Attest
Inspiration
I'm a Principal Product Manager, and I've spent more nights than I'd like on incident bridges — watching a service degrade, then writing the document that goes to the customer afterward: what broke, how long, what we're doing so it doesn't happen again. The hardest part isn't what happened — it's how do we make this right and rebuild the trust we just lost? The SLA credit is the instrument for that. But a credit only rebuilds trust if you can prove it's correct.
Building integrations is my actual job, so I think a lot about the teams on the other side of an outage — the ones who have to turn an incident into a number a customer will accept. The same pains kept surfacing:
- You can't get the number without a scavenger hunt. Downtime in one system, maintenance windows in another, contract terms that differ per account, severity calls somewhere else. Assembling one credit by hand takes days.
- You can't safely ask "what if." Reclassify an incident, honor a dispute, change one assumption — and there's no way to see the dollar effect without re-running everything. So no one does, until they're forced to.
- You can't prove it's right. When a customer — or your own CFO — asks "is this correct?", the honest answer is "I think so." That's where trust quietly erodes, on the one topic you can least afford it: money owed.
- You can't fix a wrong input safely. A contract uploaded weeks late, a severity revised after the fact — and the credit you already settled was computed on stale inputs. You either can't correct it, or you quietly overwrite it and lose the trail. None of these are calculation problems. They're proof problems. So on nights and weekends, I built the system of record I wished those teams had.
What it does
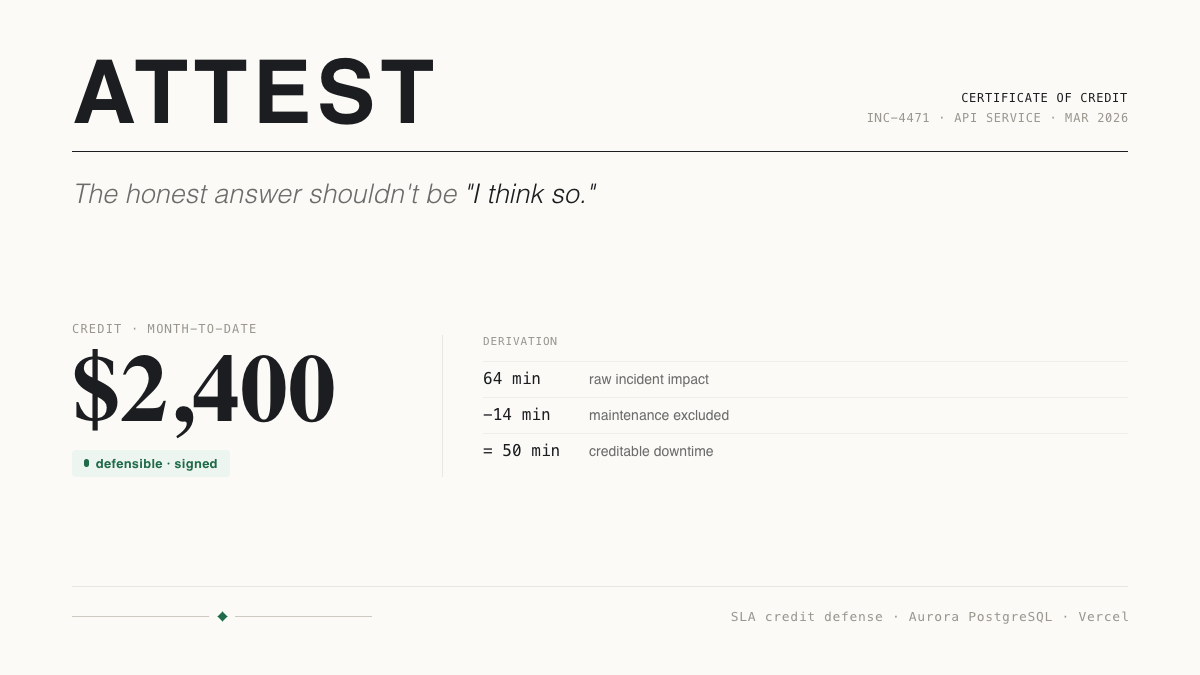
Attest is the system of record for the SLA credits a B2B company owes its customers — where contract terms, incident data, and human judgment combine into a number you can defend, line by line.
One thing worth saying up front: almost every SLA tool on the market is built for the buyer — helping customers claim the credits they're owed. Attest is built for the vendor: the company that has to compute, defend, and stand behind the credits it owes, across many customers on non-uniform contracts. I haven't found a vendor-side equivalent.
It answers each of those four pains directly:
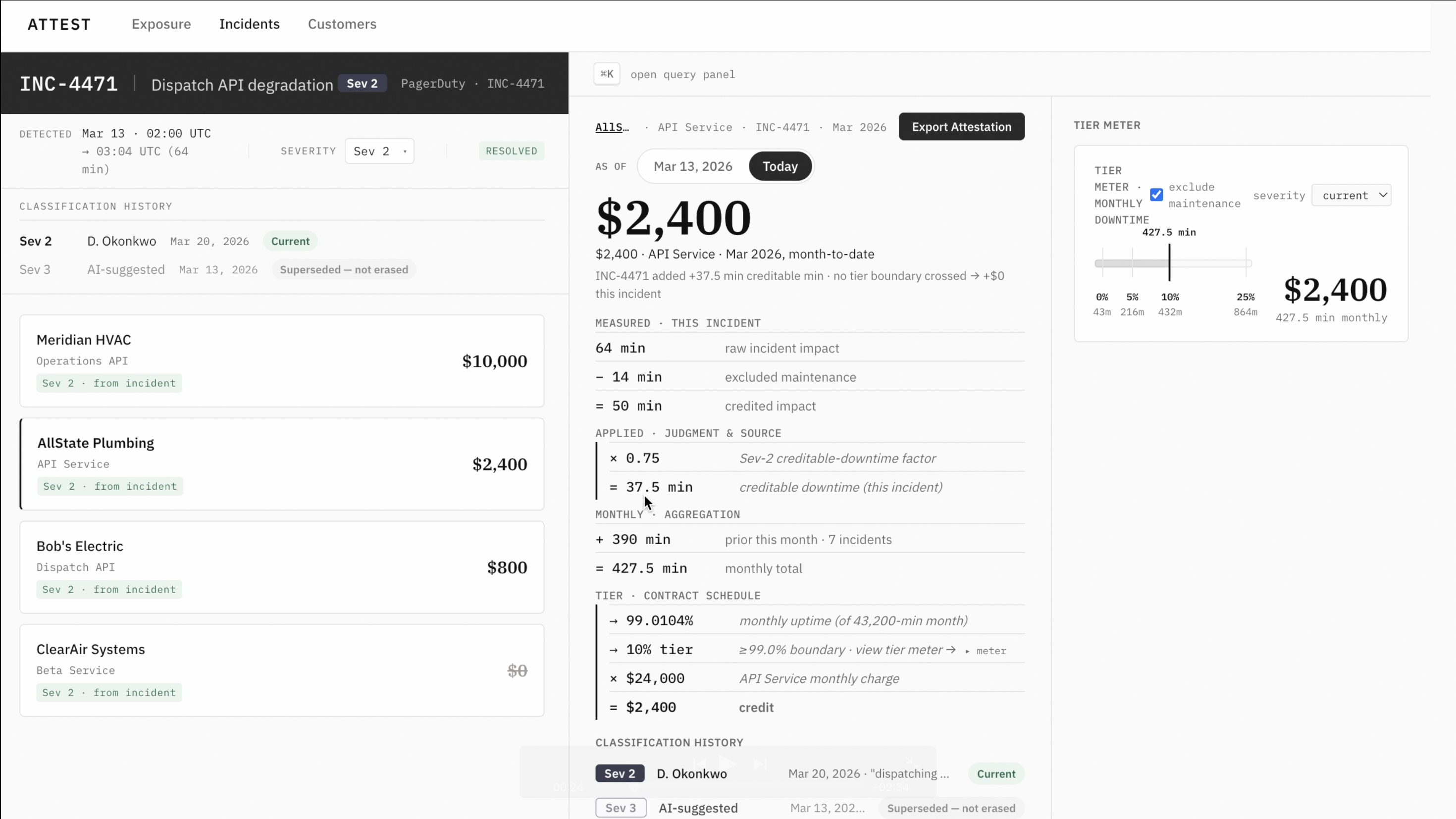
The scavenger hunt becomes one derivation. Every credit decomposes into a clickable chain: raw downtime, the maintenance excluded by this contract, the severity weighting, the tier, the dollar amount. The inputs that used to live in five systems resolve into one record. What took days to assemble by hand is computed and traceable in a click.
"What if" becomes a live question. Reclassify an incident or change one assumption and watch the credit move in real time — without writing anything. When a customer pushes back on a severity call, you don't argue from memory; you show them the exact difference: "classified at this severity, you're owed this; at that one, this." You still have to negotiate — but you negotiate from evidence instead of "I think so."
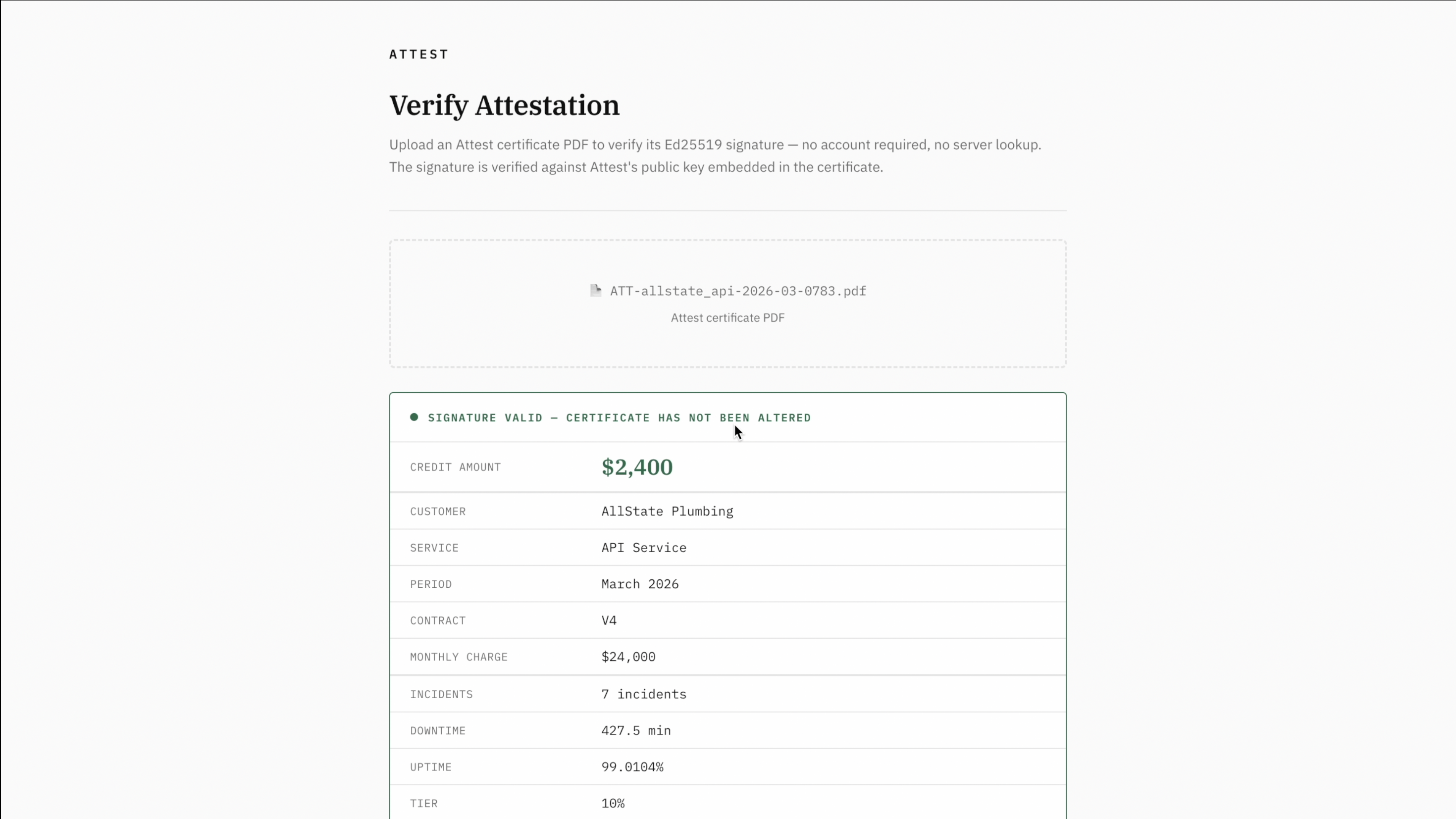
"I think so" becomes "yes." The number isn't asserted; it's derived in front of you, and it exports as a signed certificate that carries its own proof. When the CFO or the customer asks "is this right?", the answer comes with the receipt. A portfolio view also shows total exposure split into what's defensible today and what's not yet — the credits still waiting on a human decision — and tells you exactly which ones, so liability stops being a surprise.
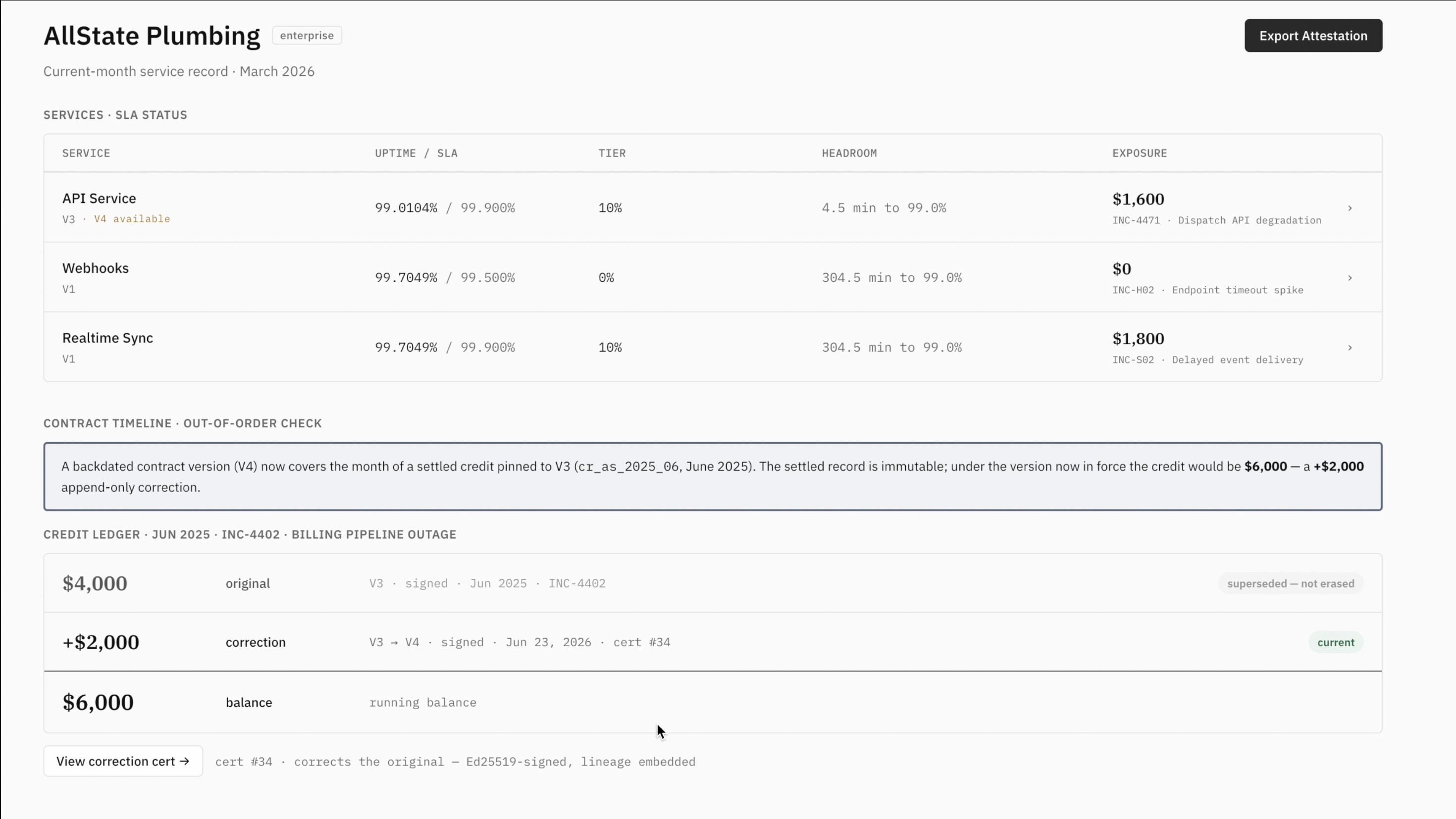
Fixing a wrong input stops being dangerous. Contracts get renegotiated and uploaded late; classifications get revised. Attest never silently overwrites a settled credit. It issues a signed correction, preserves the original — superseded, not erased — and the audit trail shows who decided what, and when. The first thing any business sells is trust; this is how you keep it when something went wrong.
What Attest is not: it's not an SLA calculator, not a monitoring dashboard, and not a contract manager. A spreadsheet can compute a number. Attest's job is to produce a number that survives a customer dispute, a CFO phone call, and a finance audit.
How we built it
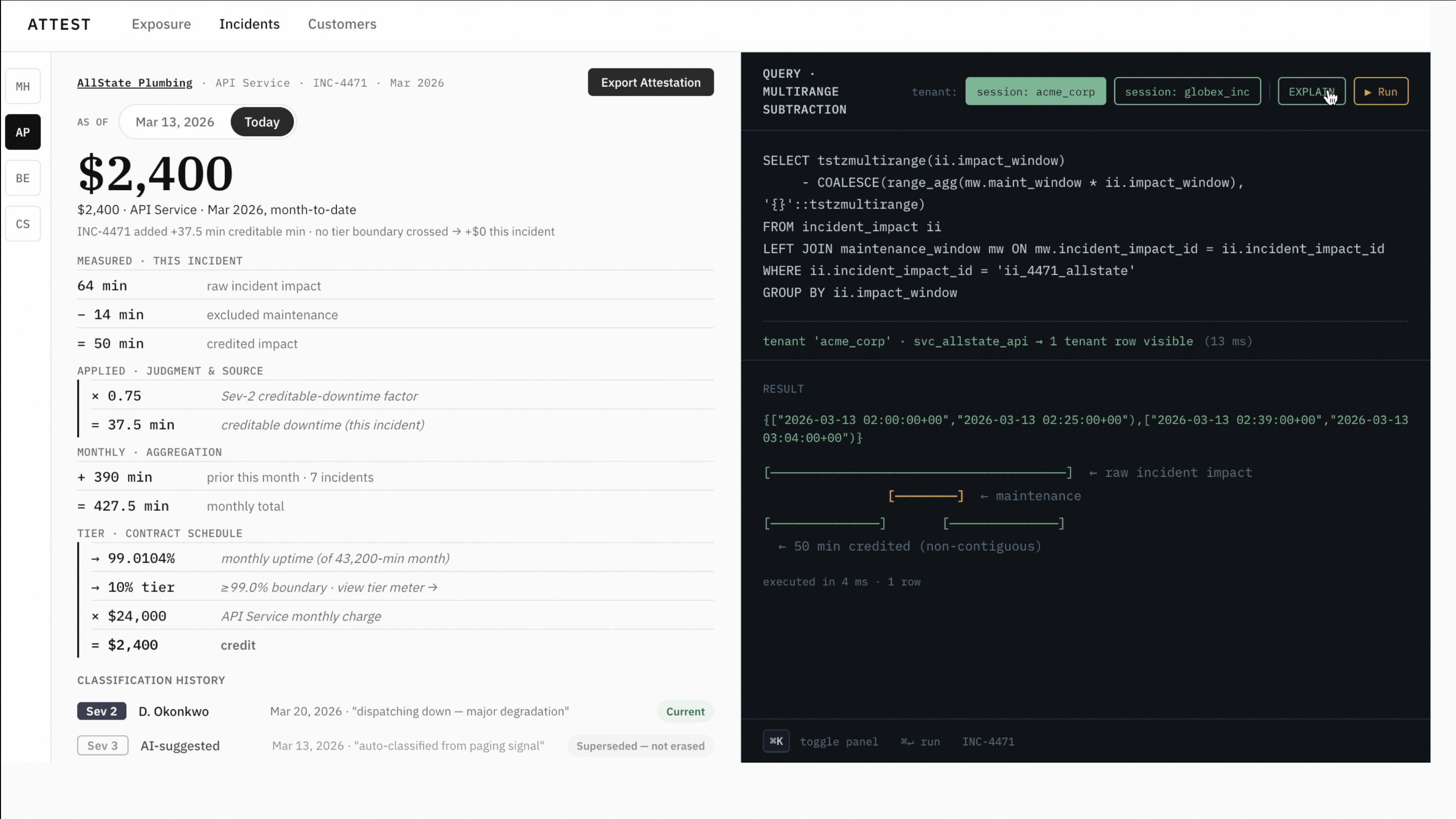
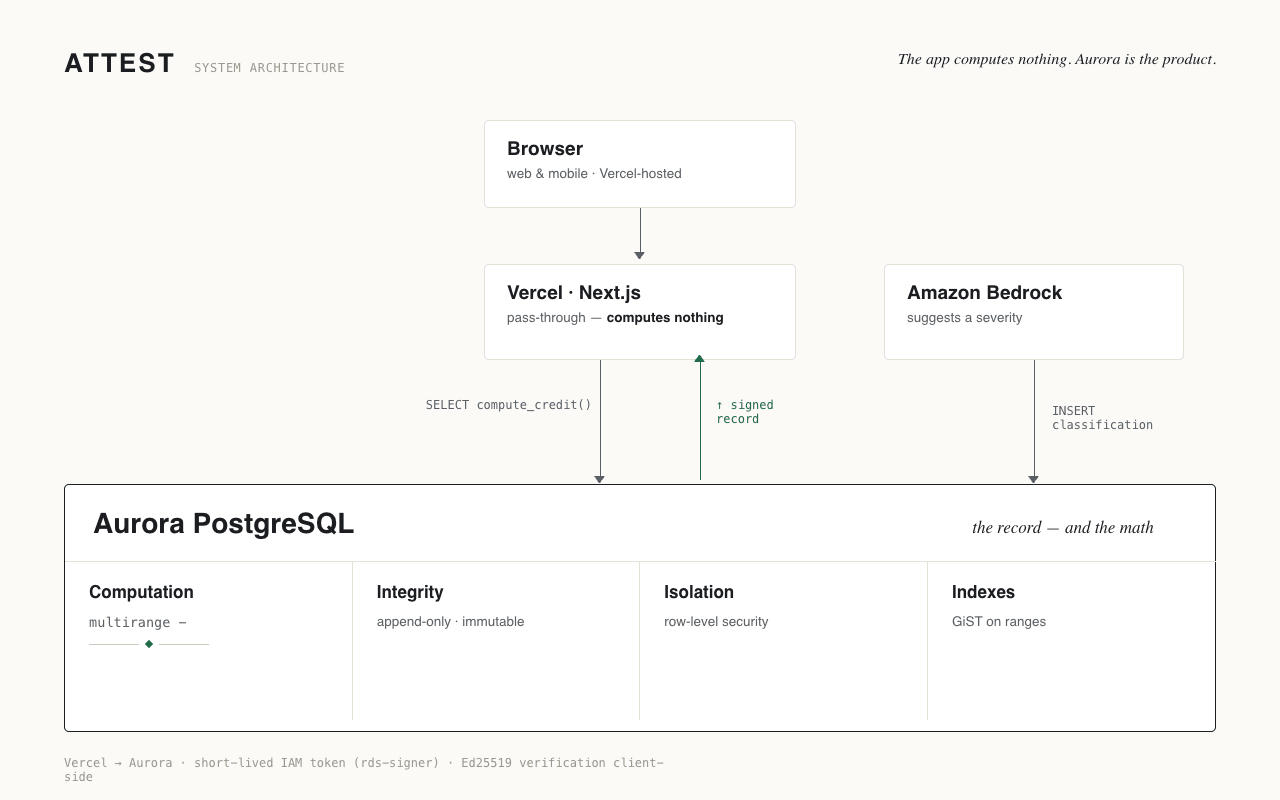
The core decision: the database computes the credit, not the application. The Next.js layer on Vercel passes parameters and renders rows; it does no credit math — no tier lookups, no severity weighting, no downtime subtraction. A credit lookup is literally SELECT * FROM compute_credit($1, $2::date), and the route returns that row as-is. The point isn't that SQL is magically bug-free — it's that the derivation lives in one inspectable place instead of scattered across application handlers. One source of truth, not logic you'd have to reassemble to audit.
Why Aurora PostgreSQL specifically, out of the three allowed databases? Because the core operation is temporal set subtraction — an outage minus the maintenance intervals a contract excludes — and that's native to Postgres range types. In a key-value store like DynamoDB, that interval math would have to be reconstructed in application code, which is exactly what this product exists to avoid. The problem is relational and temporal; the database choice follows from the problem.
The heart of the system is one expression:
tstzmultirange(ii.impact_window)
- COALESCE(range_agg(mw.maint_window * ii.impact_window), '{}'::tstzmultirange)
Read it left to right: take the incident's impact window as a multirange, then subtract the union of every maintenance window clipped to that incident (* is range intersection, range_agg folds the windows together, - is multirange difference). What comes back is the exact, possibly non-contiguous set of minutes that count — computed in SQL, with native range operators, not reconstructed in TypeScript. That credited-minutes value then drives the uptime percentage, the tier, and the dollar amount, so a few minutes of error can move the credit across a tier boundary by thousands.
The rest of the database does the work the application would otherwise do unreliably:
- GiST indexes on the range columns mean overlap queries (which impacts fall in a month, which maintenance windows touch an incident) resolve through an index scan rather than scanning the table — the access pattern that holds as incident history grows. The seed spans multiple tenants, severity tiers, maintenance windows, and correction scenarios to exercise the real paths.
EXCLUDE USING gistconstraints also enforce non-overlap of contract versions and maintenance windows at write time. - Row-level security enforces tenant isolation in the database, not the app. One
tenant_isolationpolicy across the tenant-facing tables, plus a read-only role (attest_tenant, SELECT and EXECUTE only, no write grants): set the session's tenant, run a query, and a query for the wrong tenant returns zero rows — not an error, not a leak. - Append-only integrity, enforced by triggers. Settled credits are immutable — a trigger blocks any update or delete. Corrections are new rows linked to the original by certificate lineage; classification history is insert-only. You supersede by appending, never by editing — so the history is provable, not just present.
- Ed25519-signed certificates. Each credit exports as a signed PDF that verifies against the embedded public key — no database lookup required. The artifact carries its own proof. Signing happens in the app layer with Node's
crypto; the signing key is held in AWS Secrets Manager and fetched at invocation time (cached in-process for the warm instance's lifetime), so the raw private key is never present as a plaintext environment variable in the deployed function. The raw key does pass through app memory at sign time — inherent to this approach; KMS's signing API would avoid it but doesn't support Ed25519. The record the certificate attests to is entirely the database's. - Amazon Bedrock suggests a severity from the incident signal; a human reviews and can override; both land in the append-only classification history with provenance. Bedrock never writes to the database — it returns a suggestion, the app inserts it, and the human override is a separate insert. AI suggests, a person decides, the record captures both. Contract terms, tiers, and exclusions are modeled as structured configuration, so a new customer's SLA is defined declaratively rather than in code. Automated import — turning contract documents and live incident feeds into that structure directly — is a planned next step.
The frontend is hosted on Vercel; the connection to Aurora uses short-lived IAM tokens via rds-signer. The "zero stack" wasn't a constraint I worked around — the thin-app, heavy-database shape is the architecture that makes the core claim true.
Challenges we ran into
The math is genuinely hard — that's the whole point, and it's what made it hard to build. From the outside, SLA credit calculation looks like "count the downtime, look up the contract, do the math." From the inside it's: figure out what counts as downtime for this contract, subtract only the maintenance that qualifies, handle one incident being a different severity for different customers, carry it across a month of prior incidents, find which tier boundary the total lands on, and only then compute dollars. Getting the temporal range subtraction to produce the exact credited minutes — and having every figure downstream reconcile to it — took real iteration. A single off-by-a-few-minutes error in the multirange difference can cross a tier boundary and change the credit by thousands.
Making it demonstrable was its own problem. Because the credit is a chain where each step feeds the next, the seed data has to be internally consistent end to end — every minute, exclusion, severity factor, prior-month total, and contract charge has to line up so the final number is correct and every intermediate row a viewer clicks is also correct. A system of record that doesn't reconcile on inspection isn't a system of record, so I spent real time making the data hit precisely.
Keeping the AI honest. A classifier that silently sets severity would undermine the entire trust premise. Getting Bedrock to suggest rather than decide — with a constrained prompt, a deterministic fallback, and the human override as the real recorded decision — was the design that mattered.
Accomplishments we're proud of
- Built solo, on nights and weekends, by a product manager — not a professional engineer — and the database does real work: native multirange math, GiST-indexed overlap queries, row-level tenant isolation, and an append-only signed ledger.
- A credit you can prove, not just compute — the full derivation is clickable, and the signed certificate verifies itself.
- An append-only correction model that does the commercially correct thing — you still owe what you owe — instead of the easy thing (refuse, or silently overwrite).
All 10 canonical credit queries run against the live Aurora instance.
What we learned
The hard problem isn't the calculation; it's the inputs and the proof. I'd have scoped this product wrong a year ago — prioritized the math, under-invested in defensibility. Defensibility is the product.
Pushing logic into the database is a real strategy, not just a preference. "Here's the function that computed it" is a different trust posture than "the app computed it somewhere." I'll ask different questions in design reviews now.
The most trustworthy system isn't the one that's never wrong — it's the one that can make a wrong thing right, on the record. An append-only ledger that issues honest corrections beats one that pretends settled numbers never change.
What's next
Automated ingestion — turning real contract documents and live incident/monitoring feeds into Attest's structured terms, so the record builds itself instead of being configured. This is the biggest gap between the demo and a deployable product, and I know it.
Key rotation — the signing key now lives in AWS Secrets Manager; a managed rotation schedule is the next step to close the custody story.
Proactive thresholds — alert when an account is one incident away from owing credits, instead of finding out after.
A documented classification rubric surfaced in-product — turning the human judgment that today lives in one person's head into a written, auditable standard.
Built With
- amazon-bedrock
- aurora-postgresql
- ed25519
- gist-index
- react
- row-level-security
- tstzmultirange
- tstzrange
- vercel

Log in or sign up for Devpost to join the conversation.