-
-
-
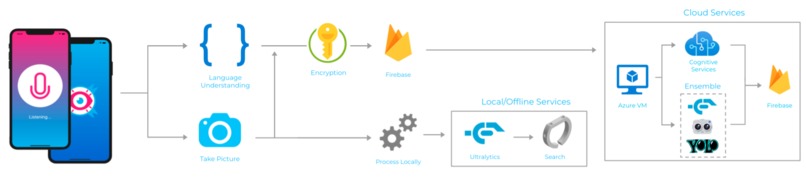
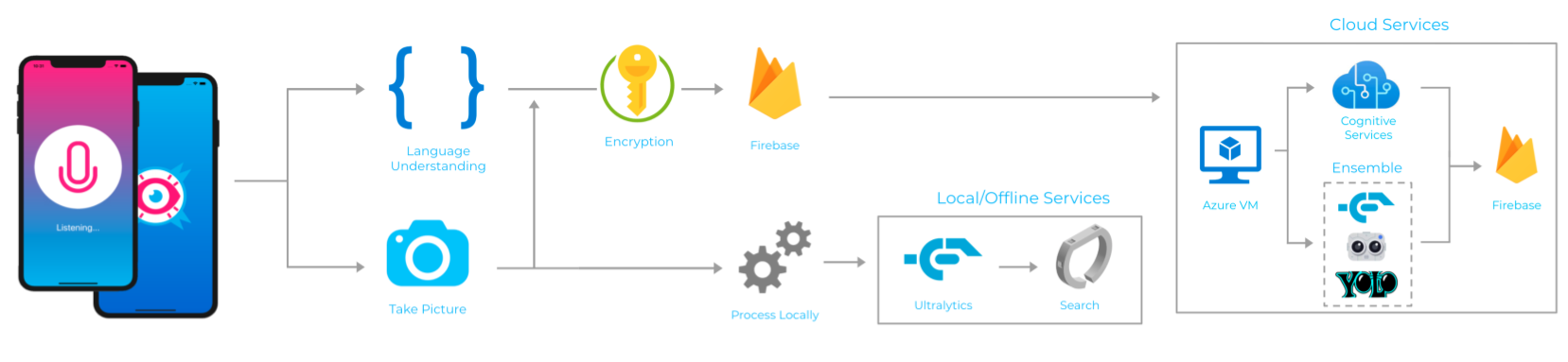
Full system diagram with online Azure Services along with offline services.
-

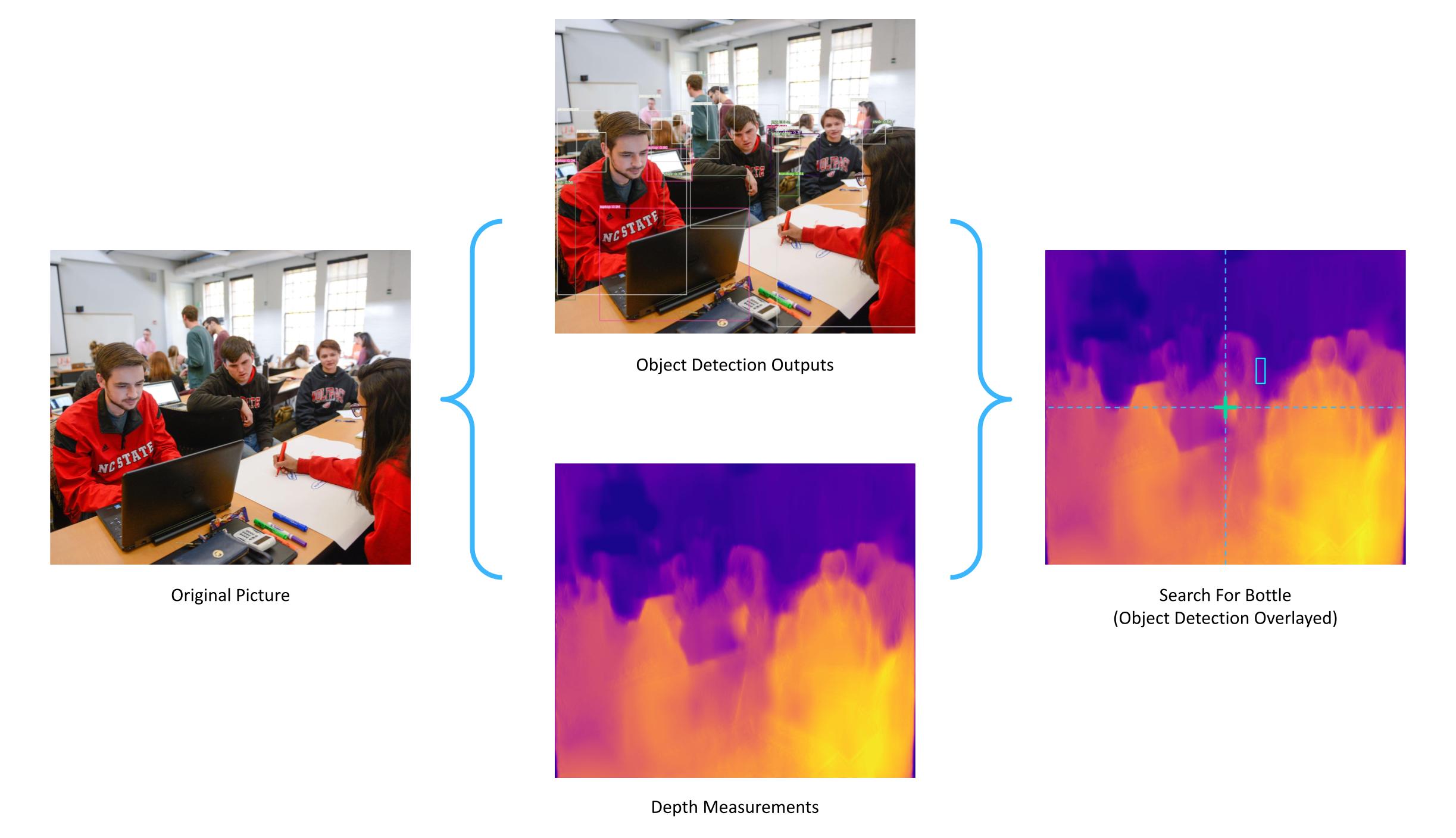
Diagram of how search mode works. We overlay object detection with depth data to avoid obstacles and generate a path to a specific object.
-

The phone is attached to a belt through a custom phone case.
-

Working on assembling the prototype
-

Prototype assembled and worn around wrist
-

Bracelet prototype with all the LEDs on (LEDs were used in place of motors for video)




Inspiration
Our project began when our teammate, Pranav, was looking for assistive technologies for his blind cousin. He noticed that many products on the market, especially devices using computer vision, were extremely expensive. Inspired, we began to research the limitations of current visual technologies. To understand the problem in its entirety, we then interviewed dozens of members of the visually impaired community. We were particularly inspired by Julie’s story. Julie, who later became one of our co-designer, was almost completely blind at a young age. But despite her disabilities, she became a professional dancer and trapeze artist. But Julie had a pressing concern. According to the Bureau of Crime Statistics (BJS), crimes against those with visual impairments were almost three times as common compared to crimes against those without them. Julie explained that due to her lack of spatial awareness, she was seen as an easy target. Julie, as well as the dozens of people we interviewed, needed a versatile visual aide suited for an active lifestyle and that would, most importantly, keep them safe.
What it does
Our design is Atheia, a bracelet and mobile app that uses state-of-the-art computer vision to make intelligent observations about the user’s surroundings. The device is geared towards the visually impaired, from those with moderate vision loss to people who are completely blind. Using Atheia is as simple as pressing a button on a headphone wire or tapping the large button on the phone screen, giving a voice command, and then listening to the response. Atheia is considered to be “all-in-one” because it combines features (text detection, object detection, object searching, and last-seen) that are either found in stand-alone visual aids or are features unique to our device, such as search and recording where and when the user last saw an object (last-seen). There are also two ways of using Atheia, a standalone app, and a wearable bracelet paired with the app. Both methods can support the same features, although the wearable can provide constant detection and is useful for active utilization. Currently, we have 6 main features: scan, text, search, last seen, sentry-mode, smart question:
The Scan feature will simply relay what the user’s surroundings are, along with the quantity of each object. For example, “1 table, 1 laptop, and 3 cups detected.” The scan feature will also contain a feature that relays to the user where each object is relative to the user. The outputs from this feature will then be stored in a Firebase database for user privacy and application workflow simplicity. The Text feature reads out any text in the picture. It first says the surface the text was detected, such as a sign or a book, then the actual writing. For example, “The sign says, “No parking”. Furthermore, the text feature can be used to read handwriting and document files thoroughly. The text feature also contains a barcode and product lookup feature, in which items can be scanned and read to the user during a shopping trip. Using a similar approach as ensemble learning, we synthesize the outputs from all the cloud services and models into a highly accurate text recognition service that can also be run offline. The Search feature guides users towards the desired objects which they choose through the audio input. Each detected object is accompanied by an x and y degree separation in relation to where the picture was taken. The x and y degree separation is calculated by utilizing the scaled output as a function of the camera’s horizontal and vertical view angles. The depth of the object is computed through stereo vision algorithms through the stereo vision/LIDAR capabilities of the mobile phone. Wearable Design: Using the angular separation of the center of the bounding boxes with the center of a user’s field of vision, we can determine how the user should move to get to their target on the bracelet. To do this effectively, we will use an IMU (Inertial Measurement Unit) with a built-in 3-axis gyroscope, accelerometer, and magnetometer. Using these outputs, we can determine how far the user needs to move left, right, up, and down, and we express the degree of distance with the intensity of the motors, meaning that as the separation increases the motor vibrates with an increasing intensity which is controlled by PWM from the microcontroller. We will utilize this vibrational intensity to guide the user in all directions. Mobile Application: Designated as an alternative for active wear, the app provides an additional form factor suited for indoor and minimal active use. The implementation of the back-end workflows was modified to fit the application’s functionalities. For example, in the wearable bracelet, vibration motors are used to guide a user toward an object in the respective environment. For the search feature, we will utilize audio panning and intensity to guide the user left and right, as well as towards the object. To allow the user to move up and down, we will increase the sharpness and intensity of the vibrations to move vertically up, and decrease sharpness and intensity to guide the user to move down. The Last Seen function asks the user for an object and then returns the time, place, and location the object was last seen. The detected objects for every picture will be stored in the Firebase database, along with the time taken and the location of the object. Using a search algorithm, the app will be able to detect the latest log containing their object and references the location to the user. For example, an output would state, “Computer last seen next to 1 Keyboard, 1 bottle, 1 key, and 1 television at 11:35 PM January 21st.” Another highly requested feature is accessibility formats. These formats would include product scanning during shopping and a Global Positioning System (GPS) functionality to guide users in public settings. For example, the GPS feature would work with both the application and bracelet to tell the user where to turn and avoid obstacles in their path when walking from destinations. The Smart Question feature takes questions that look for the detail in the image. For example, “Is there a car in front of the building?” or “What is the value of the coin on top of the paper?”. We will utilize Pythia from Facebook to answer user-requested questions in their environment To ensure user safety and independence we included a facial recognition feature that reproduces the name of users that they have seen before and logged by themselves. If a user wants a face to be stored for querying they can say, “Remember Steven,” and later, “Who is this?” One of our most requested co-designer features includes a safe mode. With “take video” or “take photo,” a user can continuously record video for playback in suspicious situations or to use as evidence for a particular incident. We are actively designing a feature for live video streaming when Wi-Fi is enabled and a “beacon” setting that alerts pre-determined contacts. With all of our services, we included Azure’s translation service, which helps us cater to a global market and wide network of individuals with visual impairments.
How we built it
For scalability and commercial viability of our device, we decided to host our backend on Azure Virtual Machines. With its expandable storage and variety of SSD settings, we were able to use the Azure VM’s security to ensure requests from the glove were met. In addition to Azure’s Virtual machine, we were able to take advantage of Azure’s SDK for Python to make this process simpler. Using Azure Computer Vision endpoints and services, we were able to use Azure’s advanced model in an ensemble with the YOLO and MaskRCNN models. After the Azure instance received the image from the Raspberry Pi, we were able to make an inference on both of the endpoints previously generated in the process and created a JSON consisting of the objects’ name, respective accuracy, and location in the image. As you can expect running 5 different algorithms simultaneously and then filtering through every single output will yield very accurate results. Our next problem was finding a way to effectively communicate the detected objects to the user. People without visual disabilities can easily see the objects around them, where they’re located, and how they are interacting with each other. However, this is very difficult to describe in a concise manner and can get very convoluted very quickly if there are a lot of objects with several different interactions. We realized that the simplest and most concise way to relay this information would be to just say what objects were detected along with their frequency. With this solved, we moved on to our next major hurdle, detecting text. There are several technologies that are already capable of detecting text in a fast and accurate manner. For our text feature in the device, we used Azure’s AI service: ReadAPI. After creating an endpoint client with the service, we were able to use the text extraction from images feature, to parse and read all the text from the image in the same way it appeared in the image. In addition, users could also read documents and recognize brands with the rest of Azure’s cognitive services. The problem with text detecting solutions is that they don’t distinguish where that text was detected, but rather just arbitrarily output whatever text was detected, no matter how subtle or out of place. Azure’s API was no exception to this so we started to develop an algorithm that could filter through irrelevant text detections. We continued to develop this algorithm until we discovered a tool developed by Facebook Research called Pythia. Pythia is a deep learning framework that supports vision and language processing with the ability to effectively answer questions about an image’s detail. By using PyTorch, Pythia gets to be very modular and flexible, taking advantage of multiple tools, references, models, datasets, etc. This allows Pythia to effectively answer questions about an image’s detail. For example, say that someone gives you money of varying bills. For people with visual disabilities, it is very difficult to distinguish dollar bills without being dependent on someone or something. If you take a picture and ask, “what is the value of the dollar ”, it will return a high confidence value of the right amount. If all its outputs are of low confidence, then we simply return, “I don’t know the answer to that”. In addition, we were able to capture the essence of a user’s environment by utilizing Azure’s description cognitive service.
Challenges we ran into
Some of the challenges that we ran into relate to the configurations of using CUDA and Pythia together. For example, the local development server that we were using had to utilize GNU-9 toolchains, and as a result we ran into multiple issues with using Facebook models, such as Pythia and Detectron2, in our feature set. To solve this issue, we had to manually create a local install of the GNU-7 compilers and reformat the CUDA configurations to work with the compilers and models. On the Azure side, we struggled with finding an accurate way to detect objects in a variety of classes. Since Azure’s object detection is fast, but limited, we turned to utilizing an ensemble of YoloV5, YoloV4, and Detectron2 for increased accuracy and decreased latency with multi-threaded runtimes. Additionally, we were able to include an offline version by utilizing Apple’s Neural Engine through the Vision framework and YoloV5 compiled locally on CoreML (proprietary by Ultralytics and not to be included in our repo according to our partnership with them).
Accomplishments that we're proud of
We are especially proud of integrating the entire system on the cloud, local device, bracelet and database together. Usually, integrating diverse sub-systems is especially difficult, but by dividing up the work amongst team members, integration was not an issue.
What we learned and What's next for Atheia
We learned that through Azure, we can create an even more robust and scalable platform for our device. Through Azure real-time functions, we can support multiple requests at one time, and even prevent DDOS attacks by throttling the function itself. We also learned how to integrate Azure functionality in such a big project, and found out how easy it is to develop cloud applications with Azure. Thanks to Azure, we were able to build a scalable and real-time system for one of our most resilient communities: the visually impaired. Furthermore, as we talk to more co-designers and gain additional partners, we will be able to spread more awareness about our device and tailor the device to a wide range of use-cases. As we gain more press and recognition we hope to create a system that is for co-designers, by co-designers.

Log in or sign up for Devpost to join the conversation.