Inspiration
Healthcare claim denials cost the US system billions annually and burden both providers and patients. We wanted to leverage publicly available NPPES data to predict which healthcare providers might face compliance issues that correlate with higher claim denial rates, helping administrators proactively identify and address risks.
What it does
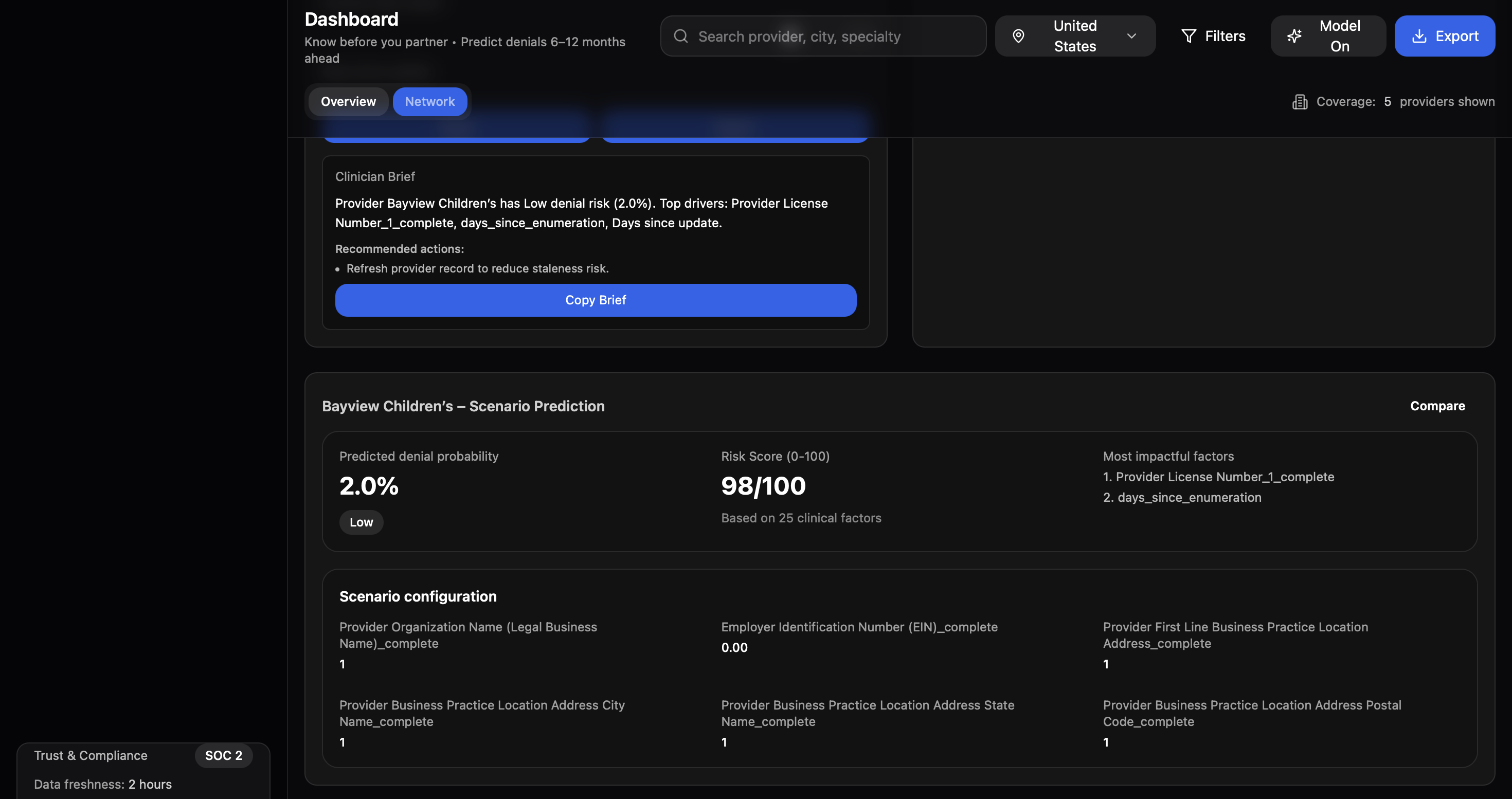
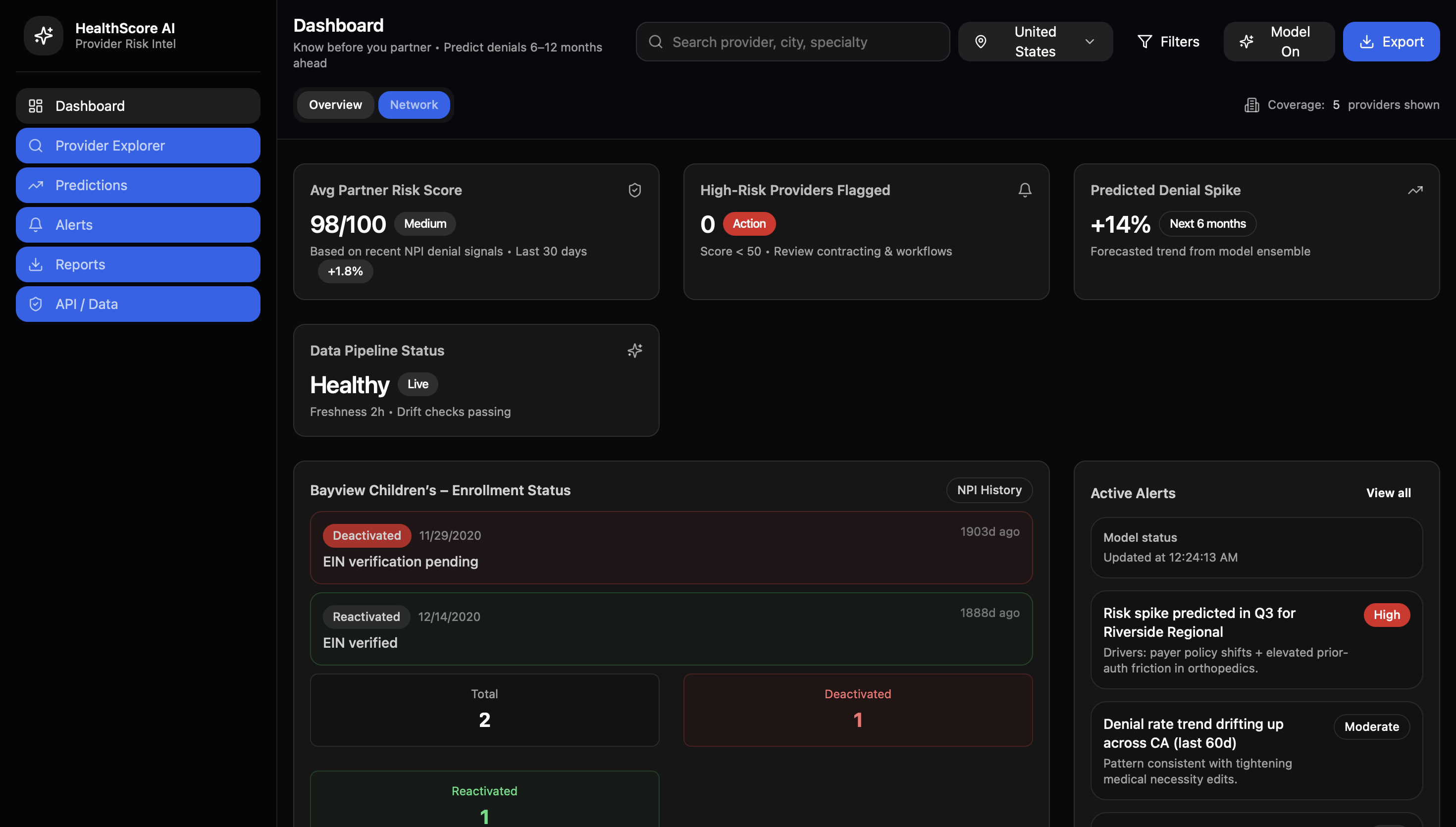
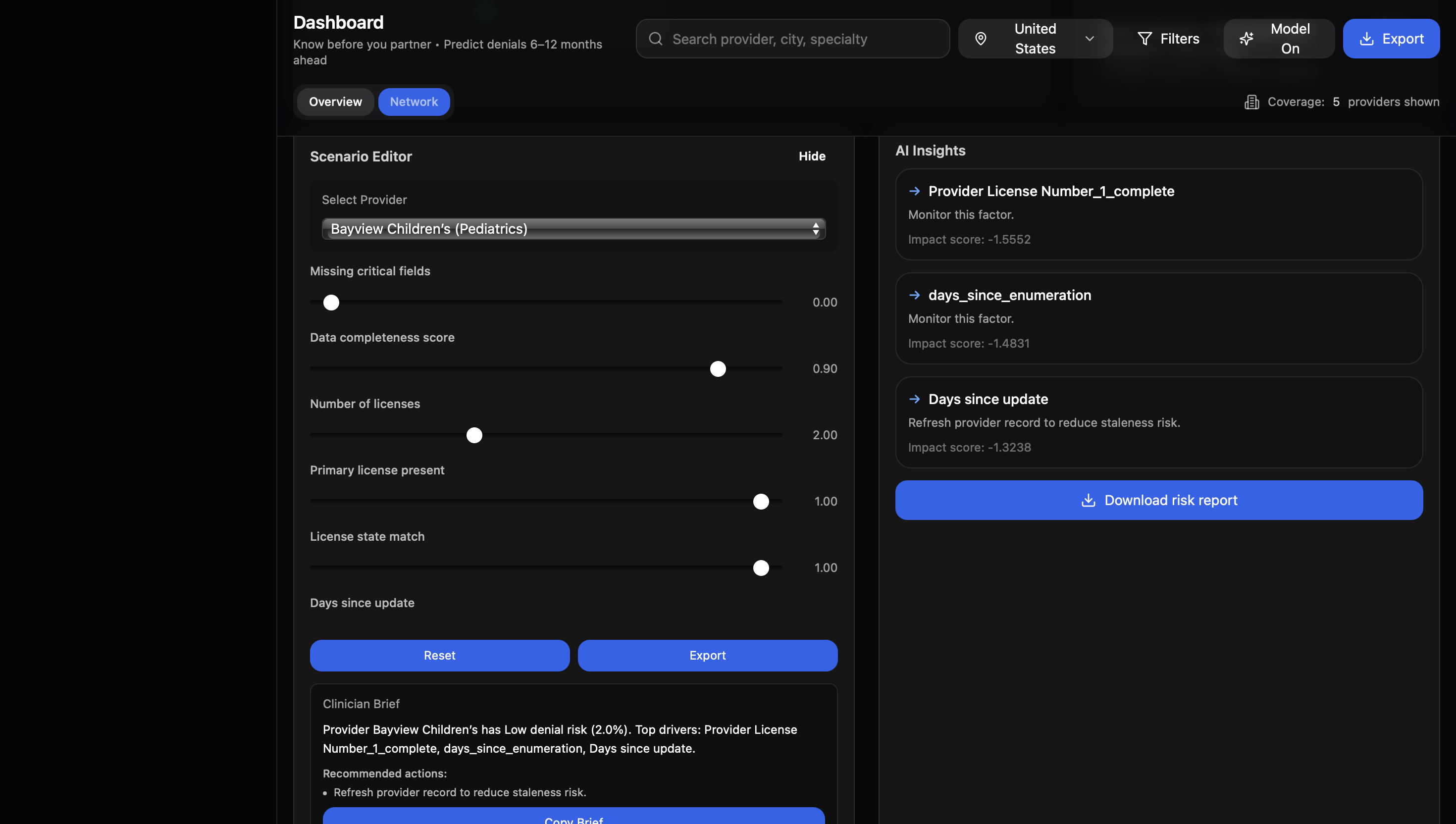
AthenaCare uses machine learning to predict healthcare provider risk levels based on deactivation history and data quality patterns. It analyzes 7+ million provider records from NPPES, extracting features like data completeness, taxonomy codes, license information, and geographic patterns to generate risk scores (High/Medium/Low) via an API endpoint.
How we built it
ML Pipeline: XGBoost model trained on NPPES provider data (11GB dataset) Feature Engineering: Created 20+ features from data completeness scores, provider taxonomy, license info, deactivation history, and geographic patterns Class Imbalance: Used SMOTE oversampling and class weights to handle severe imbalance (0.35% deactivation rate) Experiment Tracking: Integrated Weights & Biases for metric logging and model versioning Deployment: Built REST API for real-time predictions
Challenges we ran into
Working with the NPPES dataset presented significant technical hurdles from the start. The raw data file was 11GB containing over 7 million healthcare provider records, which immediately caused memory overflow errors when we attempted to load it into pandas. We had to implement chunked reading strategies, processing the data in 100,000-row batches and using efficient data types (categorical for taxonomy codes, int32 instead of int64) to reduce memory footprint by nearly 60%. Even with these optimizations, feature engineering would crash on the full dataset, so we built our pipeline to save intermediate results to disk and implemented aggressive garbage collection between processing steps.
The class imbalance problem was even more severe than typical ML projects - only 0.35% of providers had deactivation history, meaning our target variable had a 285:1 ratio of negative to positive cases. Initial model runs simply predicted "never deactivated" for every provider, achieving 99.65% accuracy but zero predictive value. We experimented with multiple balancing techniques including undersampling (which discarded too much data), class weights (which helped but wasn't enough), and ultimately settled on SMOTE oversampling combined with stratified train-test splits. This required careful tuning since over-aggressive SMOTE created synthetic samples that didn't represent real provider patterns, leading to models that performed well in training but poorly on real data.
Memory constraints plagued us throughout model training as well. Given the hackathon's tight timeline, we specifically chose XGBoost over deep learning alternatives (neural networks, transformers) because it offers dramatically faster training times on tabular data - critical when we only had 24-36 hours to iterate on our approach. However, even XGBoost's default behavior loads the entire training matrix into RAM, which caused crashes when training on the full 7 million row dataset with our engineered feature set. We reduced the training sample to 500,000 providers initially, implemented early stopping to prevent unnecessary iterations, and used XGBoost's built-in checkpoint saving to avoid losing progress during long training runs. We also experimented with tree depth limits and reduced the number of boosting rounds, finding a sweet spot that balanced model performance with computational feasibility. The final model trains in about 15 minutes on the sampled dataset compared to the 3+ hours (and frequent crashes) we experienced initially, and this rapid iteration speed was essential for testing different feature engineering approaches and hyperparameter configurations within the hackathon timeframe.
Accomplishments that we're proud of
We successfully built a production-ready data pipeline that processes and engineers meaningful features from 7 million+ healthcare provider records, transforming raw NPPES registration data into a clean, structured dataset with over 20 predictive features. This pipeline doesn't just handle the current data—it's designed to scale and run incrementally as NPPES releases monthly updates, automatically detecting new providers and updating risk scores. The broader implication is significant: hospital networks and insurance companies can now leverage publicly available government data to flag potential compliance issues before they result in claim denials, potentially saving millions in denied claims and administrative overhead.
Perhaps most importantly, we created a deployable REST API that accepts NPI numbers and returns risk predictions in milliseconds, making it trivial to integrate into existing healthcare workflows. This can plug directly into Epic Systems or Cerner EHR platforms that major hospital networks like Cleveland Clinic, Mayo Clinic, and Kaiser Permanente use - administrators could see risk flags right in the provider registration interface. Smaller community hospitals and rural health systems, which often lack sophisticated analytics teams, could particularly benefit since AthenaCare provides enterprise-level risk intelligence through a simple API call. The technology is needed because current provider credentialing and claims management systems are largely reactive - they detect problems only after denials occur. AthenaCare enables a proactive approach, identifying potential issues during provider onboarding or before claim submission, fundamentally shifting healthcare administration from firefighting to prevention.
What we learned
We learned how to integrate a self-built ML model into a fully deployed website, implement feature engineering pipelines, tune hyperparameters through trial and error, and clean massive amounts of data efficiently. Technically, we got deep experience working with diverse and fragmented datasets, implementing chunked reading and streaming to process 10+ GB NPPES files without crashing our laptops, and optimizing memory usage through smarter data types. But the bigger revelation was discovering how much valuable healthcare data just sits unused. NPPES has detailed info on 7 million providers that almost nobody is leveraging for predictions or analytics. We realized that most healthcare inefficiency comes from clinicians and administrators only having local context, they see their own denial rates rising but have no way to benchmark against peers, spot broader patterns, or learn from what works elsewhere. This excessive fragmentation creates billions in preventable waste. Working on this problem got us genuinely excited about building in healthcare long-term. The combination of massive impact potential, hard technical problems, and obvious unmet needs made us realize we want to found companies in this space that bridge data gaps and give providers real intelligence instead of just local guesswork.
What's next for AthenaCare
we're planning to expand AthenaCare's capabilities to accept individual claim information as input before submission. This would involve taking in CPT procedure codes, ICD-10 diagnosis codes, patient demographics, and prior authorization status to predict denial risk for specific claims, not just providers. For example, a hospital could submit a proposed claim for a knee replacement surgery and receive a risk score indicating whether that specific combination of provider, procedure, diagnosis, and patient characteristics is likely to be denied.
We want to expand the input types to include unstructured data as well. Medical billing notes, prior authorization denial letters, and appeal documentation contain rich contextual information that our current structured-feature approach misses. Using natural language processing, we could extract denial reasons, identify documentation gaps, and learn which appeal strategies are most effective. For example, if a provider's appeal letters frequently mention "medical necessity not established," the system could flag that as a training gap and recommend specific documentation improvements.

Log in or sign up for Devpost to join the conversation.