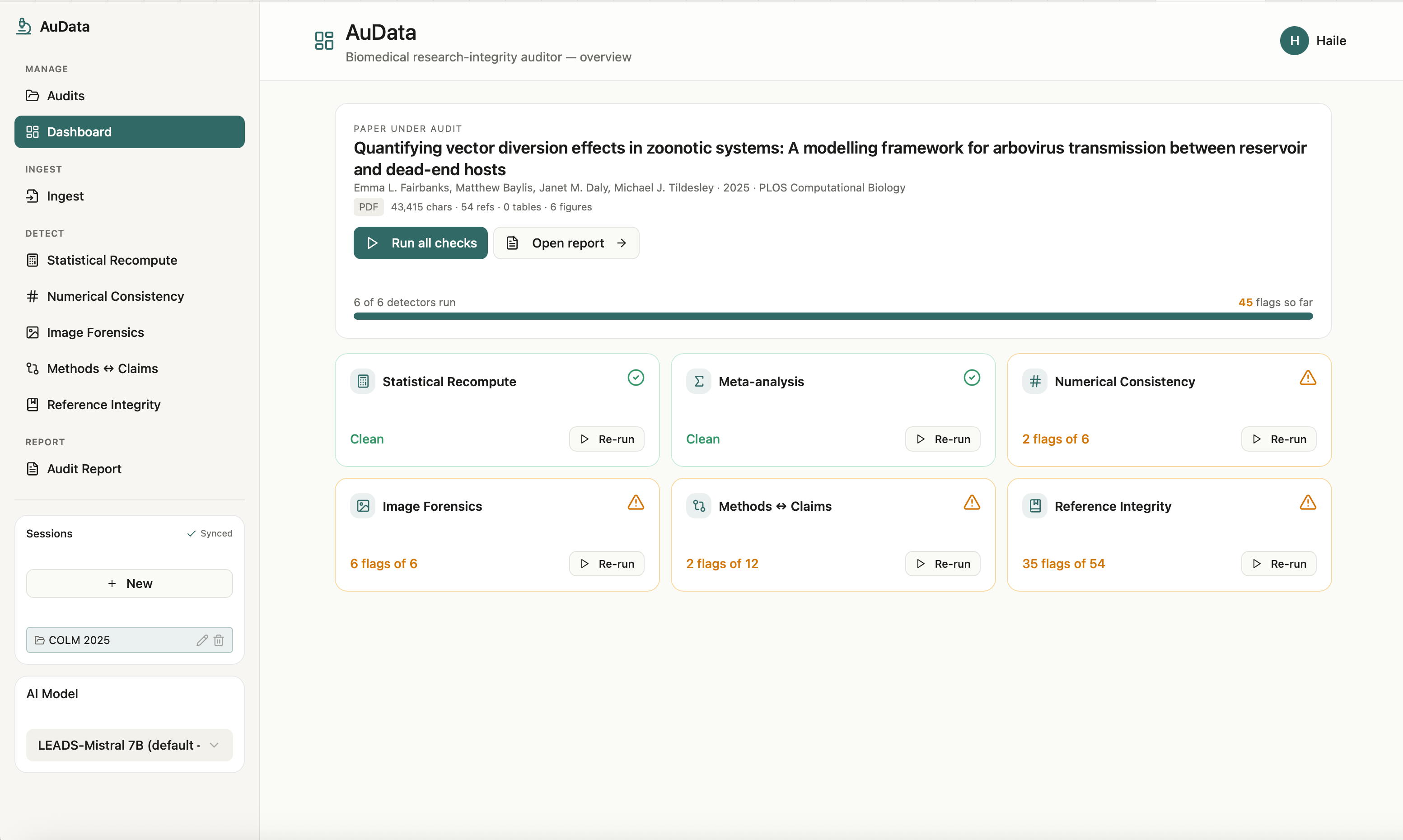
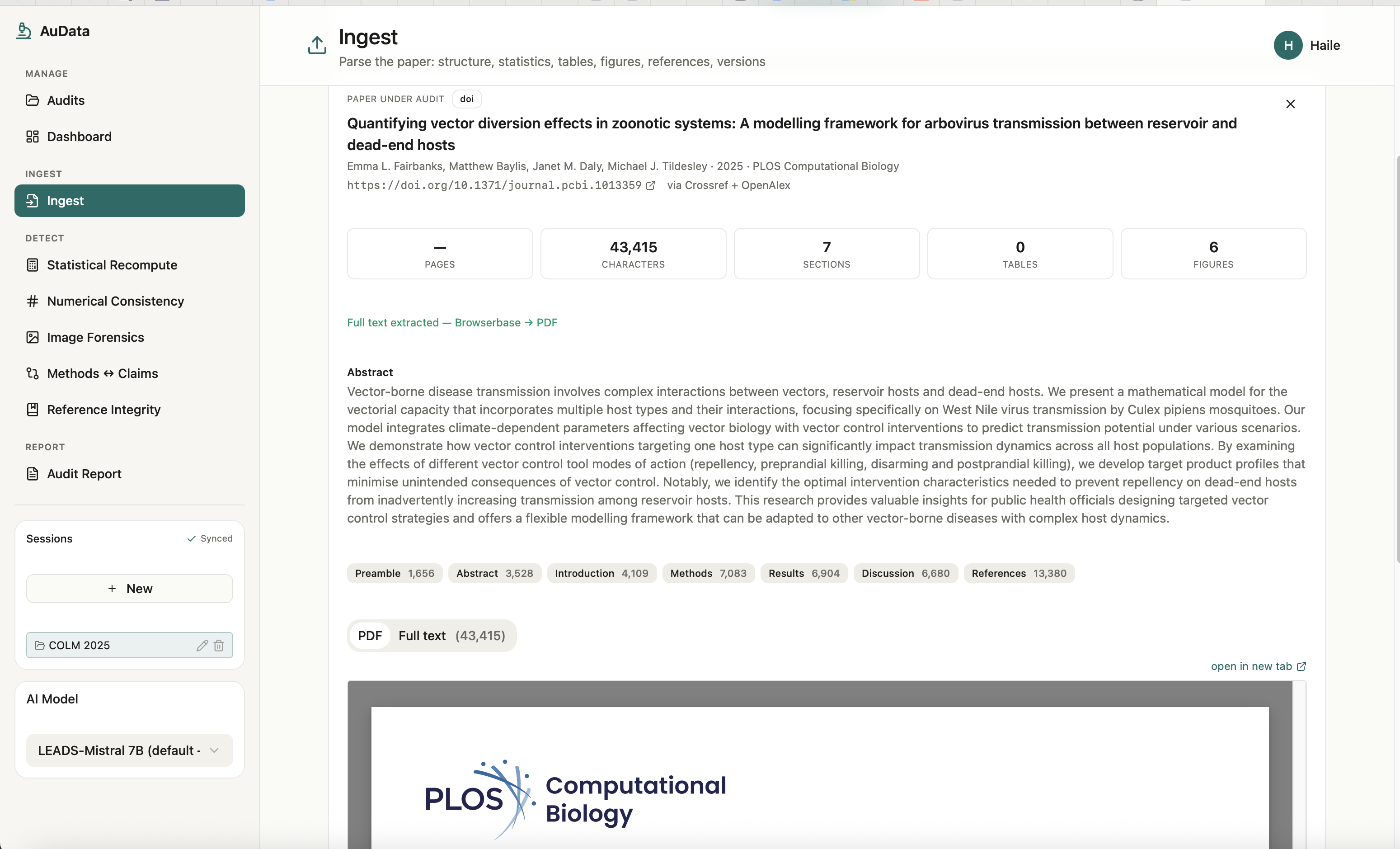
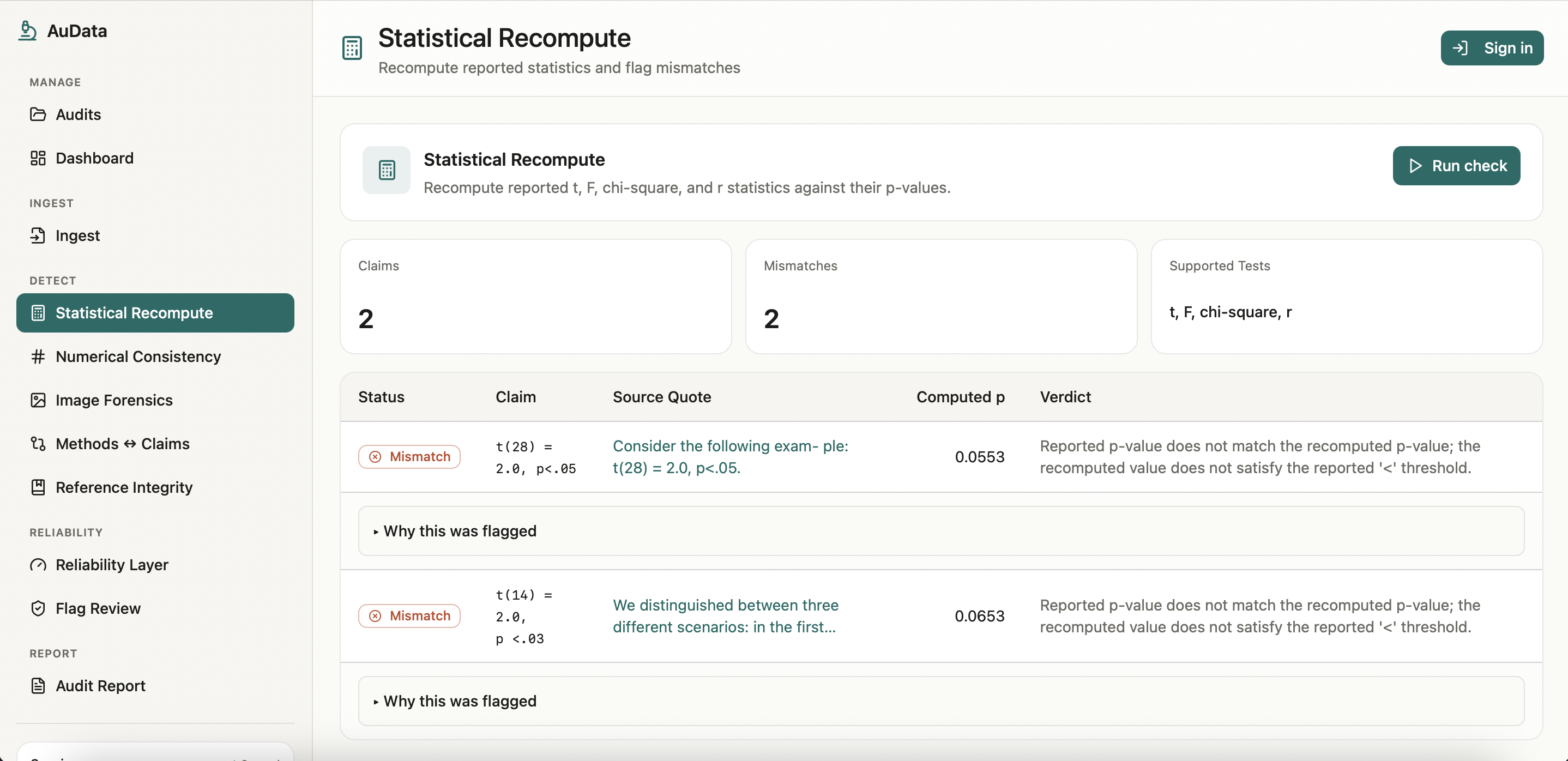
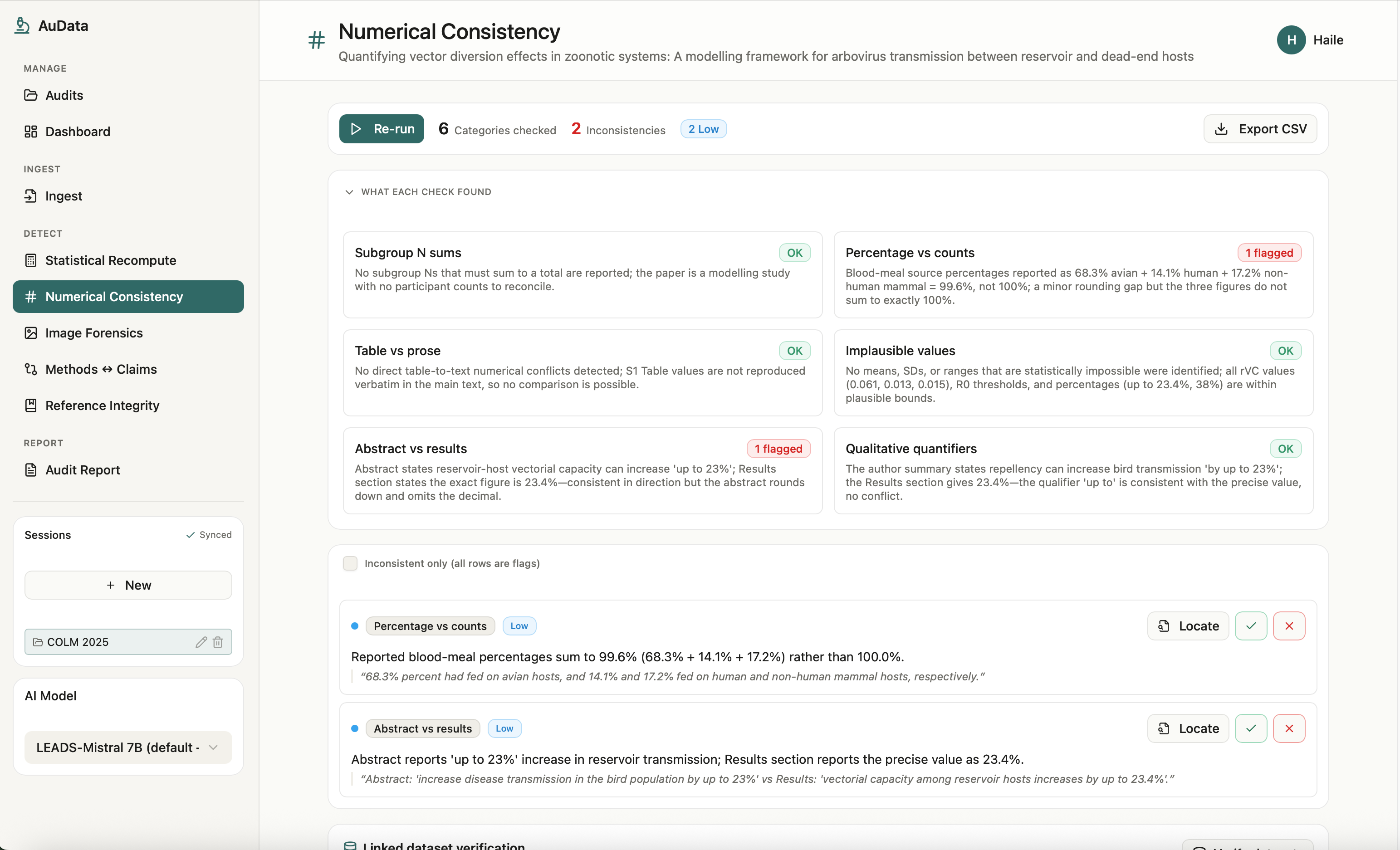
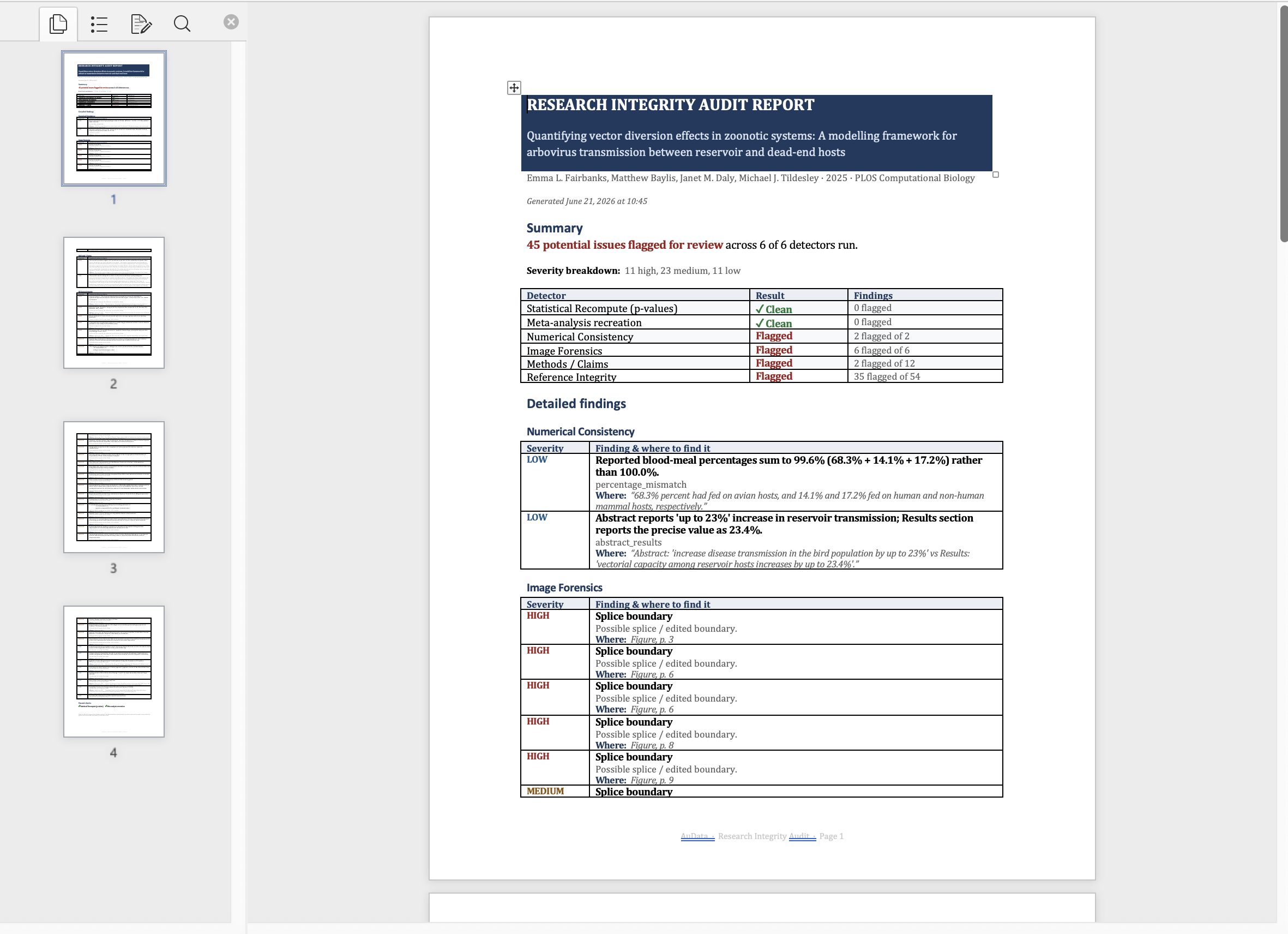
AuData is a multimodal research-integrity auditor for biomedical papers and preprints. Point it at a study and a team of detection agents go to work: they recompute reported statistics from their test values, recreate meta-analyses, cross-check internal numbers (sums, percentages, table-vs-text), screen figures for cloning, splicing, and cross-paper reuse, test whether the conclusions are actually supported by the methods, and verify every citation for retractions and errors. Each finding comes back prioritized by severity and linked to exact evidence, with a one-click jump to the highlighted spot in the PDF, so a reviewer can see precisely what was flagged and why. Everything consolidates into a downloadable audit report. The point is to turn research integrity from a manual spot-check into a structured, repeatable audit.
How we built it
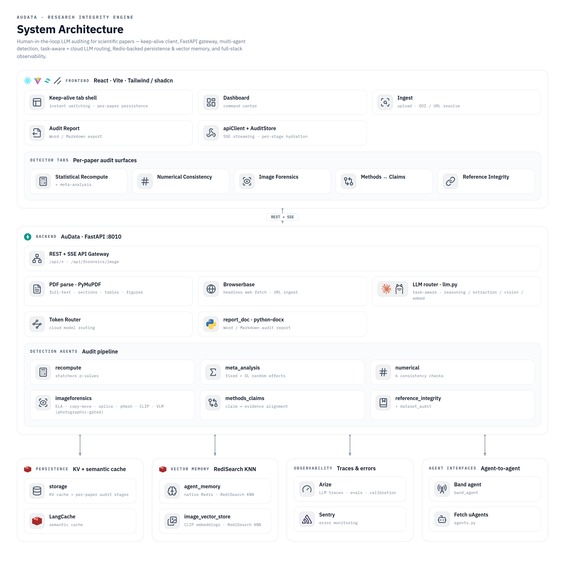
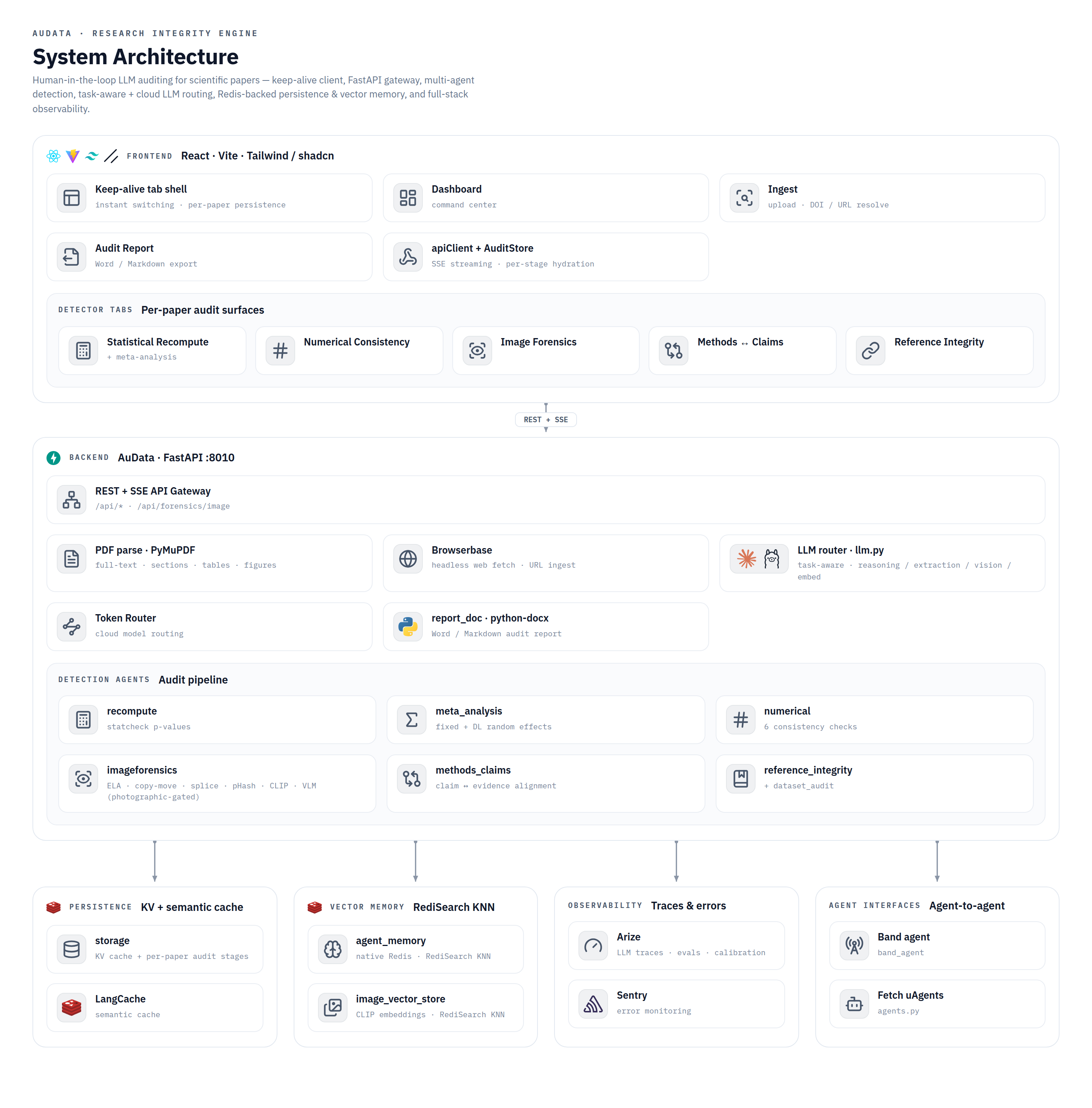
AuData is a modular multi-agent pipeline behind a standalone FastAPI service. It uses Claude for reasoning-heavy checks and routes lighter and vision work to local models, with Redis powering session-aware caching, semantic caching, vector search for cross-paper figure matching, and long-term agent memory. Paper ingest handles PDF parsing, full-text extraction, section/table/figure detection, and clean metadata resolution, with Browserbase as a fallback fetcher for hard-to-reach sources. On top of that sit the specialized detectors: a statistics engine for p-value recomputation and meta-analysis recreation, numerical-consistency checks, reference integrity, methods-versus-claims analysis, and image forensics (ELA, copy-move detection, splice detection, perceptual hashing, and CLIP-embedding cross-paper comparison). A persistence layer ties every flag back to exact paper evidence so nothing is a black box, and we exposed the auditor as a Band agent so it can collaborate with other agents in a shared room.
Challenges we ran into
Research integrity is not one problem, it is many. Statistical recomputation, citation verification, figure comparison, and methods-claims review each fail in different ways and demand different evidence and different confidence thresholds, so there is no single model or metric that covers them. The harder challenge was trust: every flag had to be inspectable, grounded in the source paper, and framed as reviewer assistance rather than an automated accusation. We spent a lot of time and effort making findings point to a precise line, figure, or reference instead of an opaque score.
Accomplishments that we're proud of
We brought five distinct integrity checks into one coherent, multimodal workflow instead of five disconnected scripts, end to end from ingest to a downloadable report. The image forensics surfaces the actual figure with the suspicious region highlighted, the statistical checks show the full recomputation, and every flag carries a locator back into the PDF. Most of all, the whole system is built around transparency and human judgment, which is the only responsible way to ship a research-integrity tool.
What we learned
Building AuData showed us that research integrity is really a systems problem. It requires combining document parsing, retrieval, statistical validation, image analysis, and semantic reasoning in a way that is precise, practical, and understandable. We also learned that the most important part is not just detecting a possible issue, but presenting it with enough evidence and context for a reviewer to make a defensible judgment.
What's next for AuData
We want to deepen each agent and close the loop. That means stronger statistical and numerical recomputation, richer cross-paper analysis using related-work and same-author figure comparison, and reviewer-decision calibration, where the system learns from past accept/dismiss decisions (via agent memory) to reduce noise over time. We also want to harden the reporting layer so any flag can be exported with clear severity, confidence, and evidence links for researchers, reviewers, and journals.
Built With
- anthropic
- band-sdk
- browserbase
- clip
- crossref-api
- docx
- europe-pmc
- exceljs
- fastapi
- fetch-ai
- gemini
- google-gemini
- imagehash
- langchain
- lucide-react
- material-ui
- microsoft-band
- motion
- numpy
- ollama
- openai
- openaid
- openalex
- opencv
- pandas
- pdf.js
- pillow
- pubmed
- pymupdf
- pypdf
- python
- python-docx
- radix-ui
- react
- react-router
- recharts
- redis
- redis-langcache
- redis-vector-search
- sentence-transformers
- sentry
- shadcn/ui
- sqlite
- supabase
- tailwind-css
- typescript
- vite





Log in or sign up for Devpost to join the conversation.