Inspiration
The internet is a powerful source of information, holding insights that can help predict financial shifts, geopolitical trends, and emerging threats. As AI becomes woven into daily life, the value of harnessing online information is clear—but capturing and structuring this data for analysis can be time-intensive and costly.
What it does
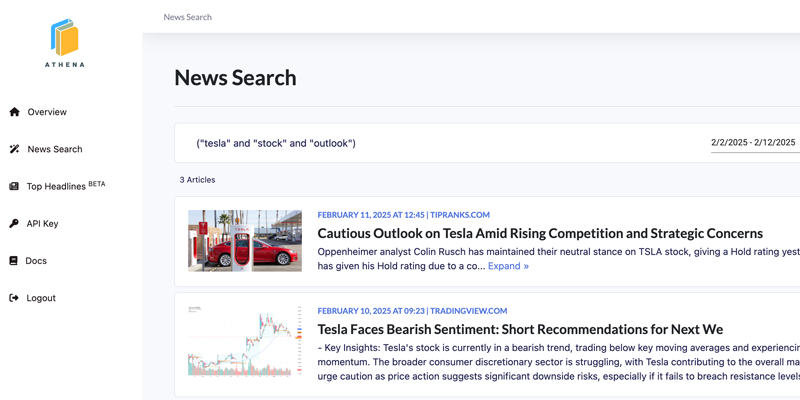
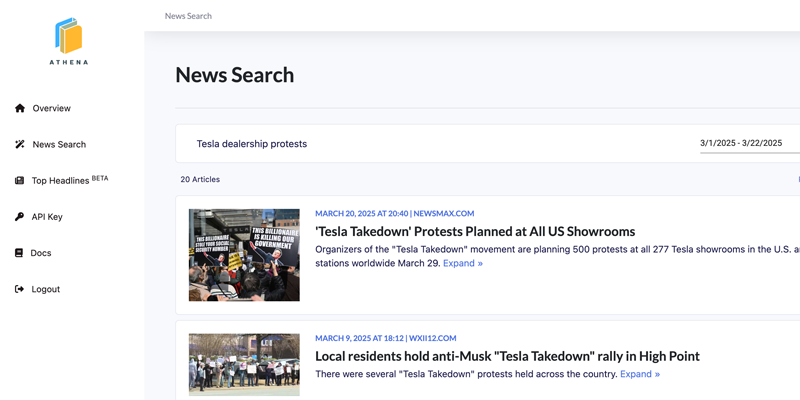
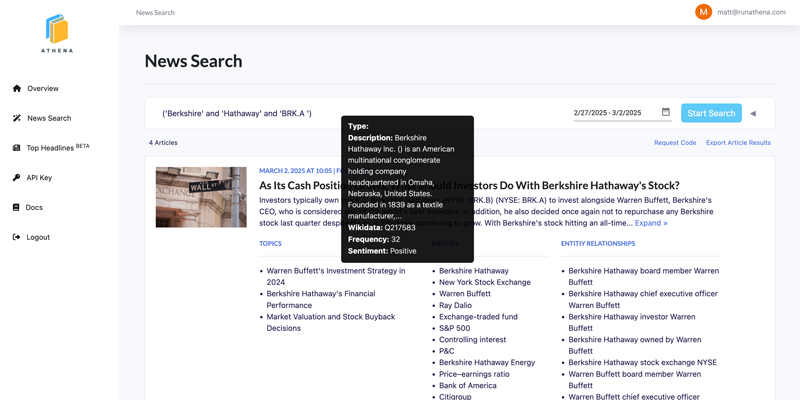
Athena simplifies this process by handling all data preprocessing for you. It gathers articles from thousands of sources, transforms article text into embeddings, extracts entities, and maps relationships, enabling you to focus on analysis and model-building rather than data prep. With historical data back to 2006 and nearly a million new articles added daily, Athena provides unmatched coverage to fuel your insights.
How I built it
The application is really broken down into a few components:
- Ingestion
- Enrichment
- Search and Article Retrieval
For each section, I tried to take a 'best of breed' approach. Gather the cleanest article text, use bleeding-edge NLP and LLMs to identify and map entities, and leverage hybrid text + vector/semantic search to generate the most relevant search results possible.
Challenges I ran into
Optimizing database indexes to control instance size Relevancy scoring when doing hybrid text + semantic search Leverage cloud-based GPU compute
Accomplishments that I'm proud of
Each phase of the project has given it's own unique challenges. I'm proud of the end-product.
What's next for Athena News API
New API endpoints, including "headlines", "entities" and "knowledge graph".

Log in or sign up for Devpost to join the conversation.