-
-
Homepage
-
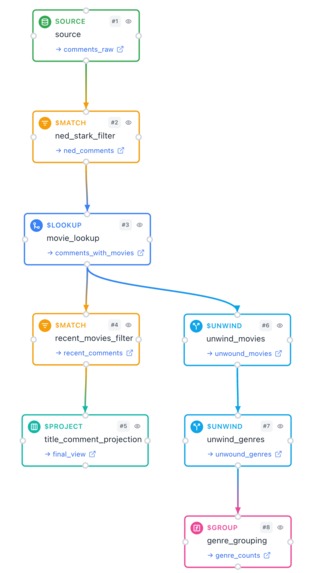
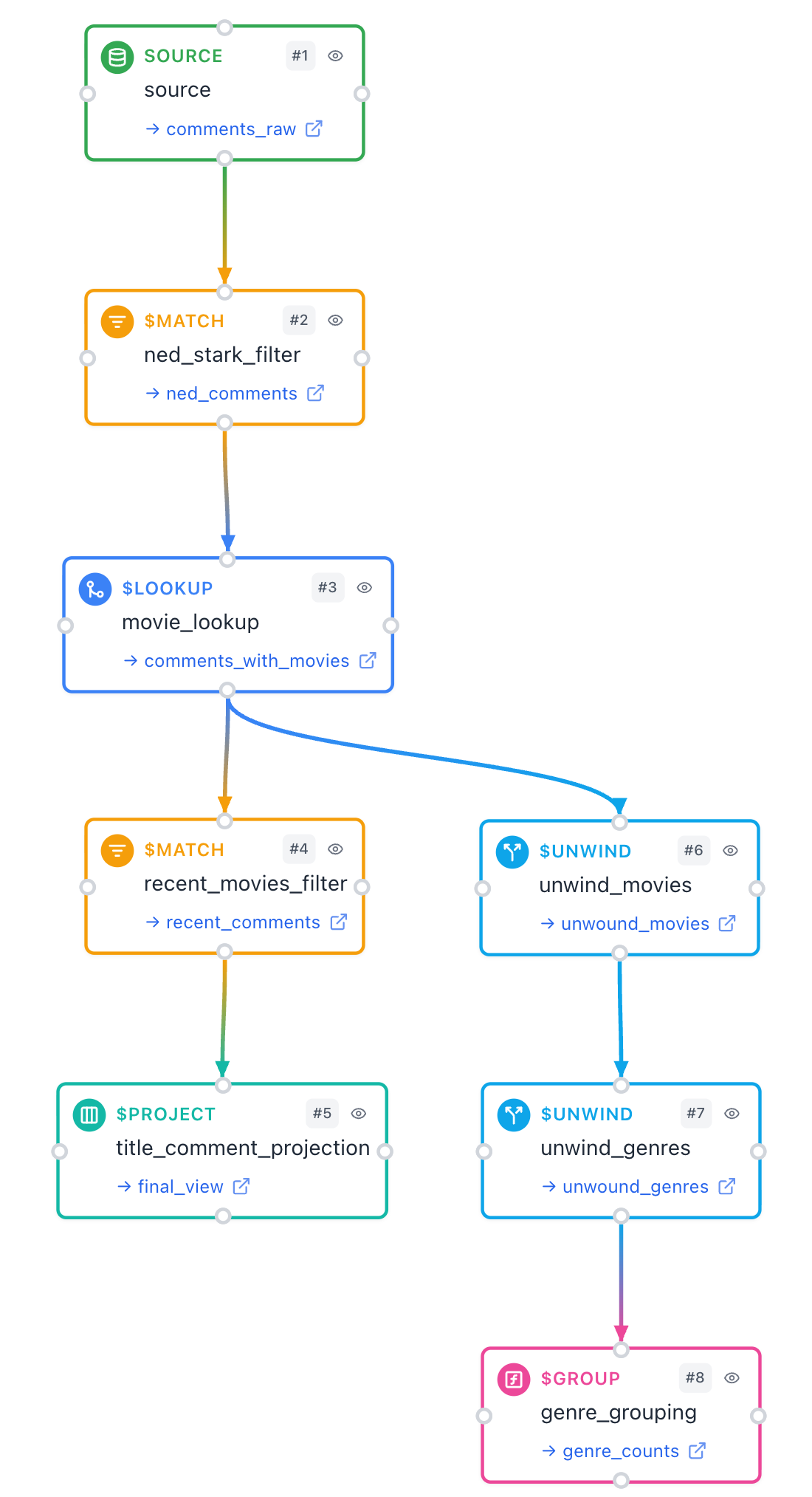
Pipeline diagram
-
Apps page
-

Docs page
-
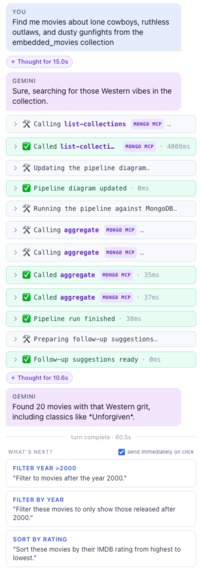
Visual trace timeline
-

Visual trace, result card
-
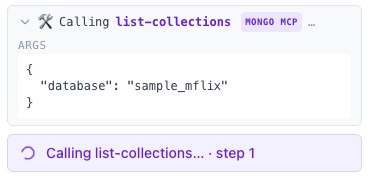
Visual trace, progress card
-
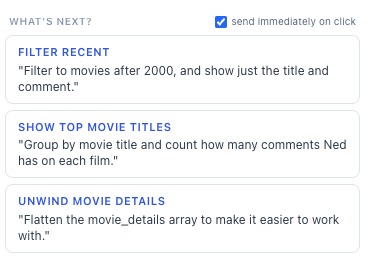
Visual trace, suggestions


Inspiration
MongoDB aggregation pipelines have a real learning curve, especially for developers coming from SQL. $lookup, $facet, $group, projection paths, document-shape mutations across stages — it's a language with its own grammar, and the way you debug it is by mentally simulating each stage. LLMs are good at translating intent into queries, but most "talk to your database" demos hand you the final result and ask you to trust the magic in between.
We wanted to keep the LLM's translation power AND make every step visible: type a request in English, watch an agent design the pipeline stage-by-stage on a live canvas, and see the documents flowing through each stage in real time. The Google Cloud Rapid Agent Hackathon's MongoDB partner track was the right shape — first-party MCP server, agent loop primitive, official sample dataset.
What it does
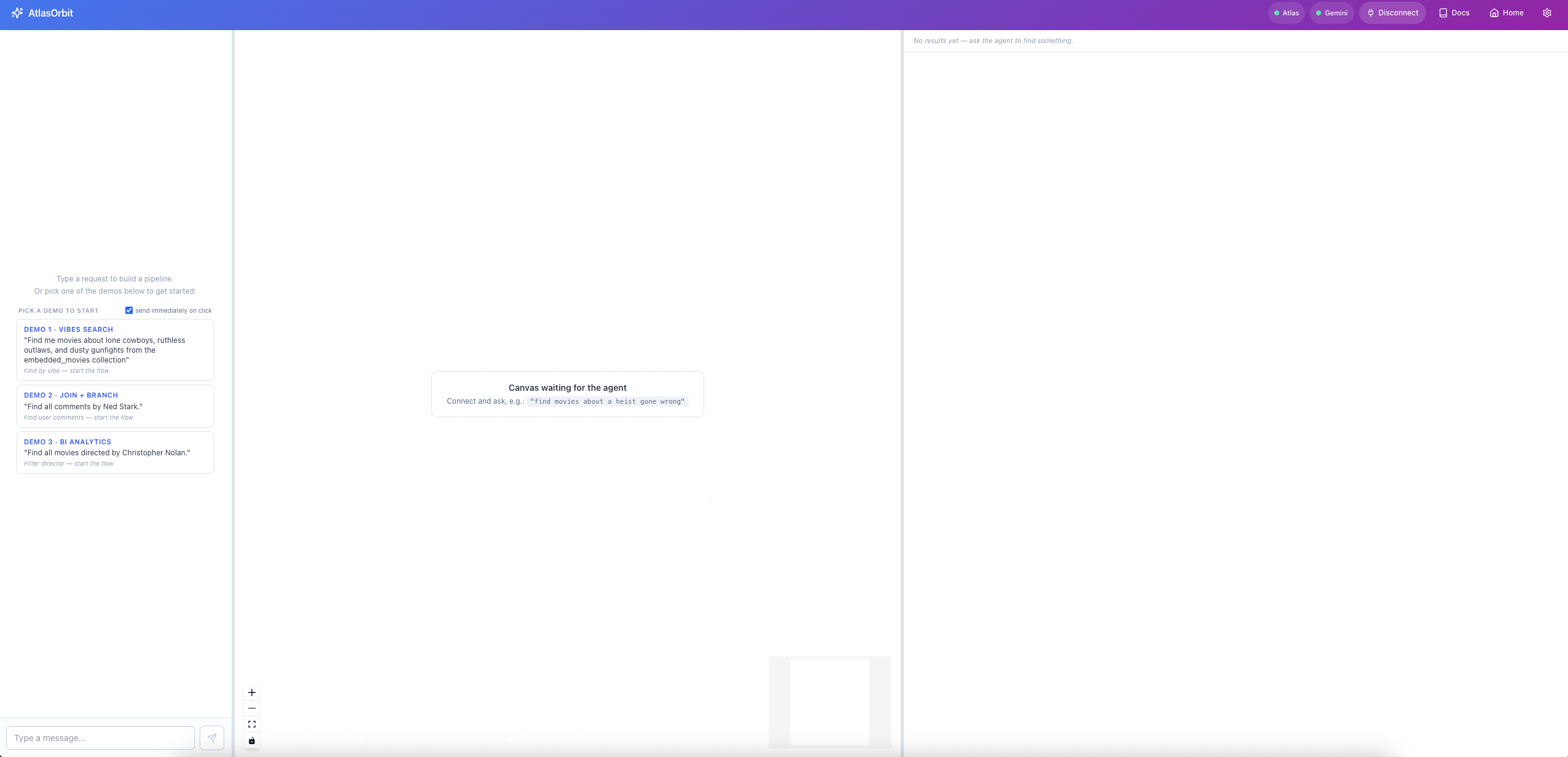
AtlasOrbit is a visual NoSQL agent: type "find me movies about lone cowboys and dusty gunfights" or "Christopher Nolan films grouped by year with average IMDB rating," and a Google ADK agent — backed by Gemini 3 Flash and the MongoDB MCP server — builds a real MongoDB aggregation pipeline on a React Flow canvas, runs it, and streams per-stage previews into a results panel below.
Key behaviors:
- Live trace timeline. Every tool call the agent makes becomes a progress pill that morphs into an expandable result card. No debug overlay — the trace IS the chat panel.
- Per-stage previews from one MongoDB call. Our custom
run_pipelinetool wraps the agent's pipeline in$facetso each canvas stage gets its own preview row in a single round-trip. The pipeline still sees the full collection. - Cumulative agent-driven canvas. Every
update_canvascall ships the entire pipeline schema; the UI derives layout (including parallel branches off$lookup) entirely fromdepends_on, so the agent never picks coordinates. - Three demo flows ship in the empty state: vibes / semantic search (
$textrendered as a "vector search" node), branching joins ($lookup→ two parallel paths), BI analytics ($group+$sort+$project).
Try it: https://atlasorbit-1013253724354.us-central1.run.app · 3-min demo: https://youtu.be/lsHe72iTYF0 · Source: https://github.com/TLiu2014/gemini-nosql-data-wrangler
How we built it
- Agent layer: Google Agent Development Kit (
@google/adk)'sLlmAgentdriving the ReAct loop, with Gemini 3 Flash as the model. Four customFunctionTools (update_canvas,push_results,run_pipeline,suggest_next_prompts) drive the UI; the MongoDB MCP server is exposed to the agent via ADK'sMCPToolsetso it auto-discoversaggregate,find,list-collections, etc. - Database: official
mongodb-mcp-serveras a stdio subprocess, spawned per session in--readOnlymode against MongoDB Atlas'ssample_mflixdataset. The agent's tool allow-list is intentionally narrow —run_pipelineis the only path to executing a pipeline, which is what guarantees every stage tab gets populated. - Frontend: React 19 + Vite + Tailwind, with
@xyflow/react(React Flow v12) for the canvas, a chat panel that doubles as the trace timeline, and a result panel with one tab per stage. SPA workspace at/app, marketing landing at/, public tool reference at/docs. - Transport: a single long-lived WebSocket per session. Chat traces, canvas updates, and per-stage result rows all ride the same channel. ADK's
beforeToolCallback/afterToolCallbackare forwarded astraceevents so the UI gets a live JSON-RPC view of what the agent's doing. - Hosting: one Cloud Run service, one container, one URL. Express serves the built UI from
/app/public, the WebSocket from/ws, and/healthfor readiness probes. Secrets (MONGODB_URI,GEMINI_API_KEY) come from Google Secret Manager at runtime — never baked into the image.
Challenges we ran into
1. Empty result tabs after the first demo turn. Every Demo 1 / Demo 2 run came back with zero rows in every preview, and the agent retried run_pipeline four or five times before giving up with "I couldn't find any data." Root cause: mongodb-mcp-server v3+ now wraps every document payload in <untrusted-user-data-UUID>…</untrusted-user-data-UUID> tags as a prompt-injection mitigation. Our doc extractor skipped anything that didn't start with { or [ — so the wrapped JSON was thrown away. Fix: unwrap the tags before parsing, and consolidate the two duplicate extractors that existed in the codebase.
2. The MCP error -32000: Connection closed mystery on Cloud Run. The same code that worked perfectly on localhost died on Cloud Run during the first Connect click. The subprocess (npx -y mongodb-mcp-server@latest --readOnly) was exiting before completing the JSON-RPC initialize handshake. Cloud Run's runtime container runs as the non-root node user against a partly read-only filesystem, and npx's registry freshness check + cache write both failed silently. Fix in the Dockerfile only: pre-warm the npx _npx/ cache at build time as the node user, so the runtime spawn finds the package cached and skips the registry.
3. The agent leaked tool-call JSON into its final text reply. Occasionally the model dumped the suggest_next_prompts args inline ("OK. Here are the cowboy classics. { \"label\": \"...\", \"prompt\": \"...\" }, ..."). The chips were rendering correctly underneath; the JSON was pure noise. Fix: strengthened the system instruction's "Final reply" section with an explicit "never include tool args in text" rule, AND added a server-side regex strip as a safety net.
4. $vectorSearch wasn't actually usable. sample_mflix.embedded_movies ships with 1536-dim plot_embedding vectors from a third-party embedding model we couldn't reproduce at request time, and Gemini's embedding dimensions don't match. After burning two days trying to make it work, we routed all vibes queries to $match + $text against sample_mflix.movies (which has a real text index) and kept the purple "MQL_VECTOR_SEARCH" node on the canvas as a UI affordance. The system instruction documents the routing explicitly; dev-log.md carries the full postmortem.
5. Cold-start UX on Cloud Run. With --min-instances 0 (free tier), the first Connect click on a cold container took 8-10 s — Node boot + spawning the MCP subprocess + the 8 s Atlas probe timeout. Mitigated with --cpu-boost (free; halves the cold start) and a documented one-line toggle to flip --min-instances 1 during the judging window without rebuilding.
Accomplishments that we're proud of
- The
$facetpreview is the differentiator. One MongoDB call populates every per-stage result tab. The agent emits one pipeline; the server fans it out. Saves seconds per turn and lets the user diff stages instantly. - The visual trace timeline is a real demo affordance, not a debug overlay. Progress pills, expandable result cards with args + response, suggestion chips after each turn — the agent's reasoning IS the chat. People stop asking "is it actually doing something?" the moment they see it.
- Cumulative agent-driven canvas with auto-branching.
update_canvasis the only way the diagram changes, every call ships the full schema, the UI does all layout and edge derivation fromdepends_on. The agent never has to pick coordinates; branching just falls out. - Single-container Cloud Run deploy.
gcloud builds submit . && gcloud run deploy …is the whole redeploy. UI, WebSocket, and/healthall on one origin — no Vercel rewrites, no CORS, no cross-host plumbing. - Three demo flows in under three minutes. Vibes search, branching join, BI analytics — each completes prompt-to-result in ~30 s on a warm container.
What we learned
- ADK's
LlmAgent+MCPToolsetis dramatically cleaner than hand-rolling a ReAct loop on@google/genai. Our first server-side agent was a hand-rolled ReAct loop with manual tool-arg validation, manual MCP schema mapping, and a customMAX_TOOL_ITERATIONS = 8cap. Switching to ADK collapsed all of that plumbing into framework code;beforeToolCallback/afterToolCallbackgave us the trace events for free. The deprecated branch keeps the old loop as a fallback. - Make the agent's tool-call trace a first-class UI surface, not a debug panel. This is the single highest-leverage UX decision in an agentic app. Users move from "trust the AI" to "watch the AI" — which makes correctness, latency, and errors all easy to reason about.
- Per-stage previews change how people interact with pipelines. Instead of "build a whole pipeline, see one result at the end," users iterate stage-by-stage, spotting bad joins or empty matches mid-flow. The
$facettrick is dirt-cheap server-side and unlocks the whole interaction. - Cloud Run's runtime is more restrictive than it looks for subprocesses.
npx, npm cache writes,HOMEdefaulting,/tmpbeing a fresh tmpfs — corners where "works on my laptop" doesn't carry over. We documented the specific fixes indeployment.mdso the next team doesn't re-discover them. - Mongo MCP's untrusted-data wrapper is a real security feature worth understanding. Any code reading MCP responses needs to expect the wrapper; the v2 → v3 transition silently broke a lot of integrations. Our extractor now handles both shapes.
What's next for AtlasOrbit
- Real
$vectorSearch. Re-embedembedded_movies.plotwith a model whose dimensions we control (a Gemini embedding model or BGE), create a fresh Atlas Vector Search index, and route the vibes flow through$vectorSearchfor real. Right now the canvas shows a vector node and the pipeline runs$match + $text— a demo concession we want to retire. - Bring-your-own data. The agent already discovers schema via
collection-schema; pointing it at a user-provided MongoDB URI (instead of the hostedsample_mflix) is mostly a UX problem (Settings field, validation, error messaging) — the agent doesn't change. - Pipeline export ↔ import round-trip. "Export MQL" already ships (downloads a standalone
db.collection.aggregate([…])script). The inverse — paste an MQL script, render it on the canvas, hand it to the agent for editing — would close the loop with existing MongoDB workflows. - Diff mode between pipeline versions. Change
$match: { year: { $gte: 2000 } }to$gte: 1980and see exactly what shifts at each downstream stage. Visual diff over the result-tab columns. - Write operations behind a confirmation gate.
mongodb-mcp-serveralready supports$out/$merge; we run it--readOnlyfor safety. A future "approve this write" UX would unlock save-to-collection workflows without losing the read-only default. - Voice mode revival. We shipped voice in an earlier branch via Gemini Live API but hit close-code 1011 mid-stream errors that we couldn't reliably reproduce. Once the Live API is stable for tool-calling, plugging it back in is mostly UI work — the trace timeline and canvas don't change.

Log in or sign up for Devpost to join the conversation.