-
-
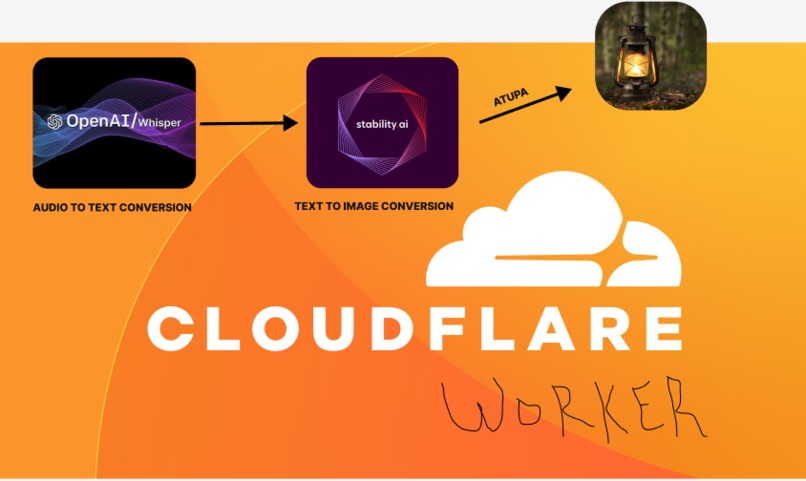
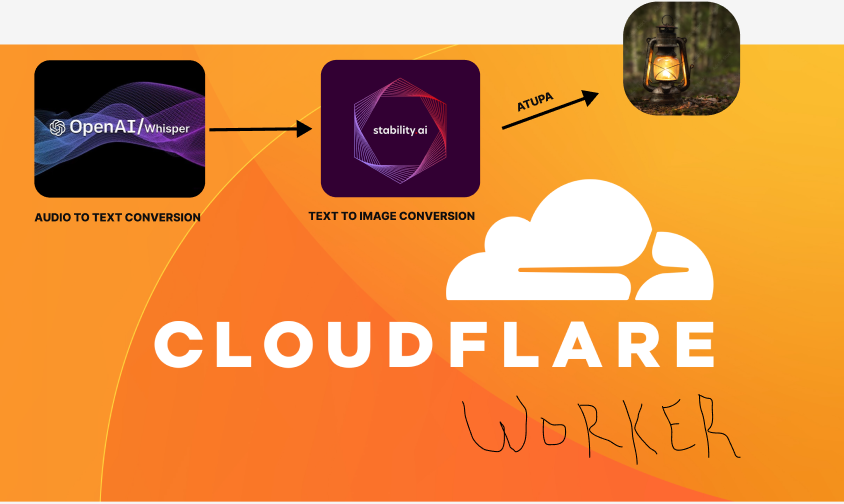
Atupa (`Her-too-parr`) is another word for Lantern.
-

Analytics page to give insights on how effective the LLMs are. It help to generate contextually relevant and emotionally appropriate images.
-
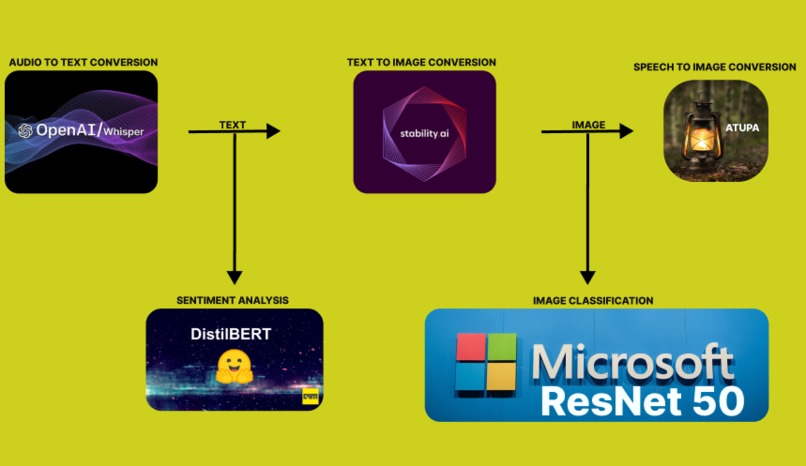
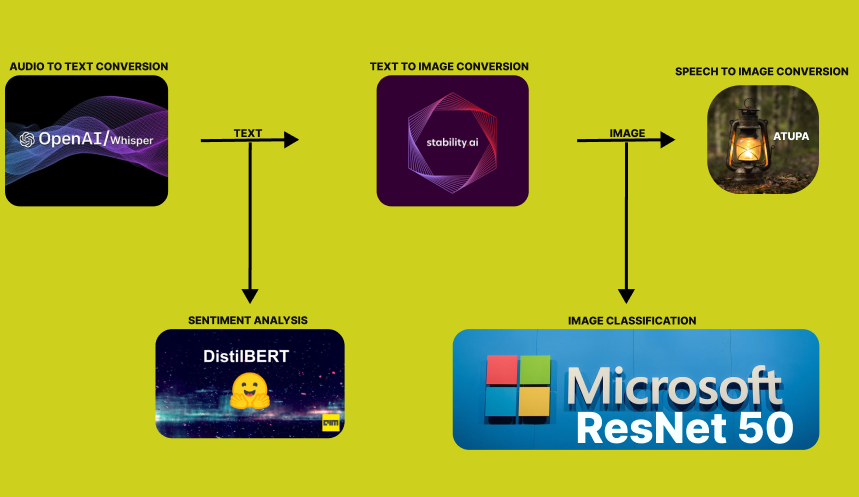
2 LLMs in series and 2 LLMs in parallel. LLMs working together for the greater good.
-

The prompt in addition with sentiment analysis and image classification are used as the key to the image stored in the R2 bucket.


Inspiration
The inspiration behind "Atupa" is rooted in the desire to make a meaningful impact on the lives of children and individuals who are deaf and partially blind. Recognizing the challenges faced by this specific user group, the project aims to leverage technology to enhance accessibility and promote inclusivity.
What it does
"Atupa" offers a unique solution by enabling audio-to-image conversion. Users can upload audio files, which are then processed using Cloudflare AI for both audio-to-text conversion and image generation. This multi-sensory approach allows children and individuals with sensory impairments to access and experience digital content more comprehensively.
Atupa analytics page
Leveraging sentiment analysis and classification results can enhance the audio to image converter's ability to generate contextually relevant and emotionally appropriate images, improving both accuracy and user experience. The result of the analytics is stored in Cloudflare's R2 bucket.
Integration with ChatGPT-3.5 for Advanced Analytics
To further enhance the capabilities of "Atupa," we propose the integration of ChatGPT-3.5 for advanced analytics using the text and image classification data obtained from the Atupa analytics page.
Text Classification with ChatGPT-3.5
ChatGPT-3.5, a state-of-the-art language model, can analyze the textual data collected from Atupa's audio-to-text conversion. This integration will provide insights into the sentiment, themes, and context of the uploaded audio content. Additionally, ChatGPT-3.5 can assist in refining the classification of audio prompts, improving the overall accuracy and relevance of the generated images.
Image Classification with ChatGPT-3.5
Utilizing ChatGPT-3.5 for image classification enhances the understanding of the visual content generated by "Atupa." The model can identify objects, scenes, and context within the images, contributing to a more detailed and comprehensive analytics report. This information can be invaluable in refining the image generation process, ensuring that the output aligns more closely with user expectations.
Notable LLMs used include Openai whisper, Microsoft Resnet 50, Meta m2m100, Stability AI Stable Diffusion and Hugginface Disstilbert.
How we built it
The project is built on the Hono framework, utilizing Cloudflare AI for the essential tasks of audio-to-text conversion and image generation. The frontend is designed with a clean and user-friendly interface to ensure accessibility. The collaborative development process involved careful consideration of the unique needs of the target user group, promoting inclusivity in the design and implementation.
By integrating ChatGPT-3.5 into Atupa's analytics workflow, we aim to unlock new possibilities for refining our audio-to-image conversion process and providing an even more tailored and engaging experience for our users.
Challenges we ran into
During the development of "Atupa," we encountered several challenges that demanded innovative solutions, and a deep understanding of engineering and accessibility principles.
Audio-to-Text Conversion Optimization
Optimizing the audio-to-text conversion process presented a significant challenge. We worked tirelessly to enhance the accuracy and efficiency of this crucial step, ensuring that the transcribed text faithfully represented the content of the uploaded audio files.
Handling Diverse Audio Inputs
Dealing with a wide variety of audio inputs posed another challenge. We focused on creating a system that could effectively handle diverse accents, languages, and audio qualities, ensuring a seamless experience for users with different linguistic backgrounds.
Meaningful Image Generation
Achieving images that are not only technically accurate but also meaningful and relevant to the provided audio prompts presented a complex challenge. Implementing strategies to enhance contextual understanding, we aimed to align the visual output more closely with the intended user experience.
Despite being a solo endeavor, overcoming these challenges required a dedicated effort and a commitment to delivering a solution that genuinely meets the needs of our target user group. Drawing upon my expertise and relentless pursuit of excellence, I navigated the intricacies of image generation to ensure a meaningful and impactful result for our users.
Accomplishments that we're proud of
We take pride in the successful development of "Atupa," a solution with the potential to significantly improve the lives of children and individuals who are deaf and partially blind.
Integrated Audio-to-Text Conversion and Image Generation
The seamless integration of audio-to-text conversion and image generation showcases our commitment to pushing the boundaries of technology. This accomplishment reflects our dedication to making a positive impact on accessibility and inclusivity.
What we learned
The development journey of "Atupa" provided valuable insights into the complexities of addressing accessibility challenges. We deepened our understanding of:
- Technical aspects of audio processing
- Artificial intelligence for multimodal tasks
- User interface design for inclusivity
Additionally, we gained an appreciation for the importance of considering the unique needs of individuals with sensory impairments throughout the development process.
What's next for Atupa
The journey for "Atupa" doesn't end here. Moving forward, our plans include:
Refining Audio-to-Text Models
Continuing to iterate on the project by refining the audio-to-text models to enhance accuracy and broaden language support.
Improving Image Generation Algorithms
Working on improving image generation algorithms to ensure visually compelling and contextually relevant output.
Incorporating Additional Features
Adding new features to enhance accessibility and cater to the evolving needs of our user community.
Collaborating with the Community
Engaging in collaborative efforts with the community, gathering user feedback, and fostering continuous improvement are pivotal to the project's ongoing success.
Our commitment is to evolve "Atupa" into a valuable and impactful tool for individuals with auditory and visual challenges, contributing to the creation of a more inclusive and just society.

Log in or sign up for Devpost to join the conversation.