-
-
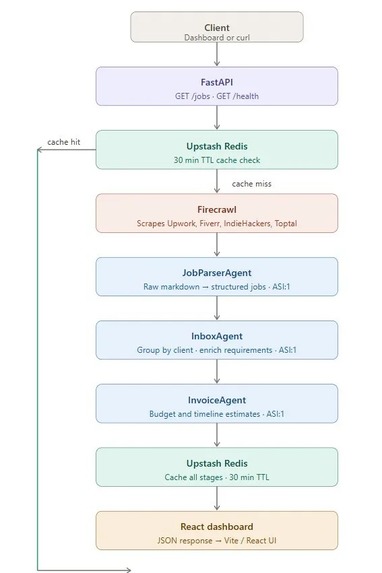
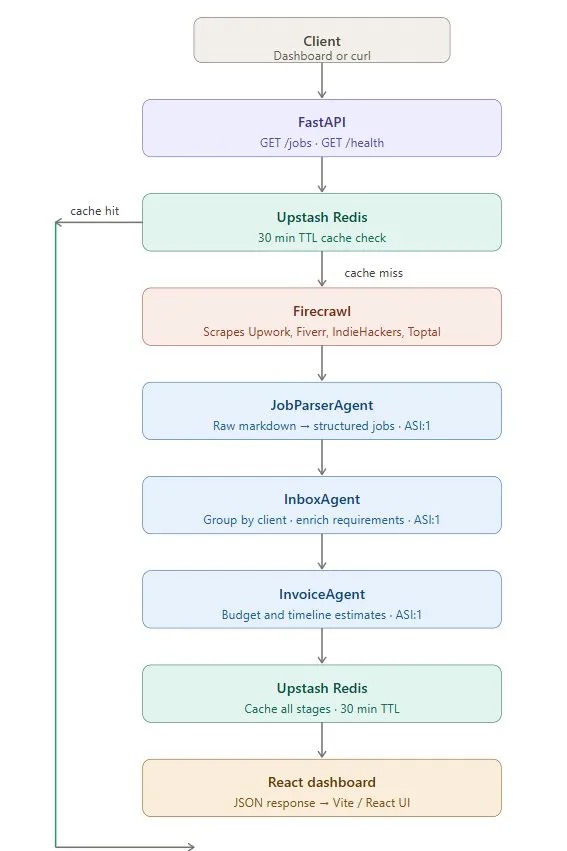
High level Architecture
Inspiration
Problem
- Freelancers spend hours finding work, not doing work
- Job discovery is manual, repetitive, and fragmented across platforms
- Context switching (Upwork, Fiverr, etc.) creates high cognitive overhead
- Key info (client quality, budget fit, scope) is hard to extract quickly
- Existing workflows (Notion, spreadsheets) are hard to maintain and break easily
Solution
Asyntra solves this by:
- Automatically scraping freelance job platforms
- Classifying and structuring listings using AI
- Profiling clients + extracting key signals instantly
- Generating budget & timeline estimates
- Delivering everything in a single unified dashboard
Core Idea
Turn freelance job discovery into an automated data pipeline: Scrape → Classify → Estimate So freelancers can focus on high-value work instead of hunting for it.
What it does
Asyntra eliminates the manual overhead of freelance lead discovery by automating the entire process from scraping to invoicing in a single pipeline. When a request comes in, the system first checks Upstash Redis for cached results. If a recent run exists, results are returned instantly. On a cache miss, the full pipeline fires: Firecrawl scrapes the platforms, and three AI agents process and enrich the data. The final output is then cached and served to the React dashboard. The fully researched leads are displayed in seconds.
What we built
- A FastAPI backend with two endpoints -
GET /jobsto trigger the pipeline andGET /healthfor live status monitoring. - A Redis caching layer using Upstash that stores all three stages of pipeline output for 30 minutes, serving repeat requests instantly.
- A Firecrawl integration that performs scraping simultaneously across various platforms.
- Three specialized AI agents powered by ASI:1 - a JobParserAgent, InboxAgent and InvoiceAgent - each owning exactly one stage of the pipeline.
- A React + Vite frontend styled with Tailwind CSS, featuring a live backend health indicator, pipeline status display, collapsible project cards, and a full budget summary panel.
How we built it
We approached Asyntra as a multi-agent pipeline problem from day one. Rather than building one monolithic service, we decomposed the work into three specialized agents- each responsible for exactly one transformation of the data. This made every stage independently testable and easy to debug.
For the backend, we chose FastAPI for its speed and automatic API documentation, paired with Uvicorn as the ASGI server. Rate limiting was handled with SlowAPI to protect against abuse.
For AI processing, we integrated ASI:1, Fetch.ai's large language model, through a shared ASIClient base class that all three agents inherit from. Each agent loads its own prompt file, keeping the logic and instructions cleanly separated.
For scraping, we used Firecrawl, which handles JavaScript-rendered pages and anti-bot challenges better than raw HTTP requests. Each platform URL is defined in config and scraped in sequence.
For caching we chose Upstash Redis a serverless Redis provider to store pipeline results with a 30-minute TTL. This dramatically reduces latency on repeat requests and keeps API costs low by avoiding redundant scraping and LLM calls.
For the frontend, we used React + Vite + Tailwind CSS, with Axios handling all API communication through a single api.js file. The dashboard polls the /health endpoint on load and displays a live green/red status indicator alongside the pipeline results.
Challenges we ran into
Anti-bot protection on major platforms Upwork and Fiverr deploy aggressive bot-detection systems that repeatedly blocked our scraper. Getting consistent data out of JavaScript-heavy, session-protected pages required significant trial and error with Firecrawl's configuration. Some platforms returned a CAPTCHA instead of the entire content.
LLM response latency and timeouts Processing large markdown documents - sometimes 30KB+ - through ASI:1 caused frequent timeouts in early builds. We solved this by implementing exponential backoff retry logic, giving the model more time on large payloads without crashing the pipeline.
Unstructured and inconsistent job data No two job listings follow the same format. Budget information is buried in descriptions, requirements are nested or missing entirely, and some posts list multiple projects under one client. Our prompt engineering went through many iterations before the agents could handle this reliably without hallucinating missing fields.
Redis connection configuration
Upstash Redis requires a REST URL and a token that must be correctly set as environment variables. Early builds failed silently when these were missing, returning None rather than raising a clear error, which led to confusing downstream failures in the pipeline.
Accomplishments that we're proud of
- Successfully chaining three AI agents in a clean, fault-tolerant pipeline where each stage degrades gracefully on failure
- Building a caching architecture that makes the system feel instant on repeat use while keeping API costs minimal
- Designing a frontend that makes a complex multi-stage backend feel simple, one button, one result
- Getting structured, usable output from wildly inconsistent raw markdown scraped across four different platforms
- Completing a full working system using scraper, agents, cache, API, and dashboard as a cohesive product
What we learned
Agent decomposition is worth the upfront investment. Breaking the pipeline into three single-responsibility agents made debugging dramatically easier. When something broke, we knew exactly which agent to look at.
Graceful degradation is non-negotiable. Every agent has a fallback. When enrichment fails, the project still appears with raw data rather than disappearing entirely. A pipeline that fails silently is worse than one that serves incomplete data transparently.
Environment configuration is underrated. Most of our early bugs came from missing or misnamed environment variables. A clear .env template with explicit variable names would have saved hours.
Prompt engineering is iterative. Getting ASI:1 to reliably return clean JSON from messy markdown took far more prompt iterations than expected. Small changes in wording produced dramatically different output quality.
What's next for Asyntra
- Browser extension : one-click lead capture from any job page, feeding directly into the pipeline
- Proposal drafting : auto-generate tailored proposal emails from classified leads using ASI:1
- CRM layer : track lead status, follow-ups, and conversion rates directly in the dashboard
- Multi-user support : team dashboards with role-based access so agencies can collaborate on leads
- Webhook alerts : instant notifications when high-value leads matching custom criteria are detected
- Authenticated platform access : proper OAuth integrations with Upwork and Fiverr APIs to replace scraping with reliable data feeds

Log in or sign up for Devpost to join the conversation.