-
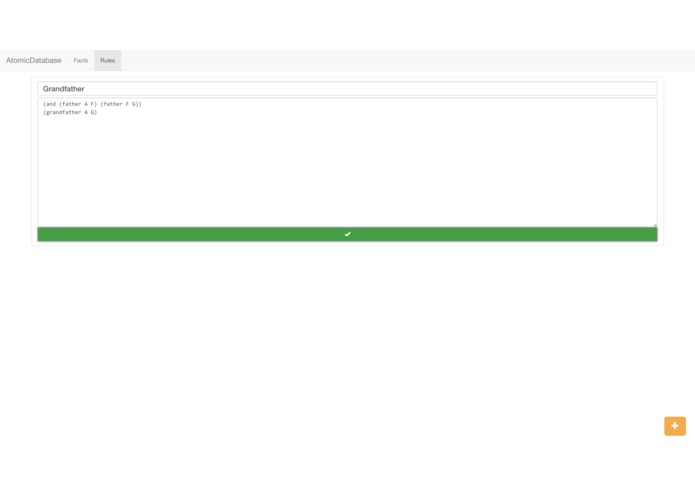
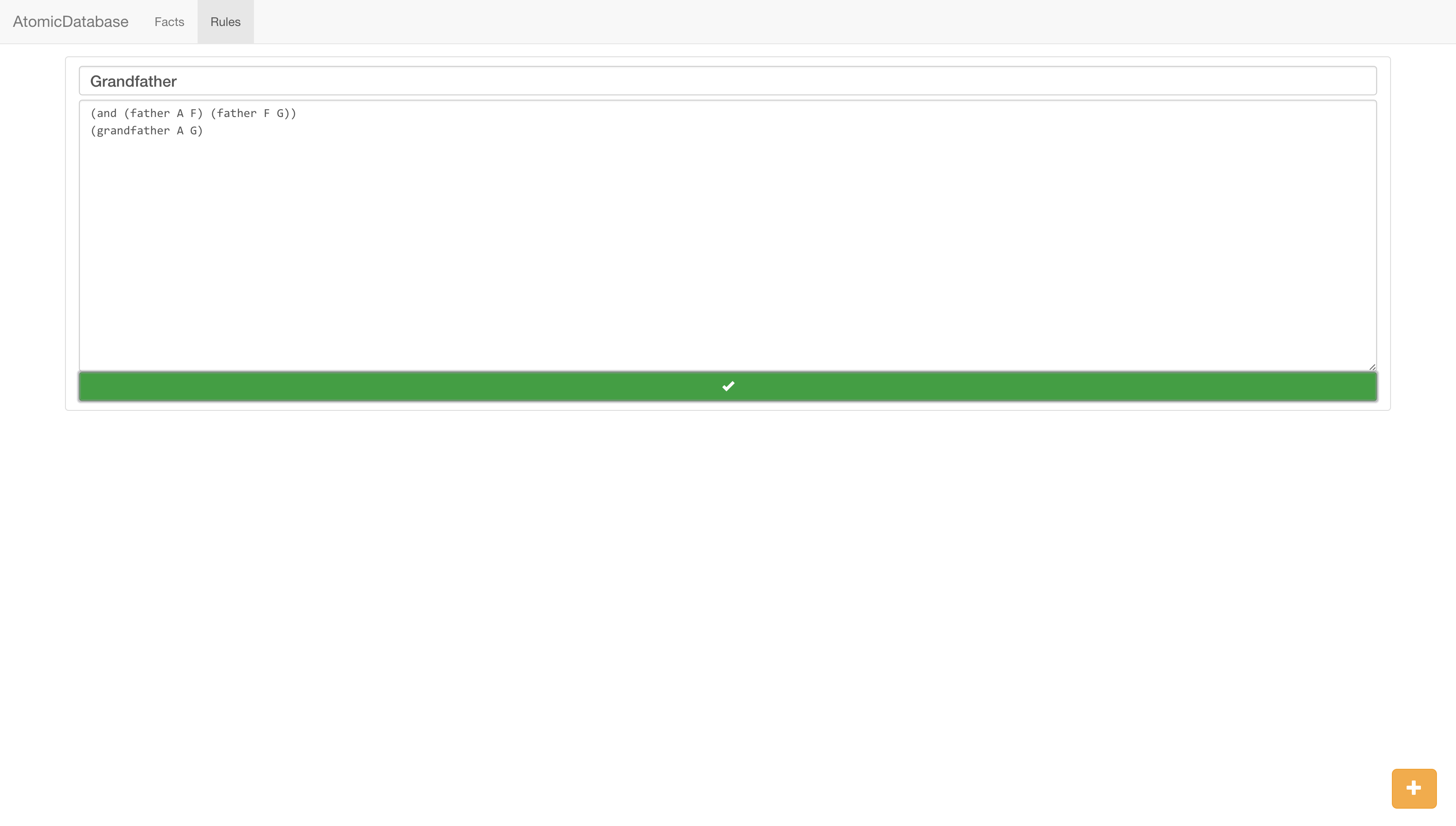
Defining rules in the s-expression language (just for programmers)
-
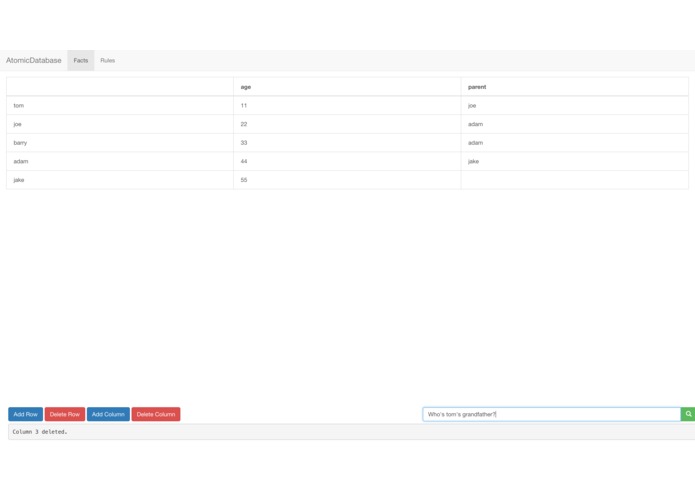
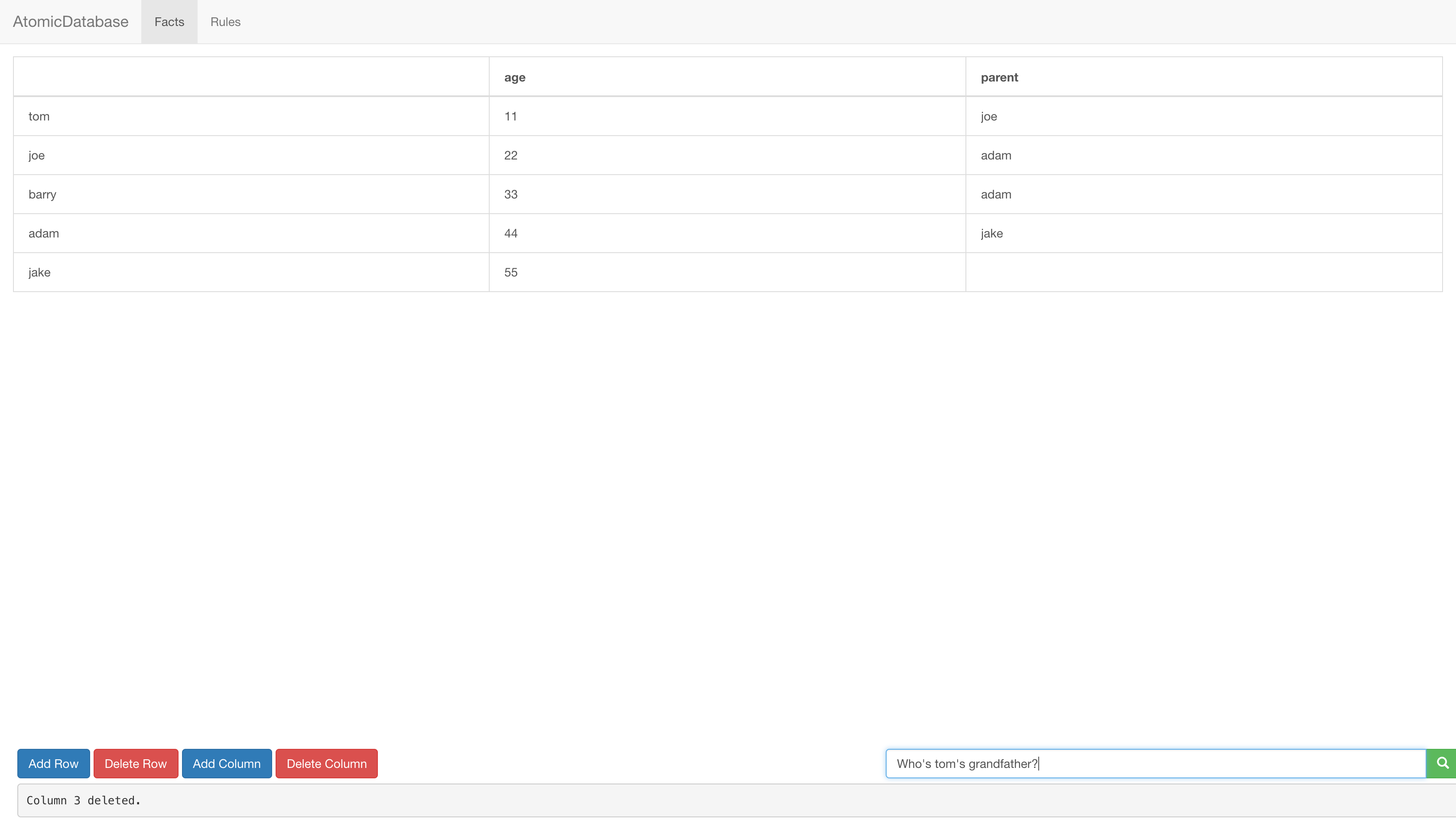
Editing "facts" (data)
Inspiration
Excel is dumb. Not in the "bad" way, but the "not smart" way. So are SQL databases. You might as well just write down your information on a piece of paper. What if your database could actually help you?
What it does
AtomicDatabase lets you enter data in a simple, easy to use, Excel-like interface. Once you've entered your data, you can ask the database questions about it's knowledge in natural language. (Currently the questions can't be very complex). But AtomicDatabase's real power is in its "rules." You can describe rules such as If F is the father of X, and G is the father of F, X's grandfather is G. (We currently use s-expressions, and regular language is almost working). With these rules, it can answer your questions without you having to specify exact information. In fact, rules are just a logical description of what you want, and it will do all the work for you.
How we built it
Front end (by Raymond W.)
For the frontend, we handled entering data by sending every update - every time the text field loses focus, a row or column is deleted, to be more specific - to the backend (more on that later), while at the same time doing the aforementioned actions so the changes would synchronize with each update. To perform those tasks, we abused jQuery - .children(), .first(), .val() - to get the data we need to send and then package it into json format. On every reload, the frontend would call the backend to get the data so that it could display it in a (somewhat) user-friendly interface. Different requests are handled differently: for example, a delete request would be sent with type "delete," with some parameters, while a reload request does not pass anything at all.
Back end (by Christopher D.)
The backend is a simple express.js static file server, with a post request listener on the root url. When a post is sent there, it reads the type property on the incoming data and dispatches on that: if it's a 'delete-col', delete a column, if its a 'table' update the table, if a 'rule' add a new rule or update an old one, and so on. For table updates, the row is treated as the "entity", the column is treated as the "attribute" and the cell is treated as the "value", entering this triple in the format AEV (attribute, entity, value) into the database. Entities are nothing special, just tags. When a query comes in, a bare-bones NLP library is used to strip it of extra words and expand contractions. Once this is done, the backend matches the query to one of five common query structures, such as "#PossessiveNoun #Noun" for queries such as "What's tom's age?" These matches are then converted into the AEV format with the unknown as a "placeholder." For instance, the above query would become: ['age', 'tom', placeholder('x')]. The backend then sends the results of a datalog-type unification of this AEV with the database as a JSON result to the frontend. Natural language rules, which have not been tested and are currently under a feature flag are handled similarly, and s-expression rules ((age tom X)) are handled much more simply.
Challenges we ran into
Front end
- Handling row and column deletion requests
- Sending updates in workable format, and updating them properly
- Sending requests for server data and using the data to properly initialize the table (and not display [object Object])
- 404 Error
Back end
- Matching queries fault-tolerantly, and flexibly was a real issue
- remembering the order of the entities and attributes so that the data could be sent back properly to the front end if it got reloaded.
- Protecting the datalog-type library from requests that would make it go forever (it's very naively implemented.)
- Interpreting rules safely and properly
Accomplishments that we're proud of
Front end
- Setting up working deletion methods that send delete requests properly
- Making use of server data (like updating the table on (re)load gracefully
Back end
- Creating a reliable, flexible natural language solution
- Creating a simple and easy way to represent facts (as AEVs)
- Creating a great way to express rules.
What we learned
- Natural language is hard to do right
- Data formats are important
- File locations are important in requesting data
What's next for AtomicDatabase
- Improve natural language support across the board
- Allow more complex queries
- Allow numbers and math
- Display results as a table
- Syntax highlight rules
Built With
- compromise
- express.js
- html5
- jquery
- known
- node.js
- npm


Log in or sign up for Devpost to join the conversation.