-
-
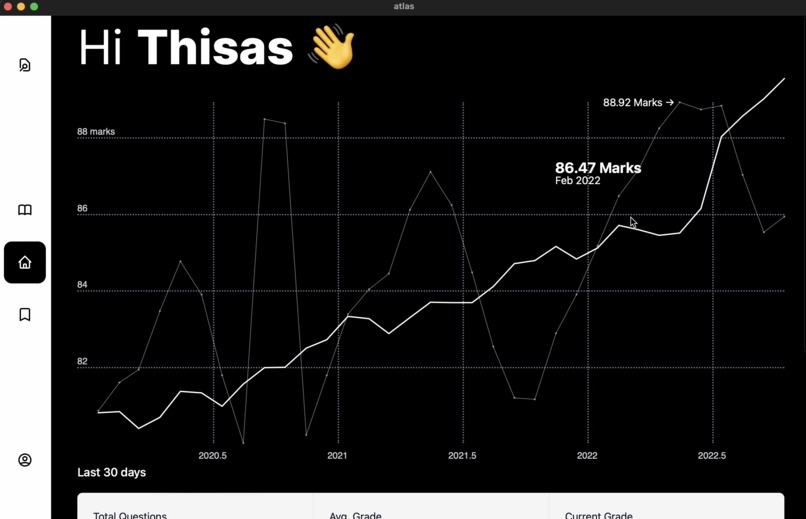
The End Goal
-
Running On iPadOS
-
Running On iOS
-
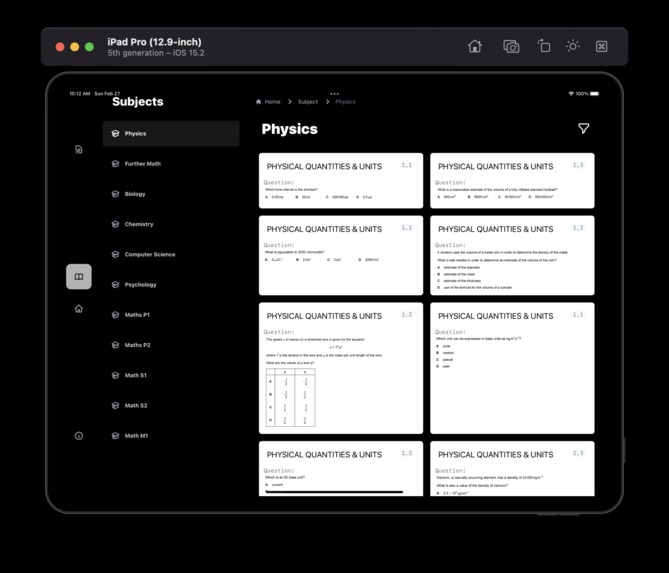
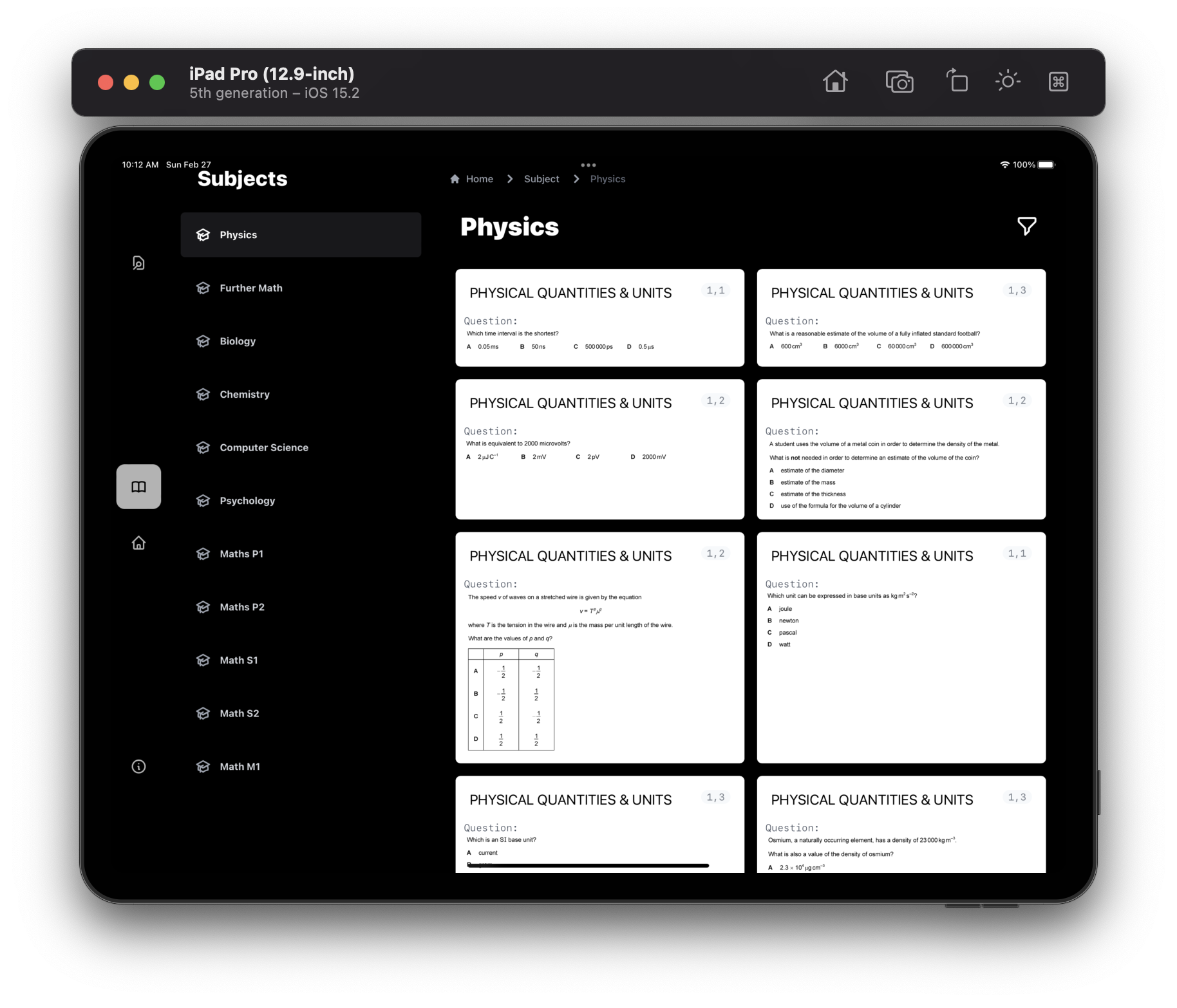
Questions Page iPadOS
-

Questions Page iOS
-
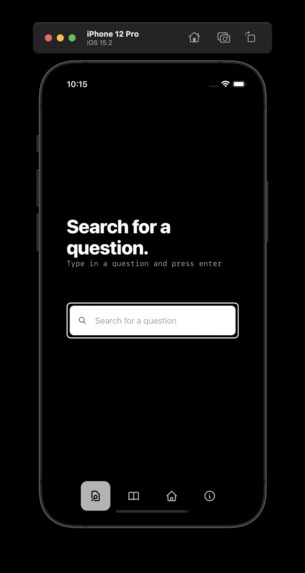
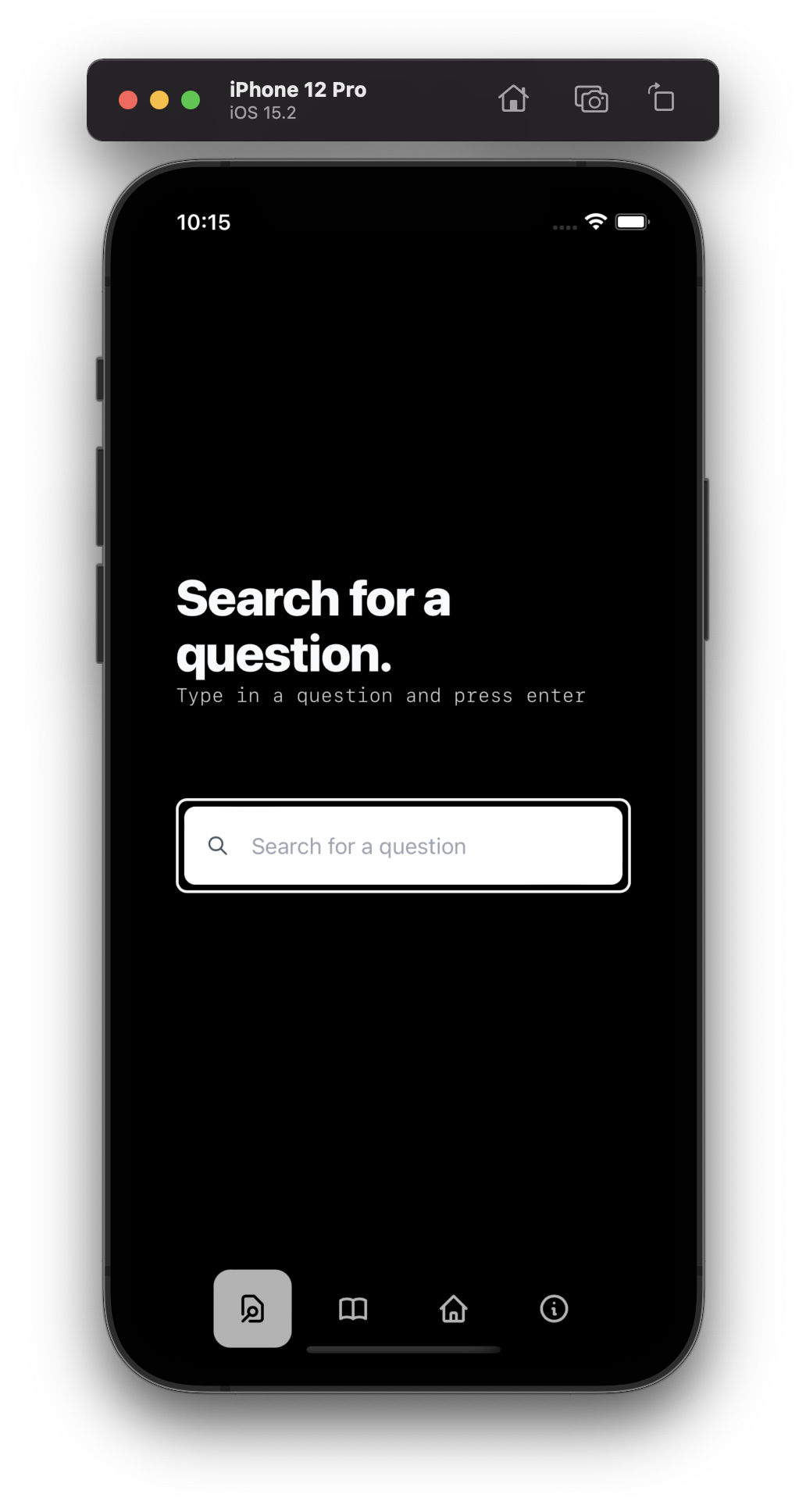
Search Page iOS
-

Search Example iOS


Inspiration
As a student, it's become almost a cultish mantra to do past paper questions to practice for exams. A necessary evil that millions of students do every day.
With each question I did, I grew a sense of hatred towards the idea of copying down a question into some piece of paper or printing it out and having a paperweight after. Even doing it digital didn't work since my notes app has already devoured my iCloud storage.
Like most projects I work on, It grew out of spite. The feeling that maybe I could make it better. The urge create another over-engineered solution to a non-problem.
And that I did.
What does it do?
Atlas Revision is a revision site. Duh.
It retrieves data from an API that returns questions extracted and categorized from past papers for all major CIE subjects. This data is then presented in a meaningful form where the student can solve the question and just click to reveal the answer.
The site also has really powerful search capabilities. I basically indexed all of CIE's past papers (for the major subjects) and you can just type in whatever question you got from somewhere and BAM found. It's like googling the question but you can use less of your brain.
How I built it?
It's really three separate systems working in tandem.
Question API It's essentially questions that are extracted from are-categorised into different topics. This raw data requires some process to properly format the meta-data so we use a python script to automate this process during which we also run pytesseract which helps extract text from the images. After we have all of this data we create an index using tantivy which is rust based full-text search engine similar to lucene in terms of architecture. We then serve this using a high-performance rust API. This means not only do we have an API allowing for serving the questions we can also perform dynamic queries without any further configuration to the API, instead of having full freedom to create complex queries client side.
Search API This is made using a similar approach to the question API except here we index pdfs instead of images. I have developed a pipeline for this process. First, we extract the pages from the pdf using pypdf. Then we extracted the text for each page using PyMuPDF. Then we have to generate a thumbnail for each page and we use PyMuPDF for this again and simply export the page into an image, we then have to optimize this image and upload it to Cloudinary which we will use as an image CDN. We can then do the same process as before and index each page along with the metadata and serve it on the same high-performance rust API.
Sveltekit Frontend This is the really special part. Mostly because it's the only part most people will ever see. Sveltekit already comes with a lot of stuff out of the box (which you know I take for granted). But why stop at a website right? That's why I used capacitorjs from the start allowing me to build cross-platform apps and test for many different screen sizes and resolutions using the simulators. The app was built to dynamically adapt and accommodate the mobile UI, optimizing it to utilize space efficiently without adding unnecessary clutter. Then effortlessly be able to expand to make full of a desktop resolution, because let's face it, most schools are running on Chromebooks, speaking of it can also build to a handy PWA so your browser can do the heavy lifting. The great thing about capacitor is that it comes with full access to the native APIs like storage, filesystem etc. This means if I implement a bookmark feature that uses the local storage API then Capacitor will take care of the interfacing with the native APIs so there is a level of abstraction that allows for a unified API regardless of hardware architecture. So that's pretty cool.
I already know that some people are already screaming "Why don't you connect to a database and have it connected to some profile", well simply because going in I wanted this app to take an offline-first approach. This is not some website. Well, obviously you need an internet connection to fetch data from the API once you do I want this app to be able to store the responses and function as normal without having to cry for help the moment the phone goes offline.
What I learned
- Drinking 3 mugs of coffee per hour is not healthy.
- CSS is hard.
- If you haven't taken the time to architect your systems and just go head first your going to drown. You need to make sure you start from a stable base so you don't build on dust pillars. I learned this the hard way when I tried to make separate flask endpoints in python reading and writing from a JSON file, it gets a bit depressing after the 30th.
What's next for Atlas Revision?
Well, the good news I the future for Atlas Revisions is bright.
The first thing to be changed is that awful flashcard like approach to solving questions. It's like I generated all this metadata and I'm flushing it down the drain. So I'm going to re-write that entire part with a quiz interface with checking of MCQ questions and either getting the student to check their structured questions manually or using GPT3 to check the answered by checking if the points in the marking scheme are present in the student answer.
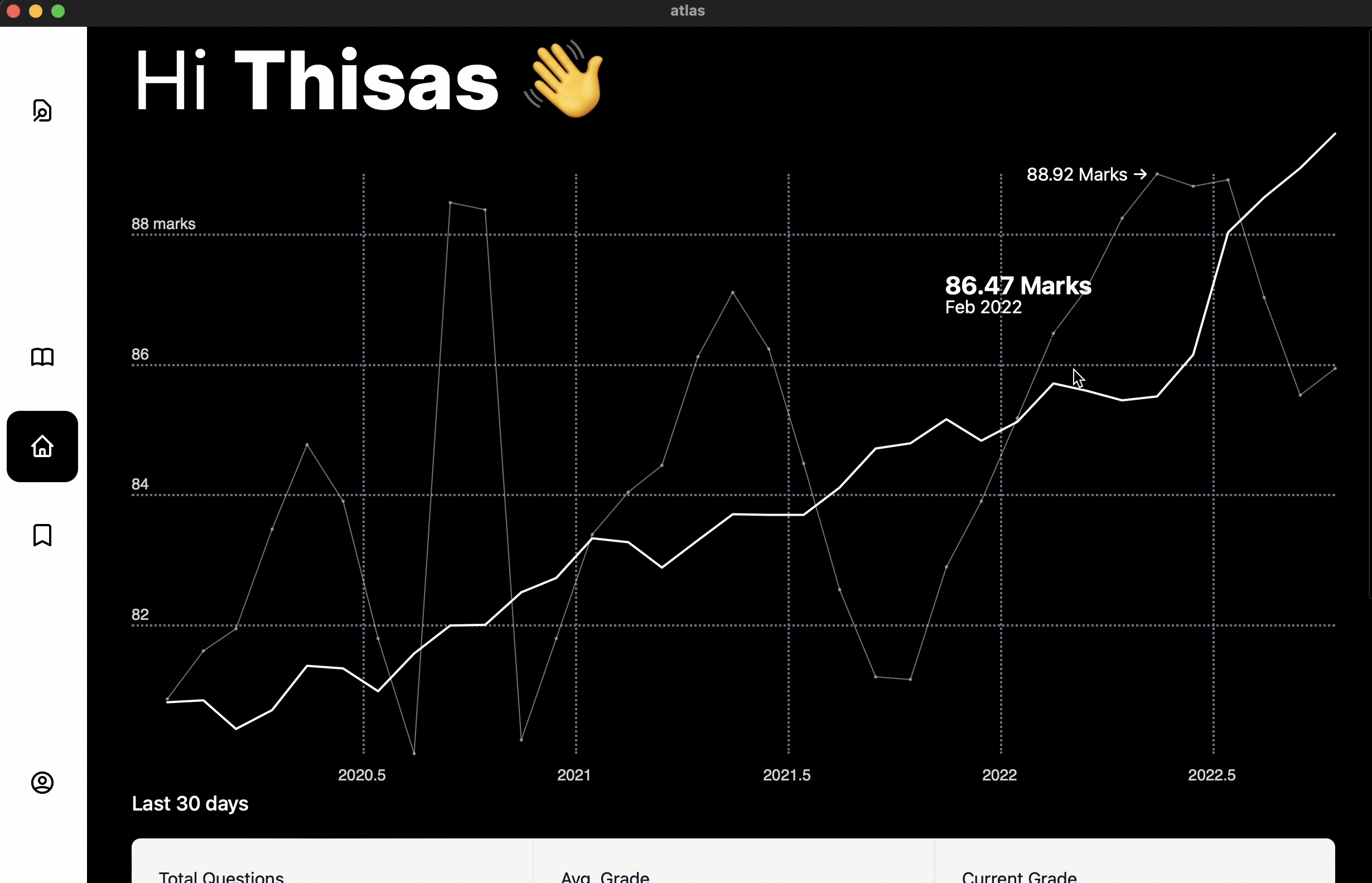
I really hope to implement that storage API that I could not shut up about and create and new API for processing data from the student and analysing meaningful trends to show how the student is doing probably using a simple linear regression algorithm. I created a chart component but it felt wrong having it with mock data so I instead used it to create a mock "coming soon" page on the front page so that later I can actually finish the project and populate it.
Built With
- capacitor
- capacitorjs
- rust
- svelte
- sveltekit
- tantivy
- vercel


Log in or sign up for Devpost to join the conversation.