-
-
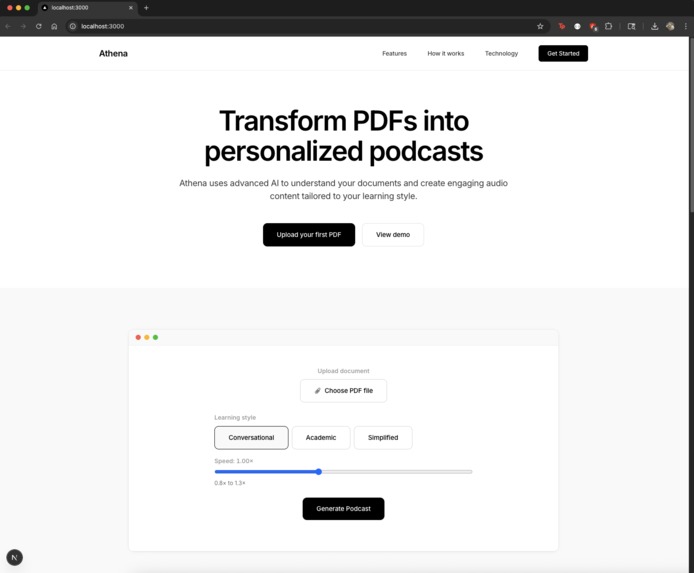
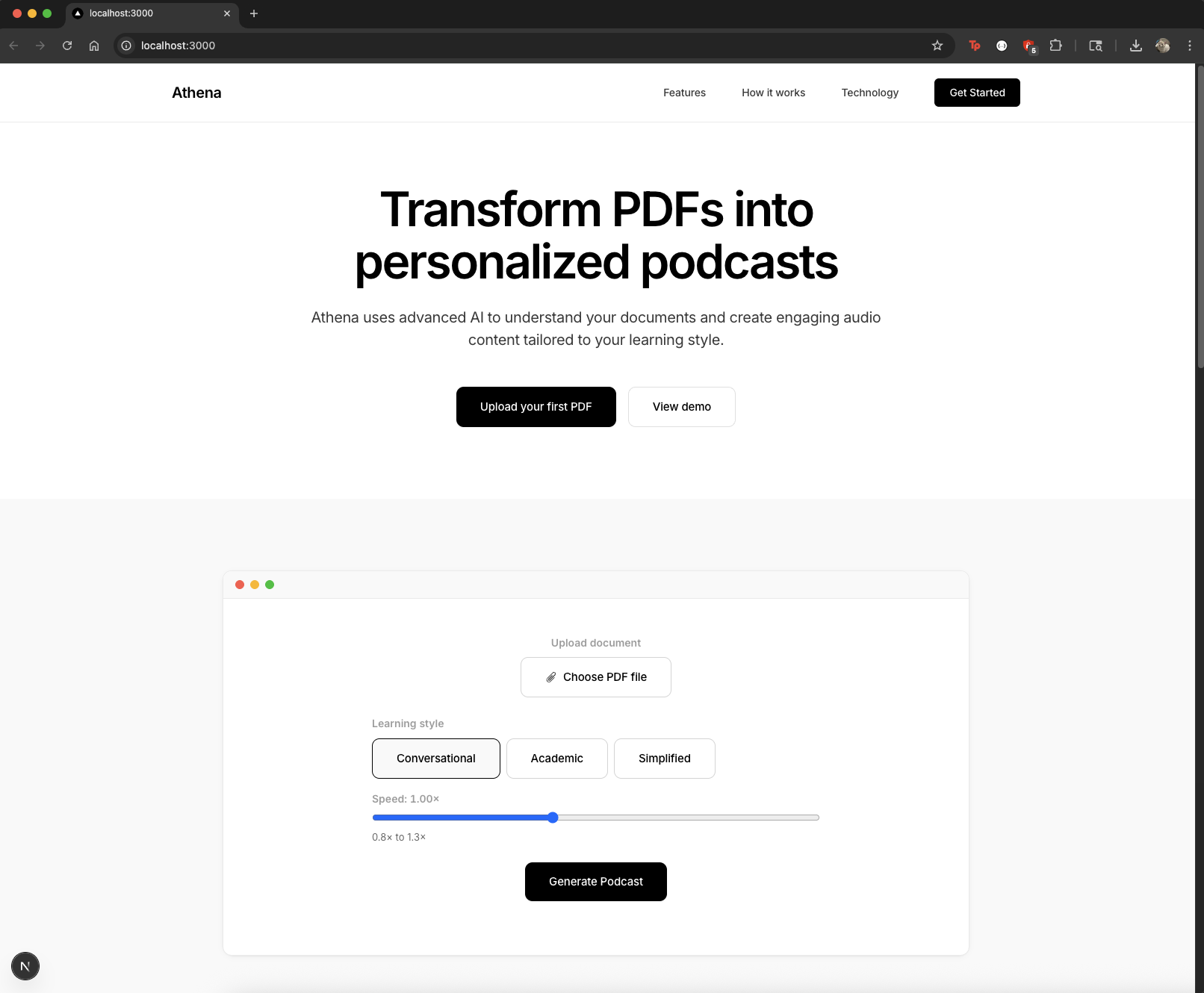
Landing Page
-
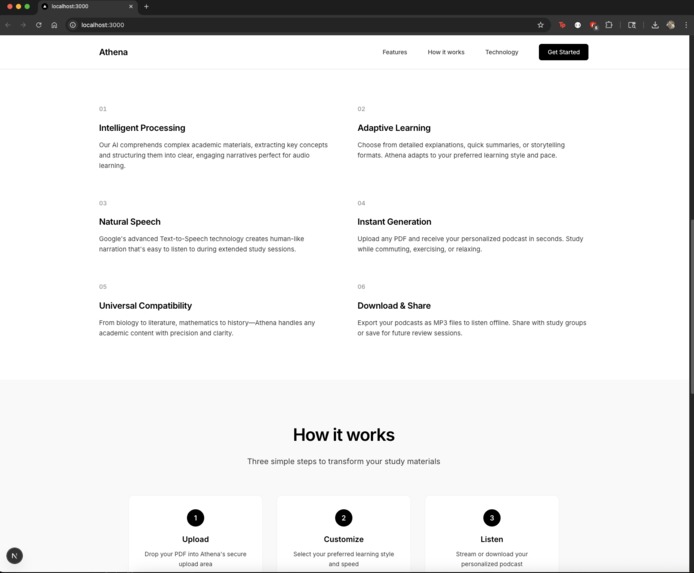
Features
-
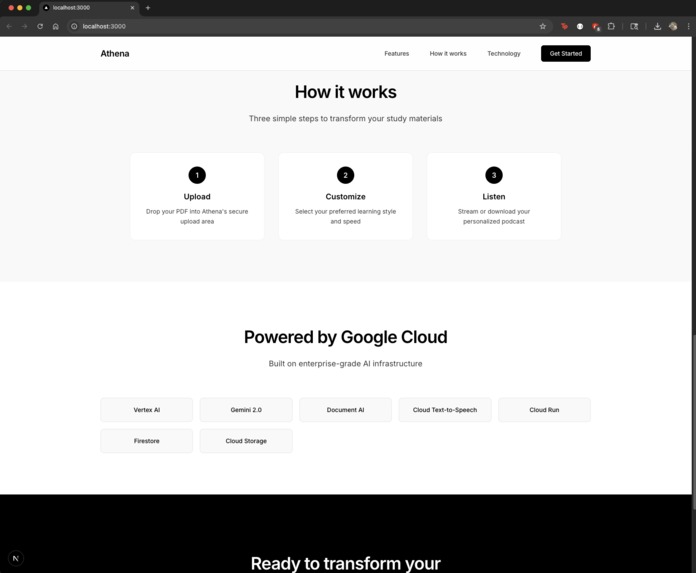
How it Works and Technology Used
Inspiration
We were inspired by the challenges that many students face when dealing with mountains of reading material and limited time. As students ourselves, we've experienced the frustrations of dense PDFs, research papers, and textbooks piling up faster than we can read them. What if we could transform these materials into engaging podcasts that we could listen to during commutes, workouts, or while doing chores.
Athena was born from this need to make learning more accessible and flexible. What if we could turn study materials into engaging personalized podcasts?
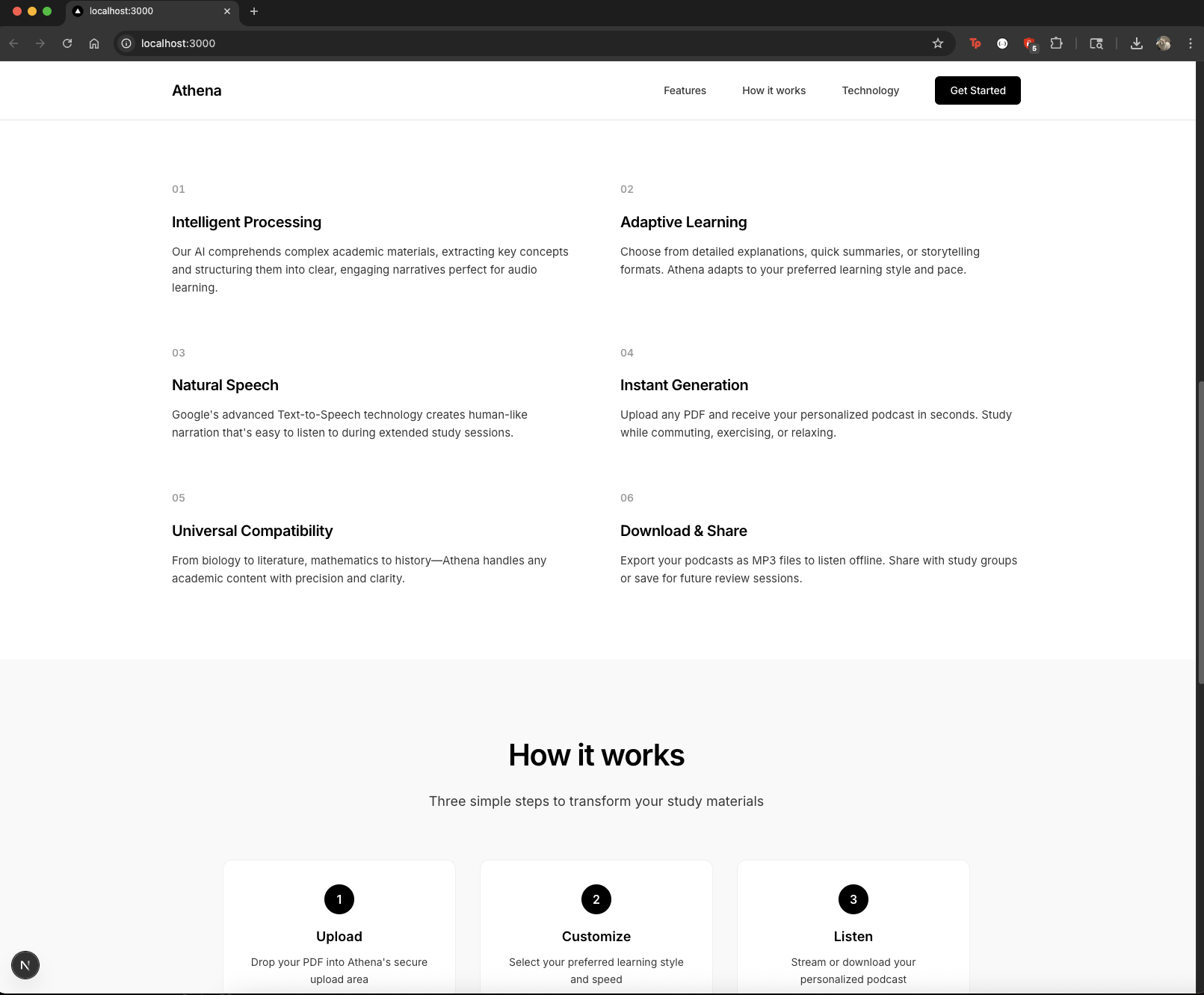
What it does
Athena converts any PDF into a structured, natural-sounding, structured podcast using Google Cloud's advanced AI services. It:
- Extracts content from PDFs using Google Document AI (with OCR support for scanned documents)
- Generates engaging podcast scripts using Vertex AI's Gemini 2.0 model in multiple styles (conversational, academic, or simple)
- Creates natural-sounding audio using Google Cloud Text-to-Speech
- Delivers a smooth web interface built in Next.js for uploading files, customizing playback, and listening on demand
- Offers customization options for duration, speaking rate, and narration style
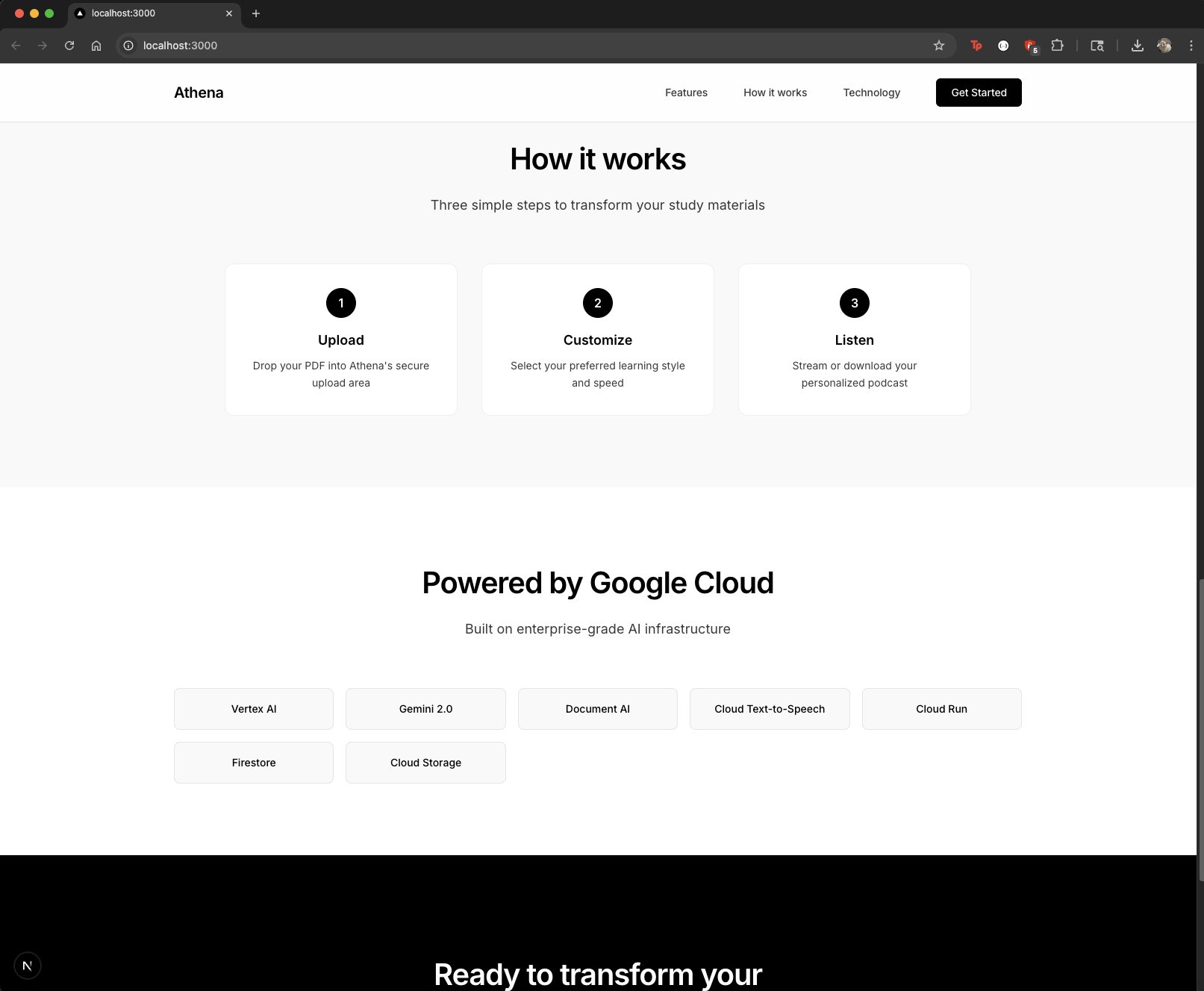
How we built it
Backend (Python + FastAPI)
- FastAPI for high-performance REST API with automatic documentation
- Document AI for intelligent PDF text extraction with OCR capabilities
- Vertex AI with Gemini 2.0 for transforming extracted text into engaging podcast scripts
- Cloud TTS for generating natural-sounding audio with SSML support
- Docker containerization for consistent deployment across environments
Frontend (Next.js/React)
- Next.js 14 with App Router for a modern, performance web interface
- TypeScript for type safety and better developer experience
- Tailwind CSS for responsive, beautiful UI design
- Async file uploads with progress tracking and error handling
Infrastructure
- Docker Compose for orchestrating multi-container deployment
- Health checks and automatic restarts for reliability
- Volume mounts for persistent storage of uploads and generated content
- CORS configuration for secure frontend-backend communication
Challenges we ran into
- Google Cloud API Integration: Setting up proper authentication and configuration across Google Cloud services (Document AI, Vertex AI, TTS) required careful attention to service account permissions and API enablement.
- Text-to-Script Quality: Creating prompts that made Gemini sound like a podcast host instead of reading verbatim text was challenging. We iterated through many prompt engineering techniques to achieve conversational, natural-sounding narratives.
- Audio Generation Limits: Google's TTS API has a 5000-character limit per request, so we had to implement intelligent text truncation and SSML formatting to work within these constraints.
- PDF Complexity: Handling various PDF formats, from simple text documents to scanned/image-based files required implementing both simple PyPDF2 extraction and fallback to Document AI's OCR capabilities.
- Rate Limiting and Performance: Balancing API call efficiency with user experience, implementing proper caching, and managing file cleanup to prevent storage bloat.
Accomplishments that we're proud of
- Seamless Integration: Successfully integrated three major Google Cloud AI services into a cohesive workflow
- Accessibility Impact: A tool that benefits auditory learners, students with dyslexia, or anyone studying on the go
- Full-Stack Implementation: Built a complete end-to-end solution from PDF upload to audio download in under 24 hours
- User Experience: Designed an intuitive interface that makes complex AI technology accessible to anyone
What we learned
- Google Cloud AI Ecosystem: Gained deep understanding of the Google Cloud AI ecosystem and its constraints
- Prompt Engineering: Learned to craft prompts that guide LLMs to generate content in specific styles and formats
- API Design: Improved our skills in designing RESTful APIs that handle file uploads, long-running processes, and error handling gracefully
- Container Orchestration: Gained practical experience with Docker and Docker Compose for multi-service applications
- SSML (Speech Synthesis Markup Language): Learned to use SSML tags to add natural rhythm and pauses to generated speech
- Async Processing: Implemented background tasks and proper cleanup mechanisms for handling resource-intensive operations
What's next for Athena
- Multi-language Support: Expand to support documents and audio generation in multiple languages
- Advanced Audio Features: Add background music, multiple speakers for dialogue, and sound effects
- Batch Processing: Allows users to upload multiple PDFs and generate a podcast series
- Mobile App: Develop native mobile platform for iOS and Android
- Collaborative Features: Allows users to share podcasts, create playlists, and collaborate on study materials
- Integration with Learning Platfomrs: Connect with Google Classroom, Canvas, and other educational platforms
- Custom Voice Training: Allow users to train custom voice models for personalized narration
Built With
- chrome-devtools
- cloud-text-to-speech
- cors-middleware
- docker
- document-ai
- fastapi
- github
- javascript
- next.js
- postman
- pydantic
- pypdf2
- python
- react
- tailwind
- typescript
- vertex-ai
- vscode


Log in or sign up for Devpost to join the conversation.