
Inspiration
Training a single frontier model can consume as much electricity as a small town uses in a year. But frontier models aren't the only problem, the millions of ordinary training runs happening every day in research labs, startups, and university notebooks add up just as fast. The difference is that frontier labs have infrastructure teams optimising for efficiency. Everybody else has 0 idea what's going on.
The core issue isn't that developers don't care about sustainability, it's that they get no feedback signal. A developer can instantly see if their model's accuracy is wrong, but has no idea whether their architecture is burning three times more CO₂ than it needs to, whether their model converged at epoch 4 and they ran it to epoch 20, or whether a dead layer has been consuming compute and emitting carbon while contributing nothing to the model's output. You can't optimise what you can't see.
We aimed to build the missing feedback loop by putting the developer at the center of the training process: Our dashboard delivers real-time sustainability metrics directly to the engineer and actively prompts them with actionable insights about their architectural and training decisions based on sustainability metrics. At key moments, the developer is prompted with warnings and optimization suggestions, and decides whether to continue, adjust, or stop the run. Instead of waiting for the model to be trained in full, the system creates an interactive loop where the developer makes informed, sustainability-aware decisions in real time, before wasting compute on training an inefficient model.
What it does
Atlas is a real-time ML training observatory that instruments PyTorch training loops and surfaces sustainability insights as a first-class concern alongside the usual metrics (loss, accuracy, throughput) while keeping the engineer in the loop.
Atlas seamlessly integrates into any existing PyTorch model with minimal changes, thanks to our "Observer" library, which silently monitors and streams the training process to our dedicated backend, which then runs diagnostics on the raw telemetry data:
from observer import Observer, ObserverConfig
config = ObserverConfig(
track_profiler=True,
track_memory=True,
track_throughput=True,
track_layer_health=True,
track_sustainability=True,
track_carbon_emissions=True,
)
observer = Observer(
project_id=1, # integer project id
run_name="my-run",
config=config,
)
observer.log_hyperparameters({
"batch_size": 64,
"num_epochs": 10,
"learning_rate": 3e-4,
"optimizer": "Adam",
})
observer.register_model(model) # register the model architecture in order to visualize it in the front-end
for epoch in range(num_epochs):
for step, (x, y) in enumerate(train_loader):
x, y = x.to(device), y.to(device)
logits, loss = observer.step(model, x, y) # Simply hook in to the training step
optimizer.step()
optimizer.zero_grad(set_to_none=True)
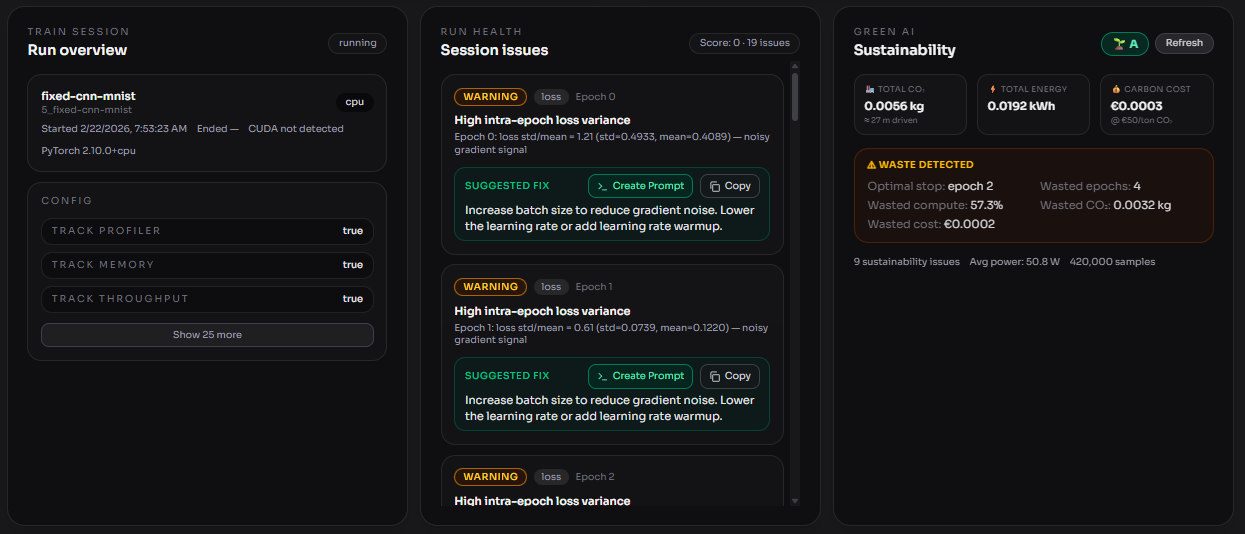
Carbon tracking per epoch. Atlas integrates CodeCarbon to measure energy consumption and CO₂ emissions at the epoch level, not just as a run total. This means you can see exactly when your model stopped improving and started emitting carbon for nothing.
Wasted compute detection. The diagnostics engine automatically identifies the optimal stopping point — the epoch where marginal loss improvement fell below a meaningful threshold. This is shown in the dashboard as kg CO₂, kWh, and a EUR cost using EU ETS carbon pricing (€50/tonne) — making the environmental waste legible in financial terms developers and their organisations already reason about.
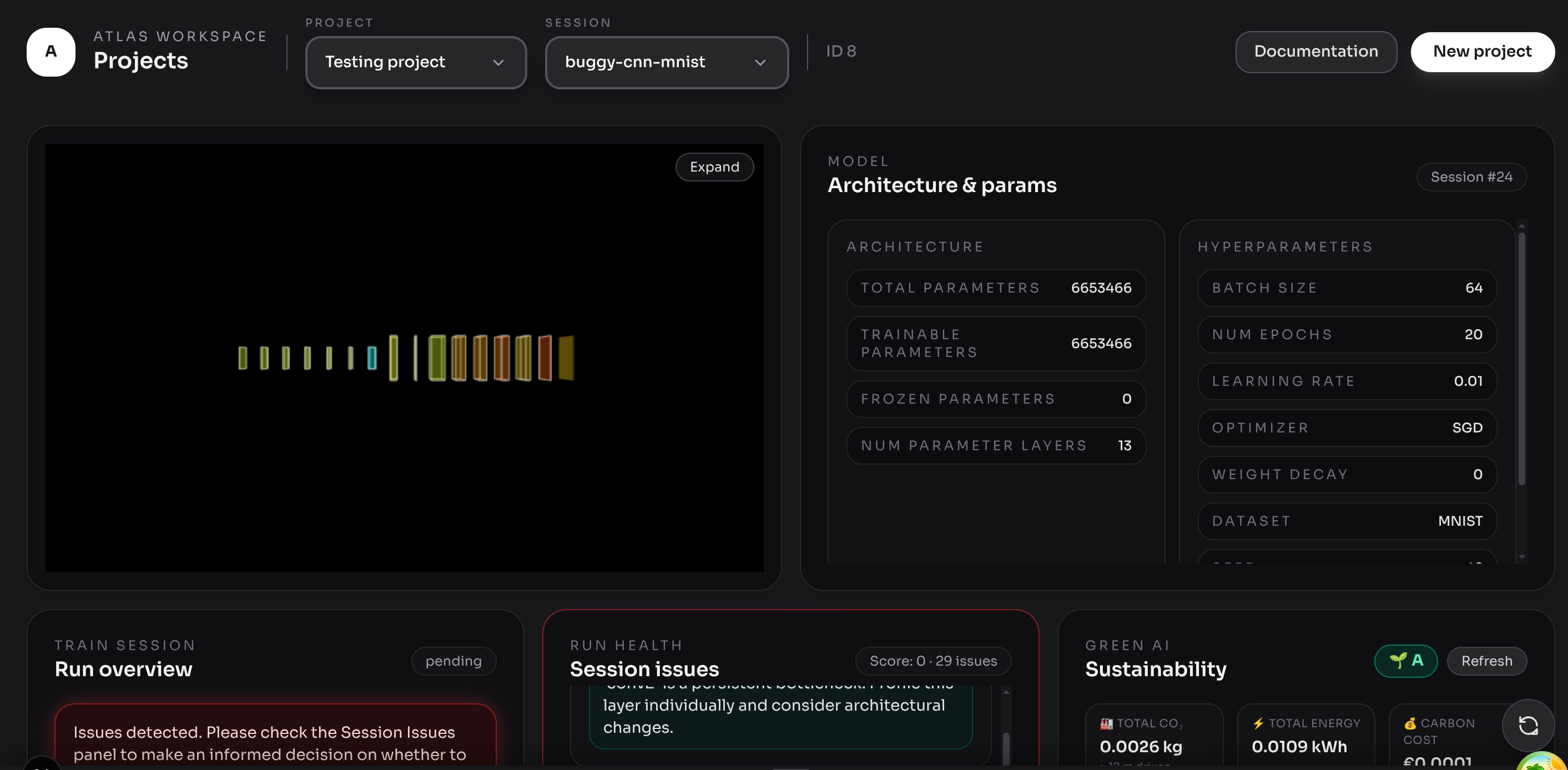
Architectural efficiency grades. Every session receives a sustainability grade (A–F) computed from 30+ heuristic checks across six categories:
| Category | What it catches |
|---|---|
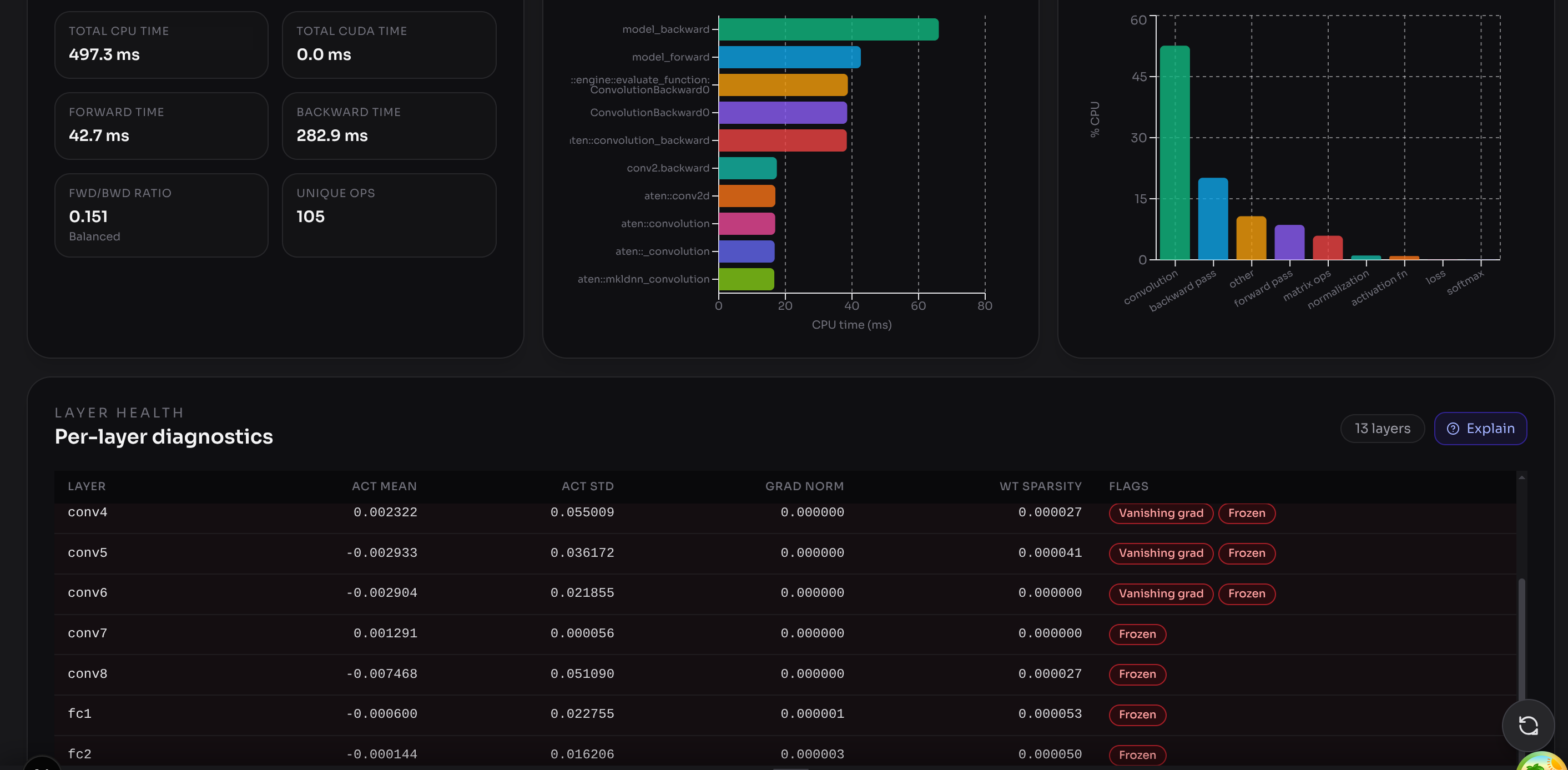
| Layer health | Dead layers (near-zero activation variance + high weight sparsity) wasting forward/backward compute |
| Gradient health | Vanishing gradients ($\ |
| Architectural waste | Over-parameterised layers (param% / compute% > 10×), redundant layers (activation correlation > 0.95) |
| Early stopping | Training continued past optimal convergence point |
| Device utilisation | GPU powered but utilisation < 20% — paying for hardware not being used |
| Carbon spikes | Epochs with CO₂ > 10× session average — often caused by profiling, data loading bottlenecks, or recomputation |
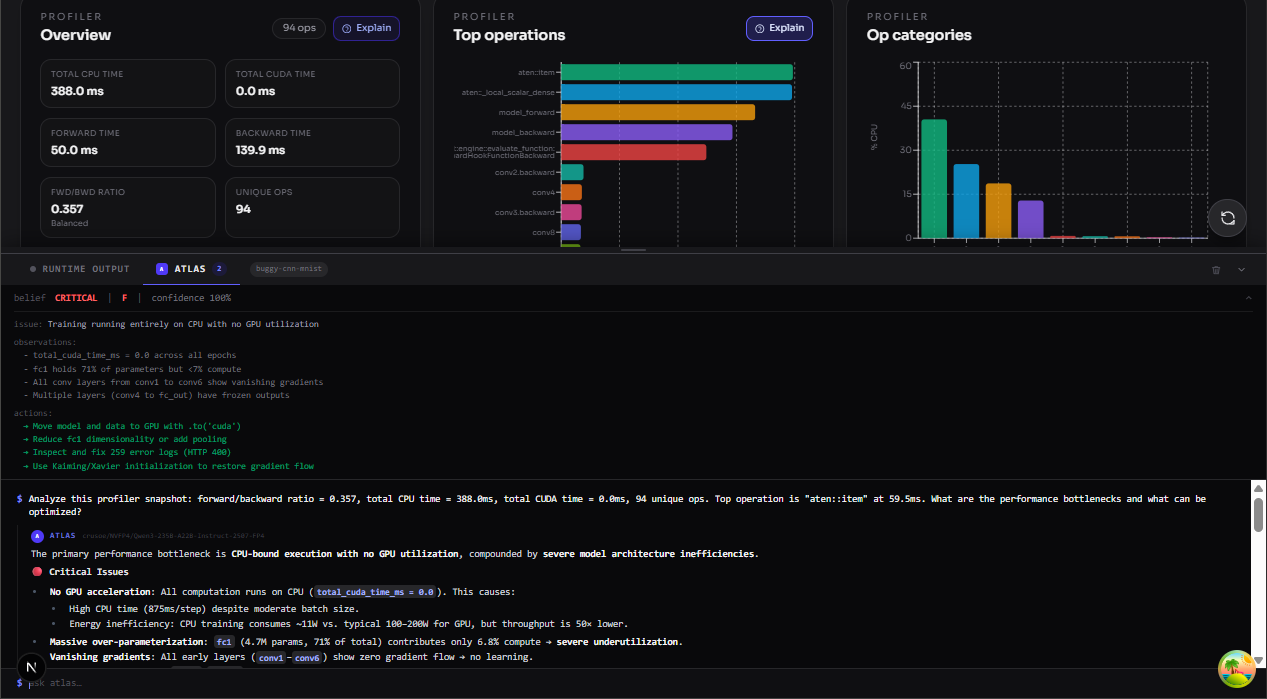
Atlas AI agent. An embedded conversational agent with direct access to training data and diagnostic results. It doesn't just report, it explains why an issue matters for sustainability and gives concrete architectural suggestions (reduce depth, add early stopping, replace FC-dominated architecture with conv layers, etc.). The agent maintains a belief state that updates as new epochs arrive, so its advice evolves as training progresses.
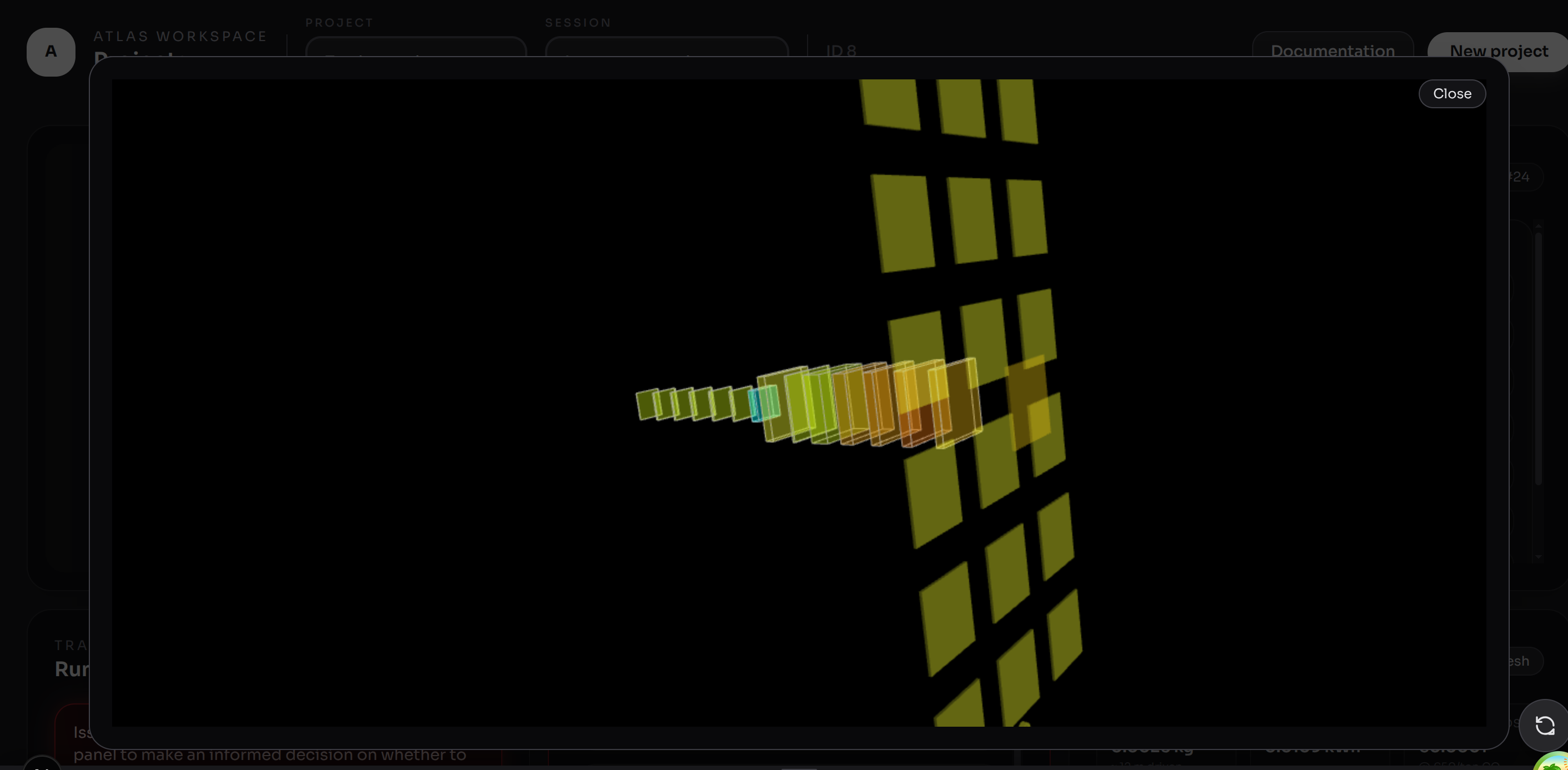
3D architecture visualiser. Layers are colour-coded by their sustainability score, making it immediately obvious which parts of the network are healthy versus wasteful.
How we built it
Observer (Python): A lightweight library that wraps any PyTorch training loop.
Calls observer.step() in user-define intervals. Under the hood the PyTorch profiler and custom telemetry code is hooked in to monitor the training process. The raw telemetry data is then streamed in real-time to the backend.
Backend (FastAPI): Receives step telemetry and triggers the diagnostics engine to turn the raw telemetry into actionable insights for the engineer. The Atlas agent runs on Crusoe Cloud's Qwen3-235B, with Anthropic Claude as fallback, over an OpenAI-compatible tool-calling loop.
Frontend (Next.js 16): A clean dashboard which visualises all of the data in an insightful manner to the engineer, allowing them to make more informed decisions early into the training process.
MCP server: All diagnostic tools are exposed via the Model Context Protocol so Atlas can be queried directly from Claude Desktop, letting developers ask sustainability questions about their runs without opening a browser.
Challenges we ran into
Obtaining insightful data from training runs. The first, and most important challenge, was to obtain insightful data from the PyTorch training runs. We managed to collect valuable raw data using a combination of the PyTorch profiler and custom telemetry code. Next we had to implement smart heuristics and tools, in order to go from raw data to actionable insights.
Observer reliability. A telemetry bug should never kill a 12-hour training run. Implementing a robust observer that is practically invisible to the training process was a core requirement.
Making sustainability metrics actionable, not decorative. Raw CO₂ numbers mean little to most developers. We went through several iterations on how to present them - landing on a combination of EU ETS cost in EUR, a letter grade, and concrete comparisons - to make the environmental impact visceral enough to actually change decisions.
Defining "wasted compute" rigorously. Optimal stopping is subjective. We settled on marginal loss improvement as a fraction of cumulative improvement, with a 5% threshold, because it captures the intuition that you should stop when each new epoch is contributing less than 5% of the total gain made so far. Getting that threshold to fire correctly on both fast-converging CNNs and slow-converging transformers required careful calibration against real runs.
Accomplishments that we're proud of
Sustainability is primary, not a tab. In most ML tooling, energy and carbon metrics are buried in an afterthought panel. In Atlas they appear alongside loss and accuracy from the very first epoch, because a model that converges faster with fewer dead layers isn't just more accurate, it's cheaper to run and better for the planet.
For the first time ever, the engineer is now directly in the sustainability feedback loop. A developer can start a training run, wait for the diagnostics to run, and catch unsustainable architecture decisions early on in the training process, without wasting compute.
30+ checks that work on real models. Using an intentionally broken MNIST model, reliably triggers dead layer detection, FC dominance warnings, missing pooling alerts, and an early-stopping missed flag.
CO₂ in terms engineers understand. Showing that a poorly structured 20-epoch run emits the equivalent of driving 12 km, when an architecturally sound 6-epoch run achieves the same accuracy with one-third the emissions, is the kind of comparison that actually lands in a code review.
What we learned
- The biggest sustainability win in ML is often not hardware or data centre choice — it's stopping training earlier and not training broken architectures. Both are software problems.
- Developers respond to sustainability feedback when it's framed as efficiency, not guilt. "You're wasting 40% of your compute" lands differently than "you're emitting too much CO₂" - even though they mean the same thing.
- CodeCarbon's offline grid-intensity mode is reliable enough for per-epoch CO₂ estimates without any external API dependency, critical for local development environments where real-time grid data isn't available.
- Tool-calling agents with direct database access produce more accurate sustainability analyses than RAG over logs, because they can compute exact epoch deltas, layer ratios, and carbon timelines rather than approximating from retrieved text.
What's next for Atlas
Adaptive diagnostic thresholds. Use historical runs within a project to calibrate thresholds — "plateau" defined relative to this model's typical improvement curve, not a fixed global 1%.
Framework support beyond PyTorch. A JAX / Flax Observer using the same HTTP protocol, making the backend and dashboard framework-agnostic.
Expand to other neural networks. Currently Atlas only fully supports CNN's, the next obvious step is to fully support other neural networks as well.
Automate architecture changes using a Coding Agent. The engineer still has to manually apply changes to the neural network whenever an issue is detected. Even though we provide easy-to-copy prompts and an MCP server, automating the editing of the architecture would still significantly improve the development process.
Persistent agent memory. Store belief state across sessions so Atlas can say "last time you trained this architecture, you hit the same vanishing gradient issue at epoch 3 and wasted 0.8g CO₂ before catching it — here's how to avoid it this time."

Log in or sign up for Devpost to join the conversation.