-
-
Landing Page
-
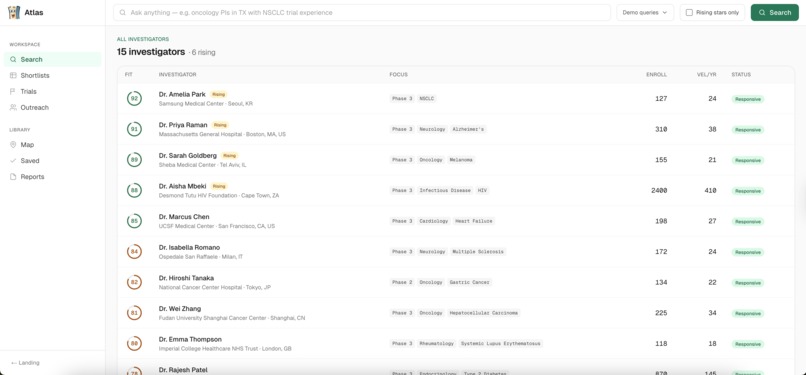
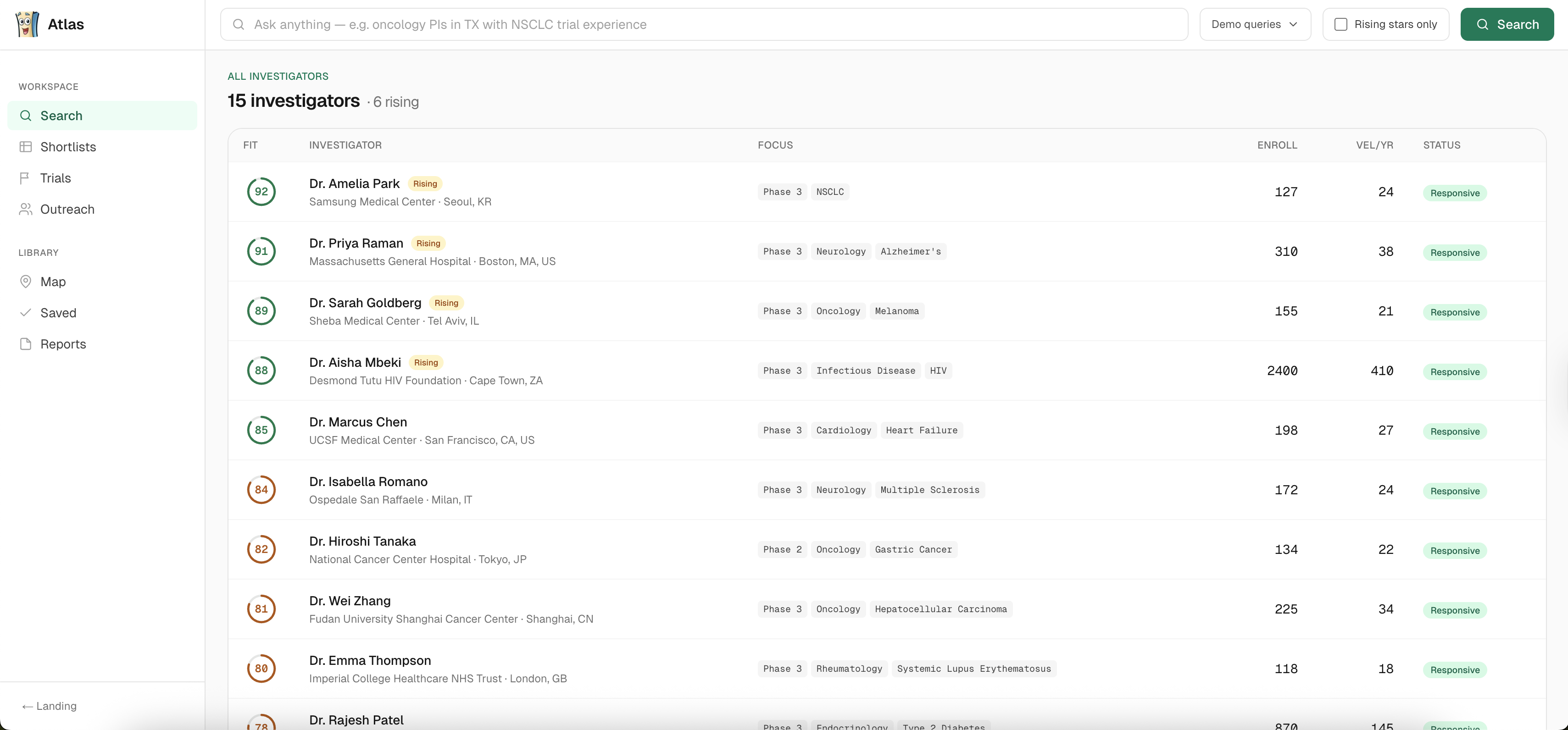
Home Page
Atlas
Six weeks of finding the right clinical trial investigators, compressed into about fifteen seconds.
The conversation that started it
We were wandering the hackathon sponsor booths when we ended up talking to Dr. Henry, a former medical director at Google. We asked him what part of clinical research he'd pay to make disappear.
No hesitation. Finding the right principal investigators for a new trial.
He walked us through how it works across the industry. For every new Phase 2 or 3 program, the clinical ops team spends about 6 weeks manually selecting investigators. One analyst digs through ClinicalTrials.gov. Another searches PubMed. A third pulls NPI records, CMS Open Payments, and FDA warning letters. Then someone sits with a dozen spreadsheets, trying to figure out whether the "Amelia Park" in one database is the same person as "Park A" in another, or as some ORCID number in a fourth.
Three things kept coming up. Nobody can agree who's who across databases. Bad news, like an old FDA warning letter, gets missed until you've already flown to the site. And whole regions stay invisible: a great PI in São Paulo or Cape Town doesn't show up in a search that defaults to US sites, so global trials keep getting run by the same handful of places.
At one point, he said something like, "These teams just want to describe the trial in plain English and get a ranked list back." That became our spec.
What Atlas does
You type a question the way you'd say it out loud.
- NSCLC principal investigator in Korea
- Traumatic brain injury PI in Pennsylvania with FDA IND experience
- Gene therapy Phase 1 investigator for rare retinal disease in Europe
About fifteen seconds later, you get a ranked shortlist. Each person has a fit score out of 100, a one-sentence reason for the match, and clickable evidence chips like pubmed:38100001 or nct: NCT05001234 that link straight to the row that justified the match. If we say someone's an NSCLC expert, you can see the paper.
Click a candidate, and you get their full profile: US and global trials, publications, credentials, IND filings, industry payments, any past FDA observations, plus the audit trail showing how we linked those records to the same person.
How we built it
Twelve public registries: hub-and-spoke. The investigators table is the hub; every other source links back to it, including ClinicalTrials.gov, the ICTRP global registries, PubMed, OpenAlex, NPI, FDA filings, and CMS Open Payments.
The biggest call we made was treating identity resolution as data, not logic. Instead of fuzzy matching strings at query time, we precomputed the links between sources and stored them in an identity_resolution_matches table with confidence scores. That way, the agent can warn you when a match is only 0.7 confidence instead of quietly pretending it's certain.
On top of that sit three Mastra agents. A query planner turns free text into structured filters. A search agent uses two tools: one to list candidates, one to pull a full profile for a given investigator by fanning out across every source table in parallel. A rating agent assigns a score of 0 to 100 to each candidate. The whole pipeline runs from one server action.
What went wrong
The worst hour was a TypeError: Cannot read properties of undefined (reading 'candidates') that killed every run. Two Mastra gotchas stacked on top of each other. The default maxSteps is 5, and our agent burns 1 step per candidate profile, so we'd hit the cap mid-loop with no output. And when an agent has tools and wants structured output, you have to pass structuredOutput.model so the tool loop and the structuring pass run as separate phases. Without it, the final response comes back as raw text, and result.object is undefined. Fix: maxSteps: 20 and structuredOutput: { schema, model: openai("gpt-4o-mini") }.
We also started with twelve tools, one per table. The agent got indecisive, and the prompt ballooned. Collapsing to one profile tool that fans out internally made everything cleaner.
The whole pipeline takes fifteen seconds, which is long for a search, so we added a loading state ("Agents are searching across 12 data sources...") to keep it from feeling stalled.
What we're proud of
Every match is traceable. We refused to ship a product where the LLM says, "trust me." If the agent can't cite specific IDs, it doesn't rank the person.
The seed database is small but rich. Fifteen investigators across fourteen countries and twelve therapeutic areas, each with a unique signal fingerprint, so that HIV PrEP investigator in South Africa and lupus PI in the UK each resolve to exactly one person.
And the thing actually does what Dr. Henry said those teams wanted. Type NSCLC principal investigator in Korea and you get Dr. Amelia Park, with chips linking to her Lancet Oncology paper, two NCT trials, the EU cross registration, and her OpenAlex profile. One search.
What we learned
Entity resolution is the product. The moment we treated it as a data structure with confidence scores rather than a search-time heuristic, everything downstream became easier.
Fewer broad tools beat many narrow ones. Agents with big tool surfaces waste tokens deciding which one to call.
Industry context beats feature count. The hour with Dr. Henry shaped the product more than any architecture diagram. Evidence chips became a requirement the moment he mentioned the FDA letter blind spot.
What's next
Semantic search over PubMed abstracts with pgvector, so we catch topically relevant work without exact tag matches. Ranking that knows the sponsor, so a Regeneron search upweights Regeneron's own study networks. PDF export of a rated candidate in one click. More registries like SAM.gov and CITI. A feedback loop that learns from which candidates get shortlisted or rejected.
Built With
- mastra
- next.js
- openai
- supabase
- typescript

Log in or sign up for Devpost to join the conversation.