-
-
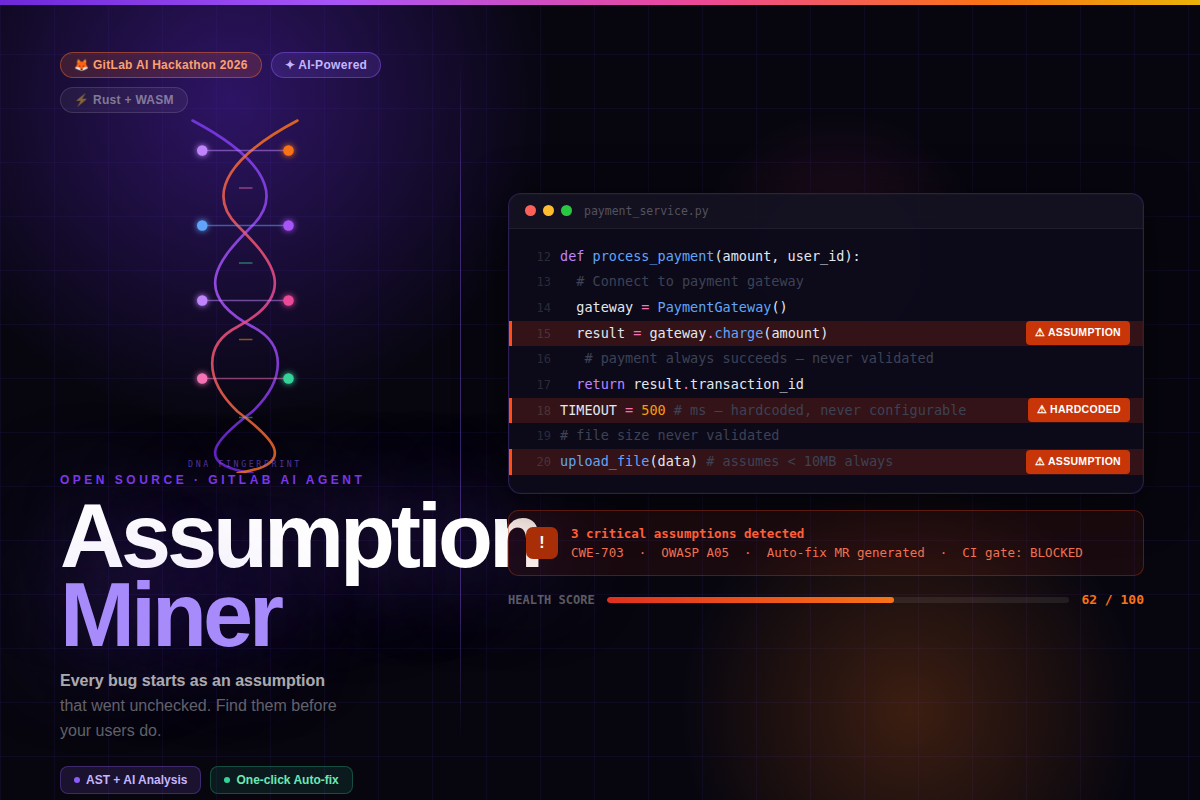
Assumption Miner (Banner)
-
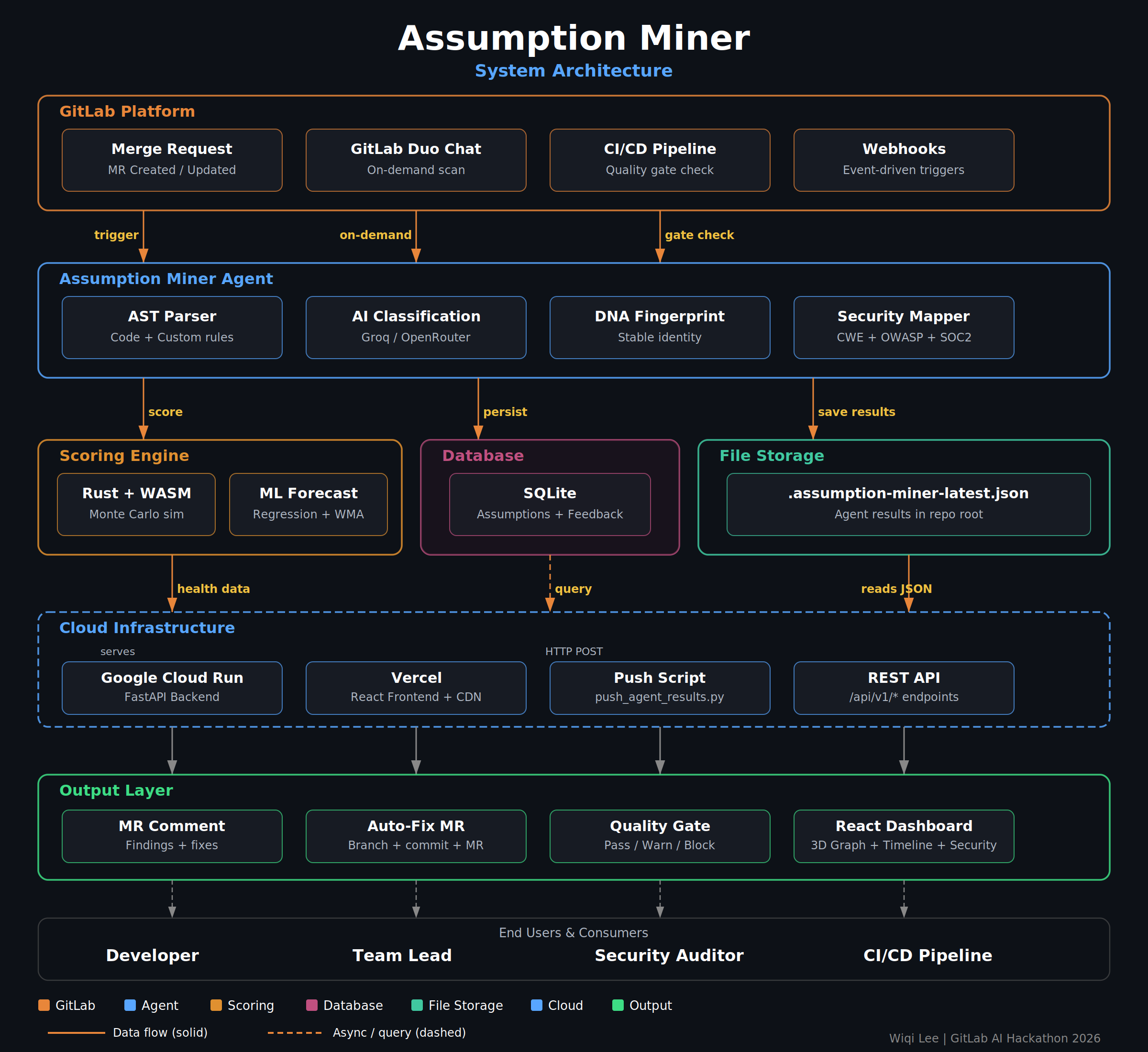
Assumption Miner system architecture
-
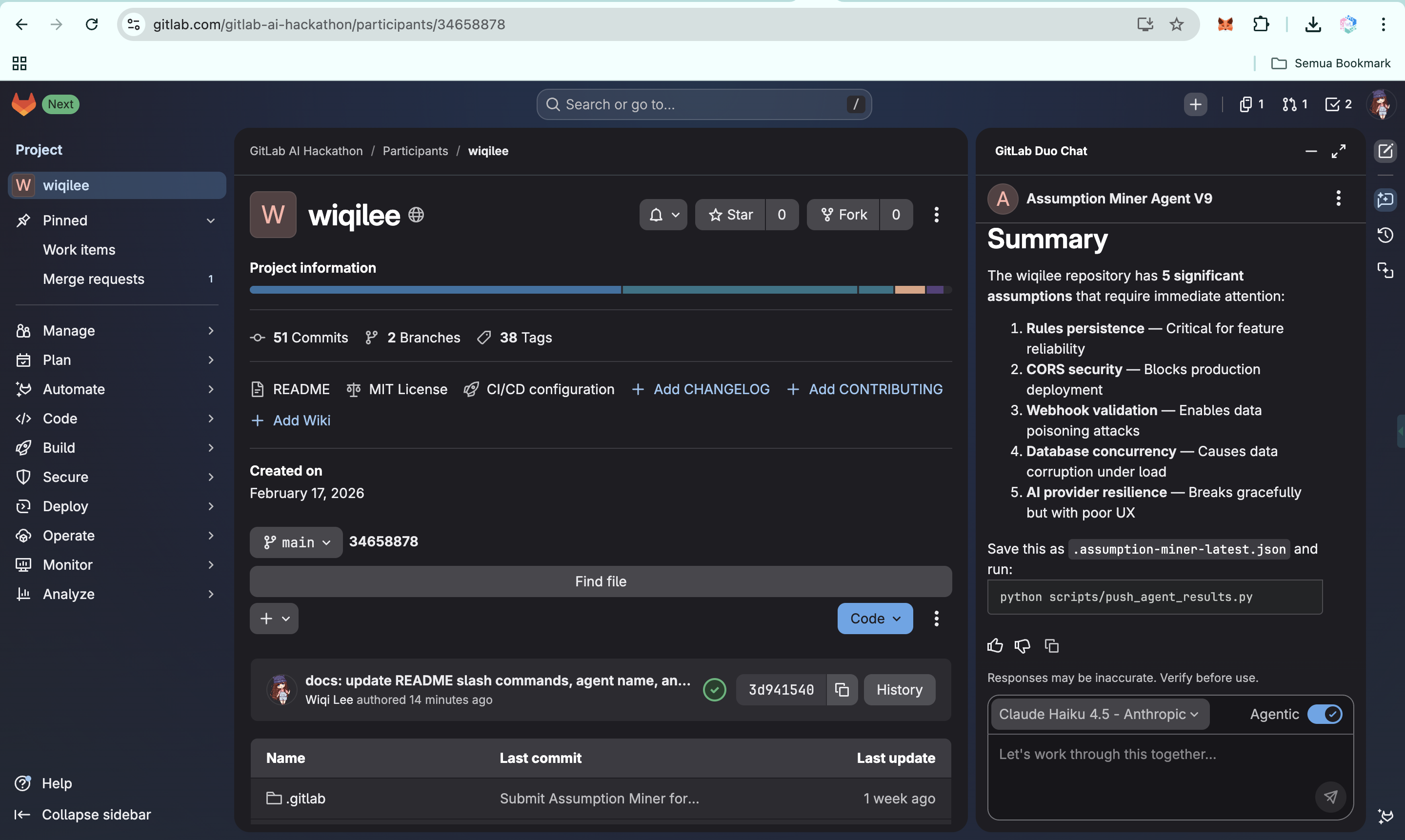
Assumption Miner project on GitLab AI Hackathon
-
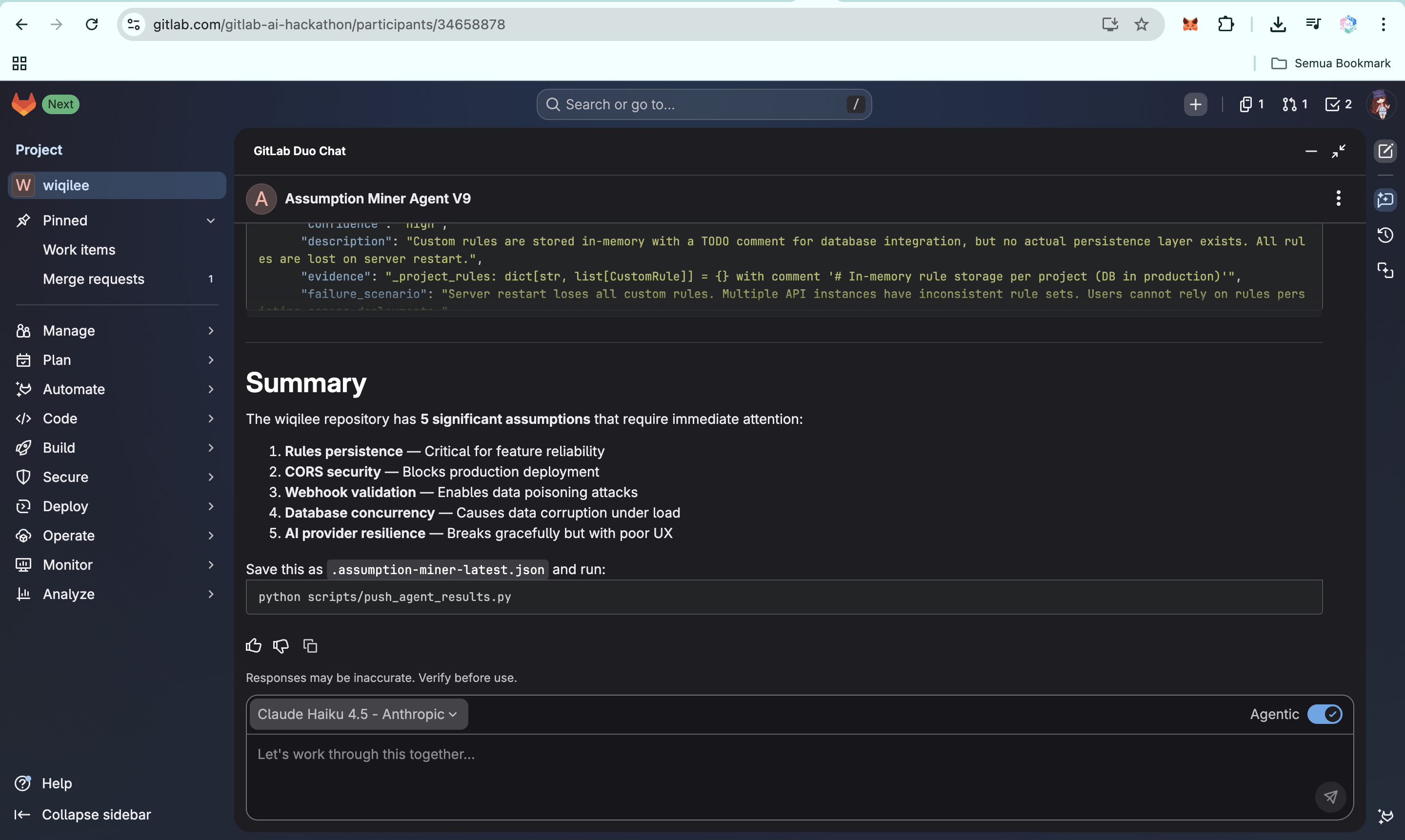
Assumption Miner AI Agent V9 generating actionable insights from your codebase
-
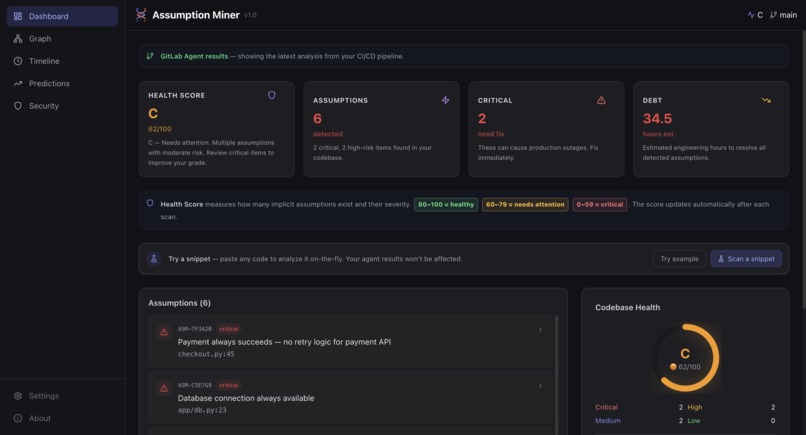
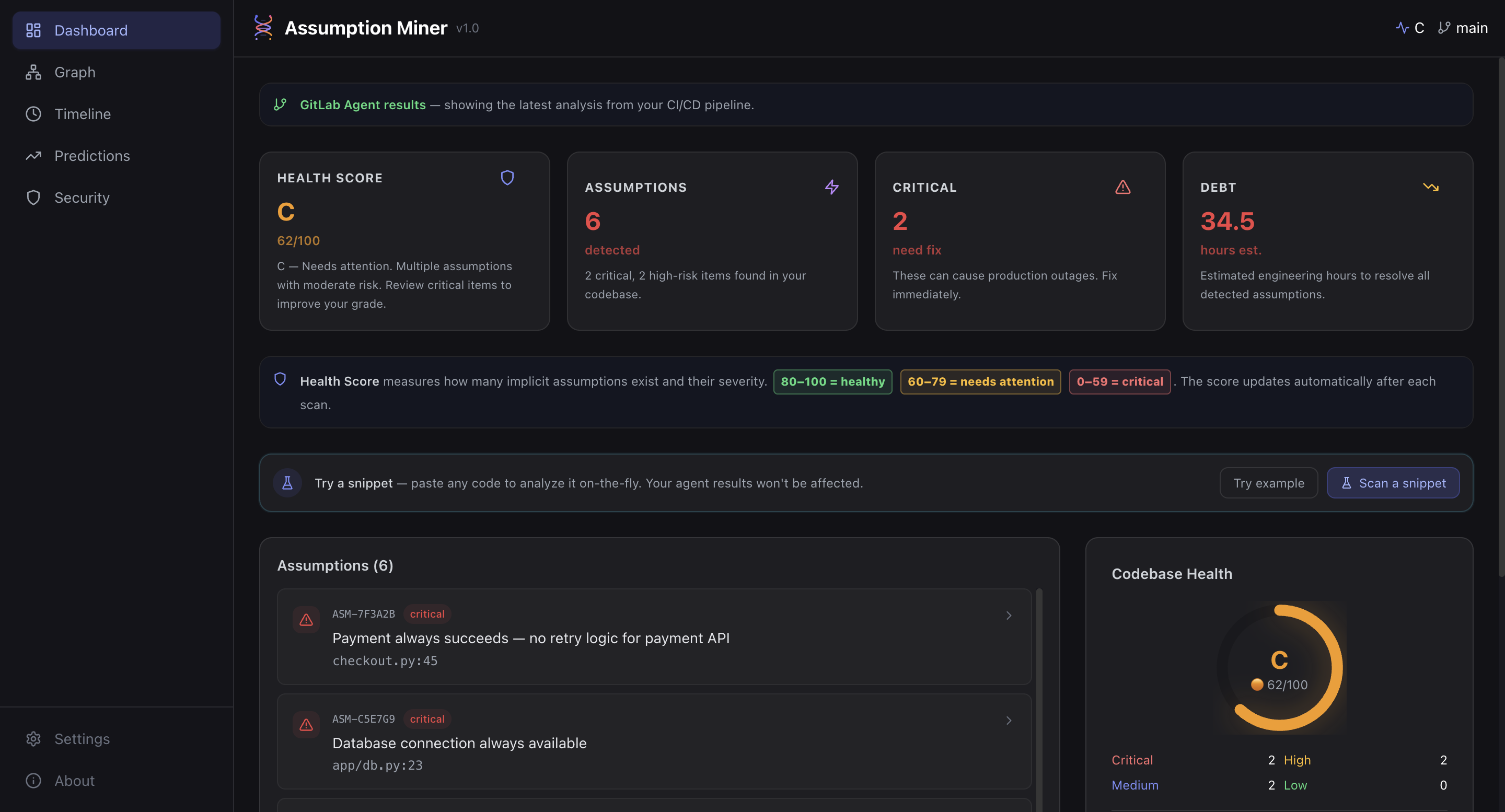
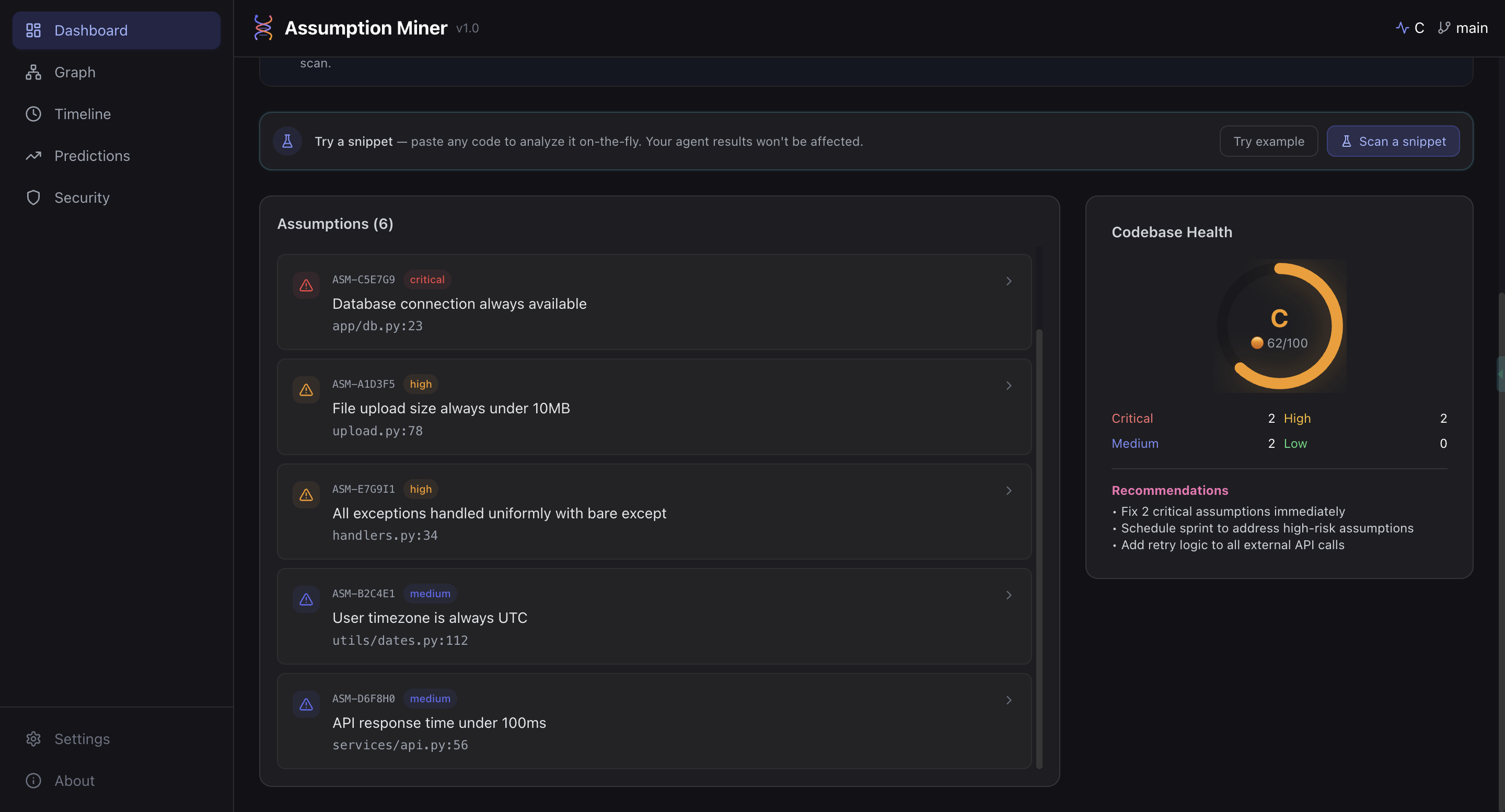
Dashboard: System Health Overview (UI)
-
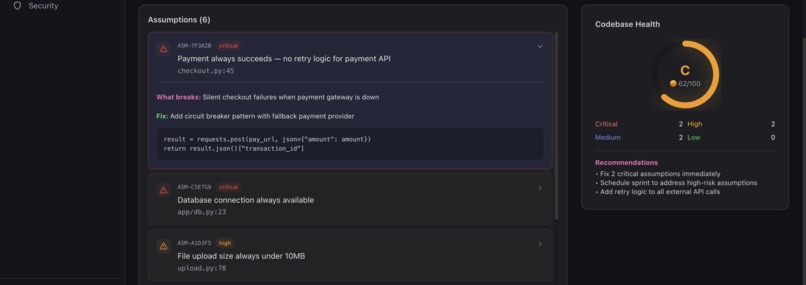
Dashboard: System Health Overview-2 (UI)
-
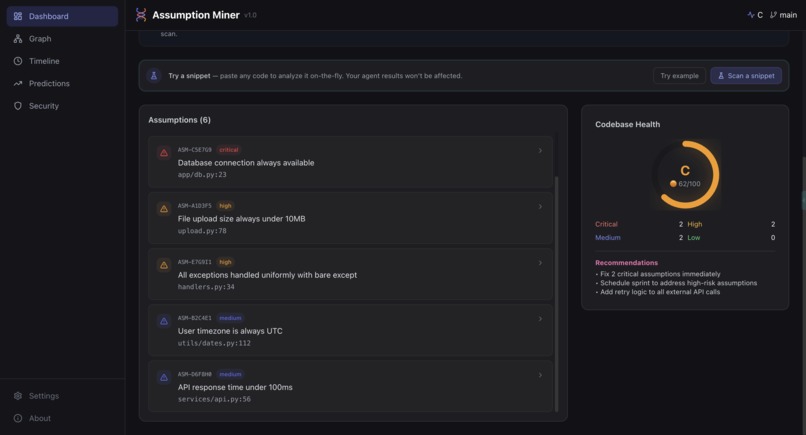
Dashboard: System Health Overview-3 (UI)
-
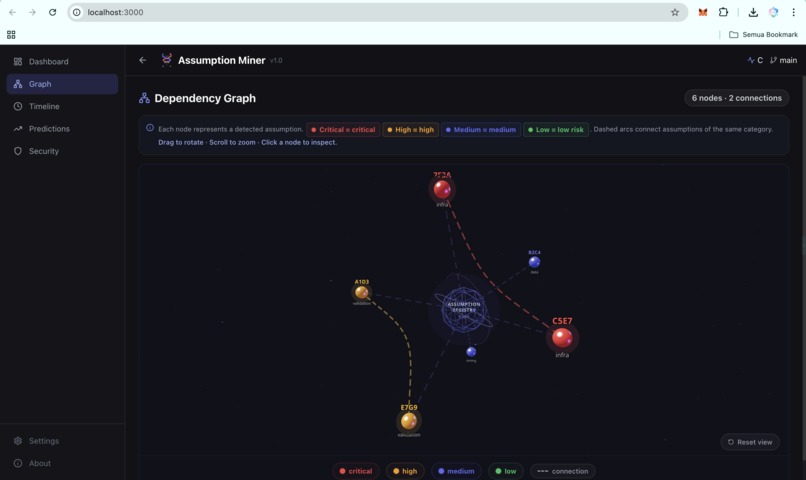
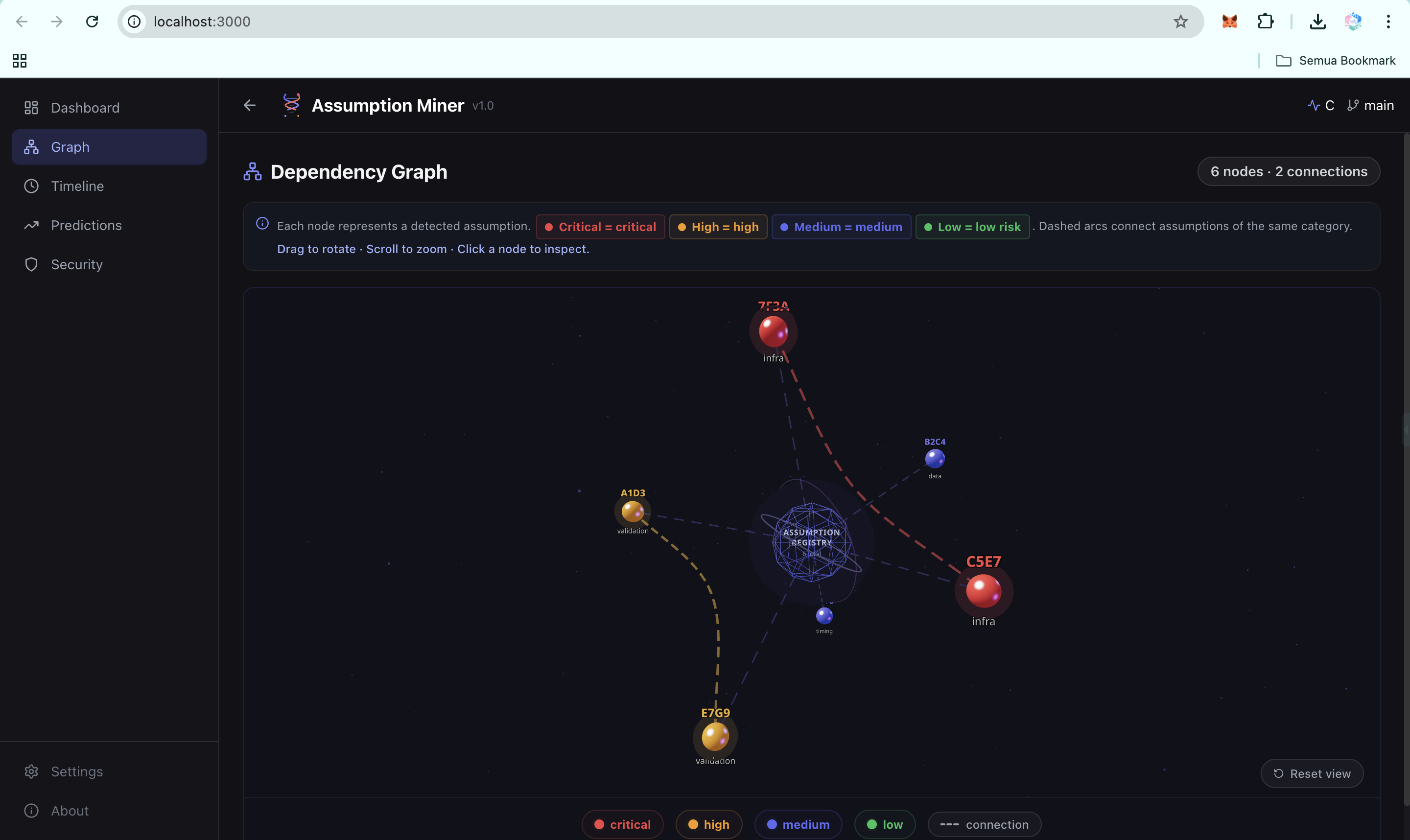
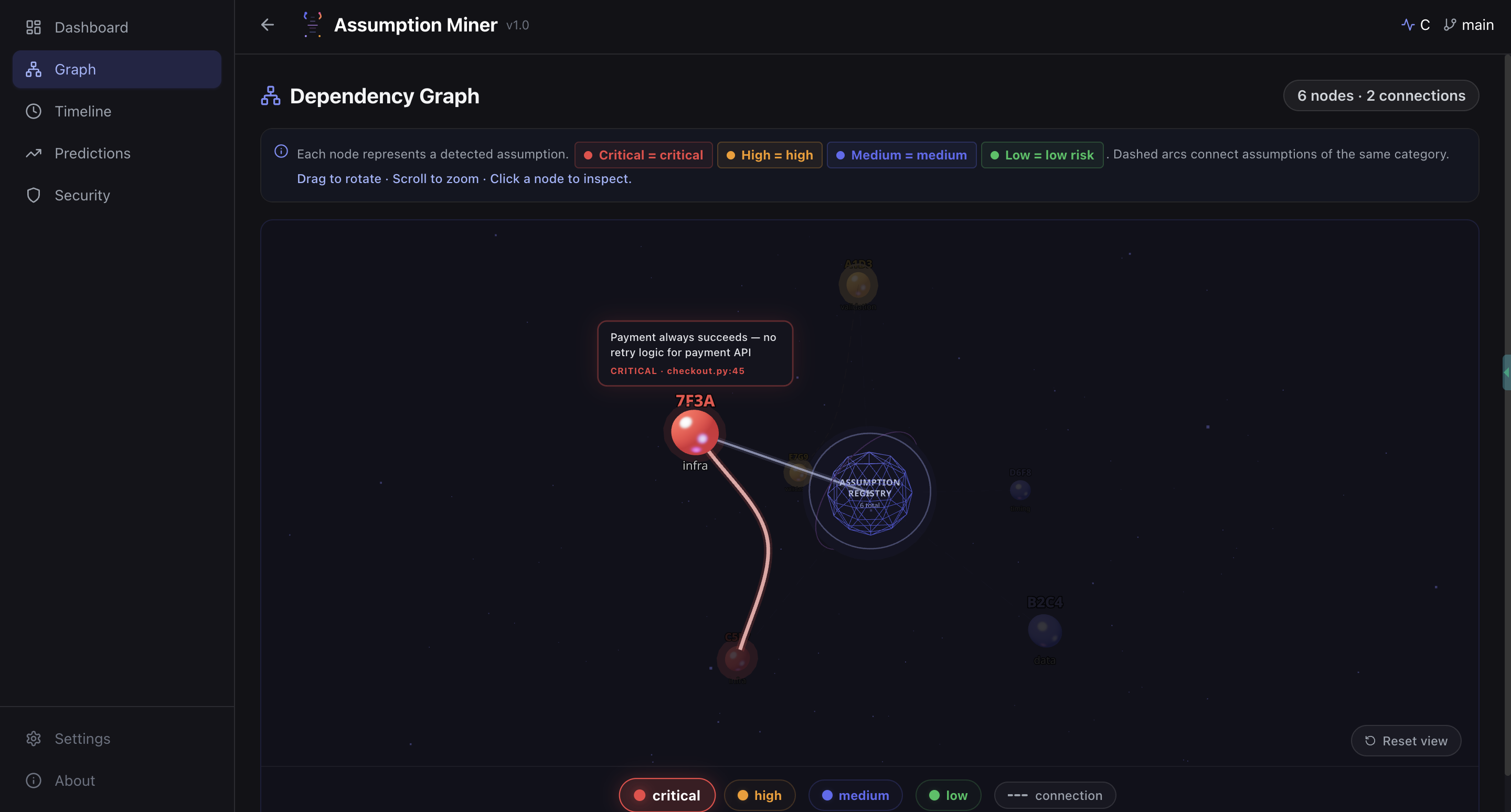
Dependency Graph: Hidden Assumption Relationships (UI)
-
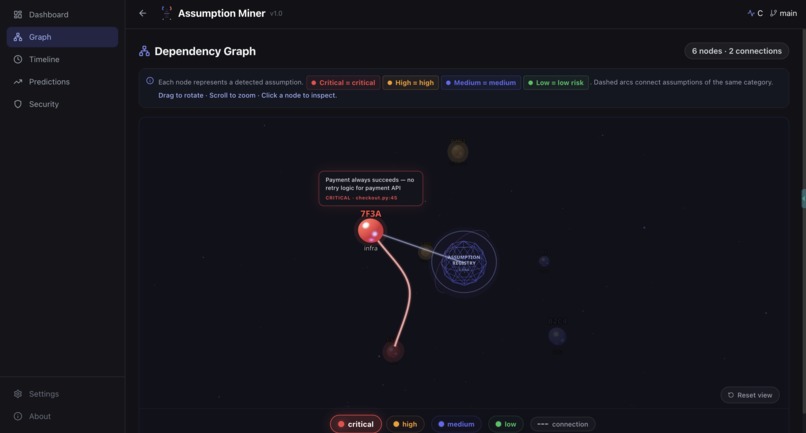
Dependency Graph: Hidden Assumption Relationships-2 (UI)
-
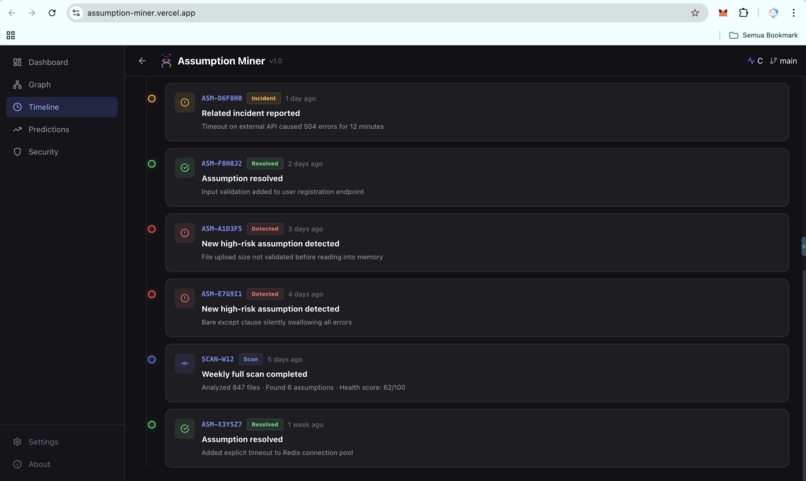
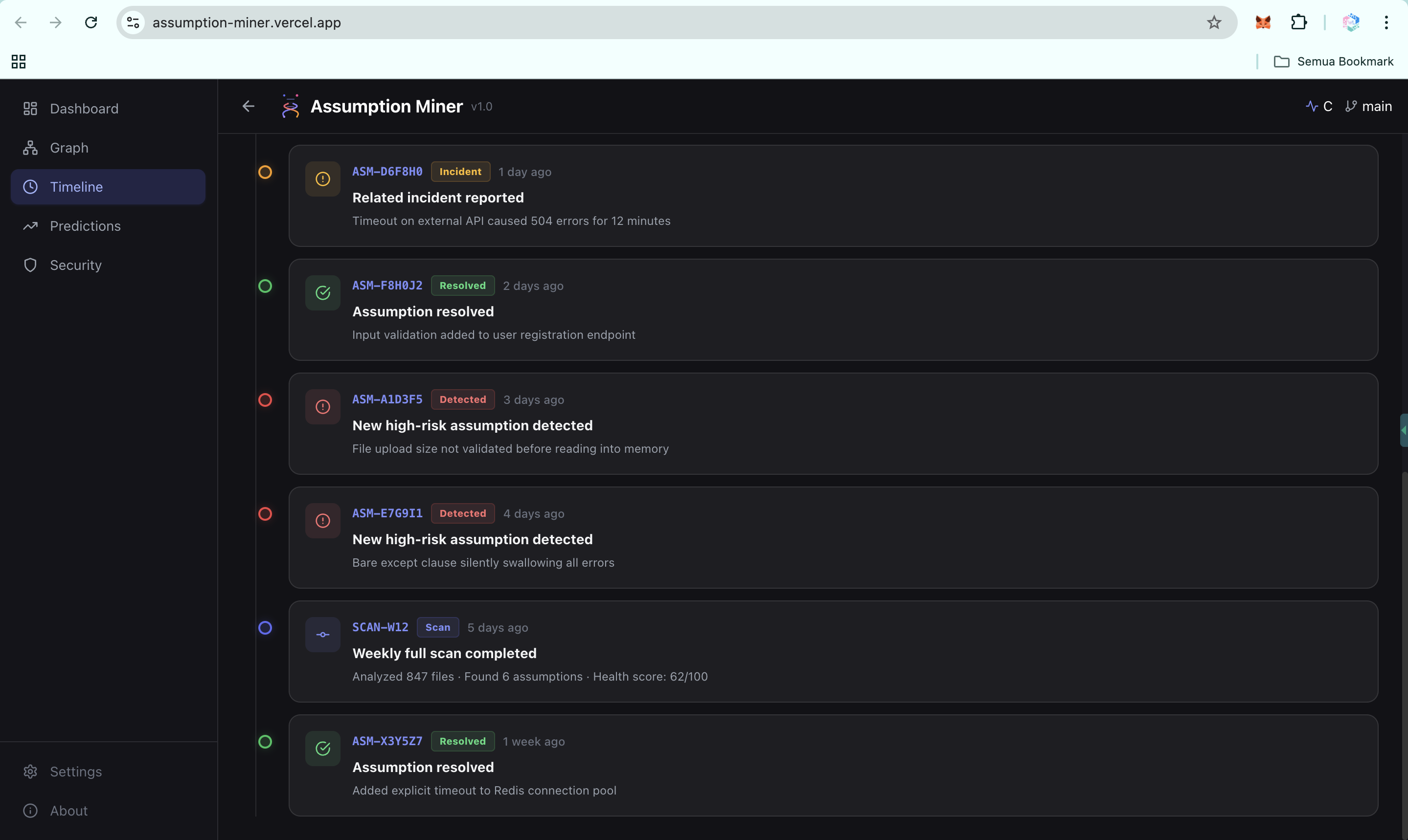
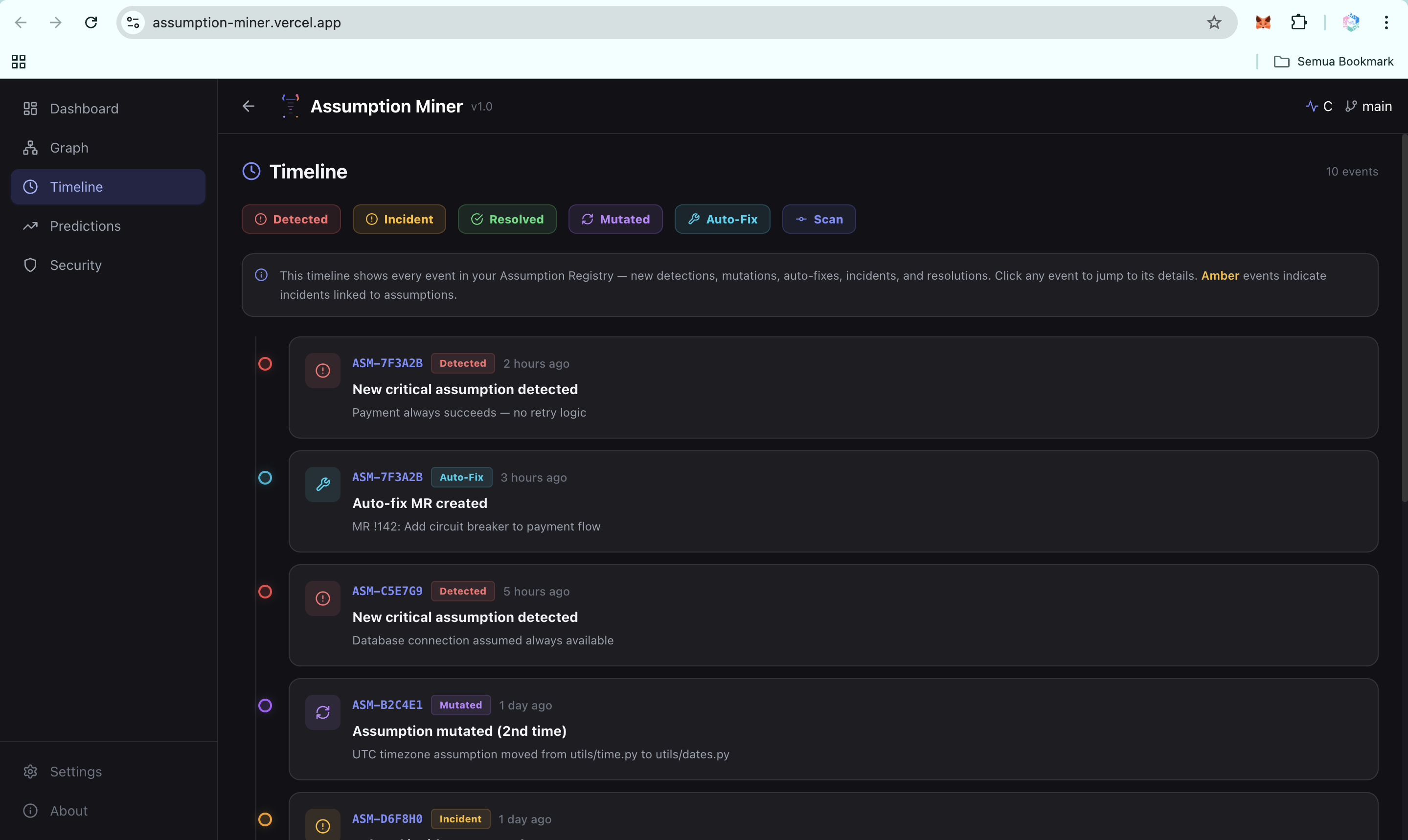
Timeline: Evolution of Risks Over Time-2 (UI)
-
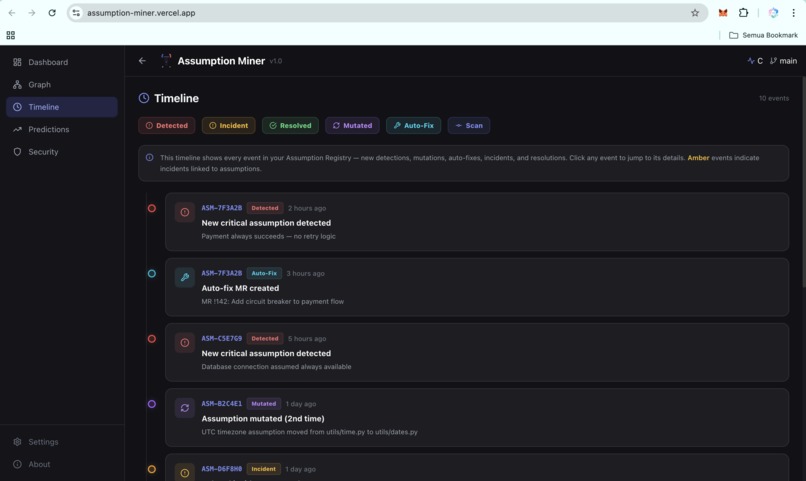
Timeline: Evolution of Risks Over Time (UI)
-
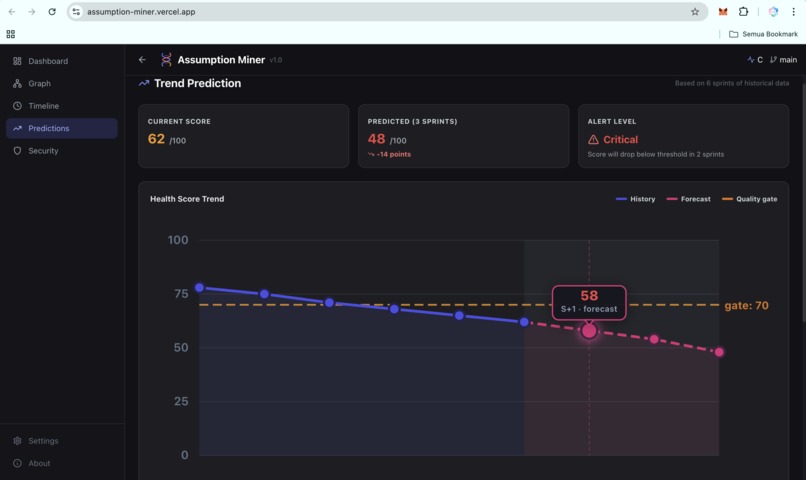
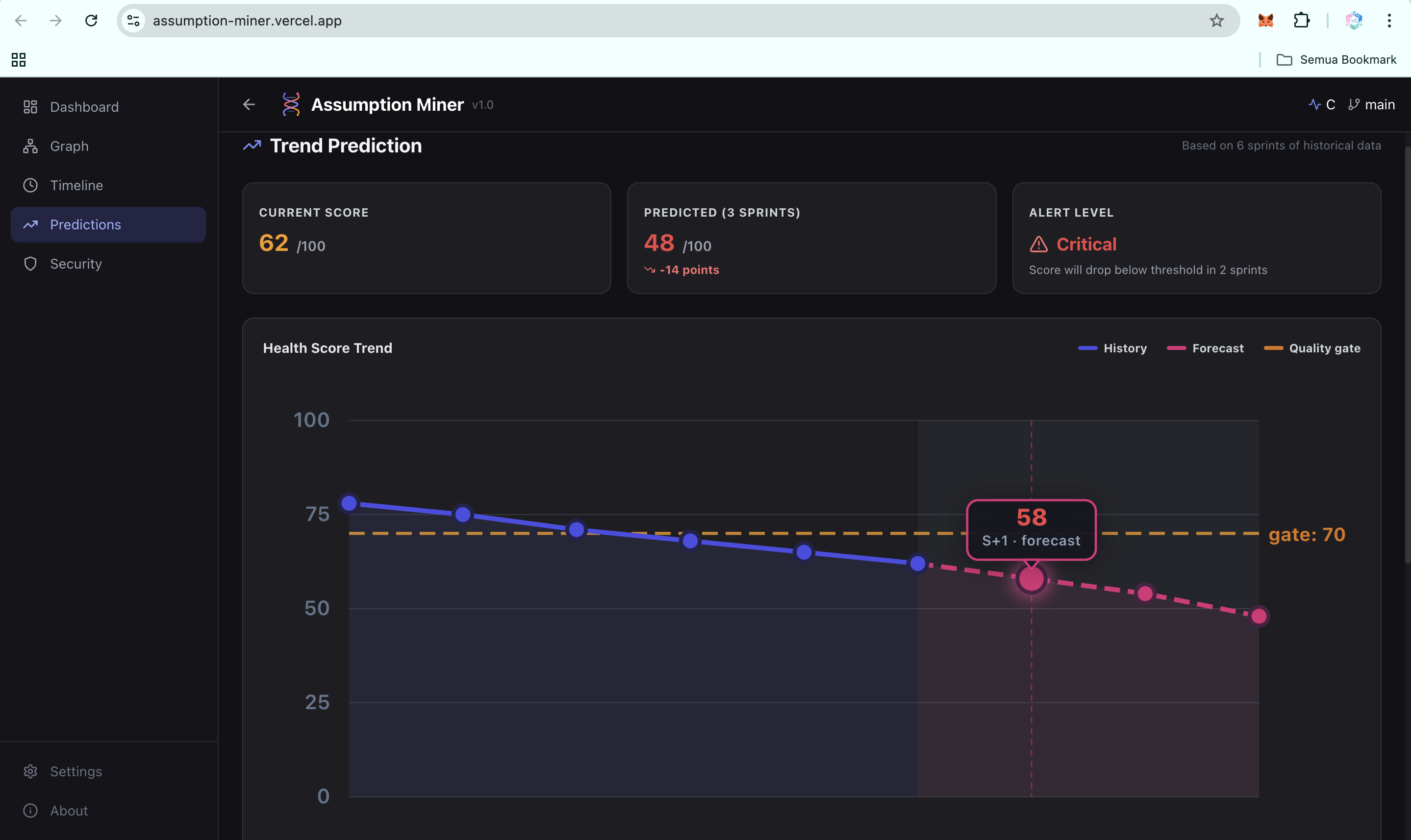
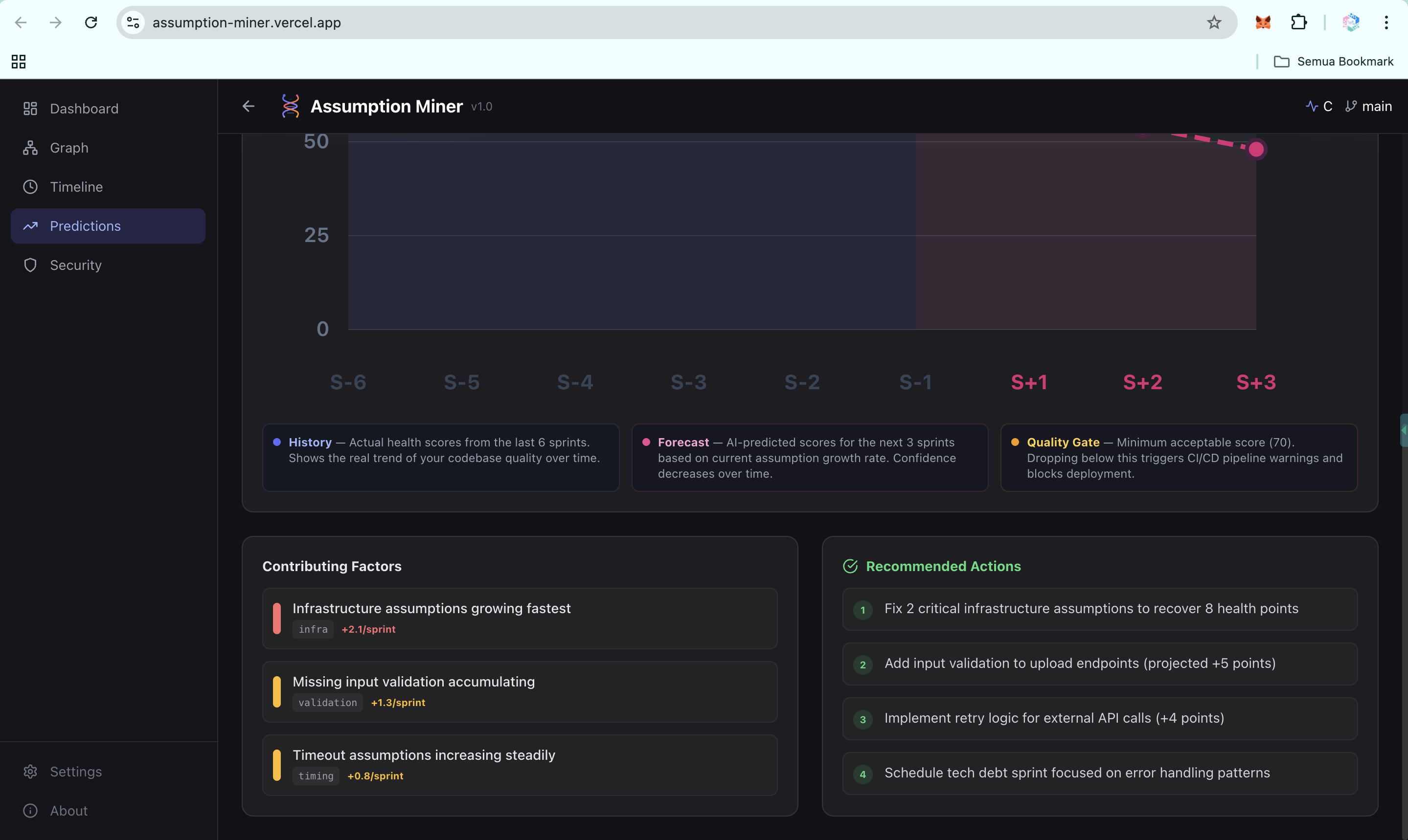
Predictions: Future Failure Signals (UI)
-
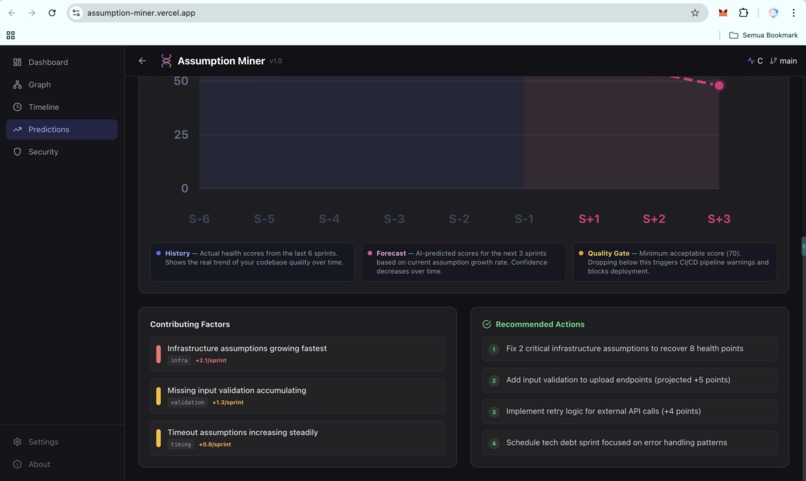
Predictions: Future Failure Signals-2 (UI)
-
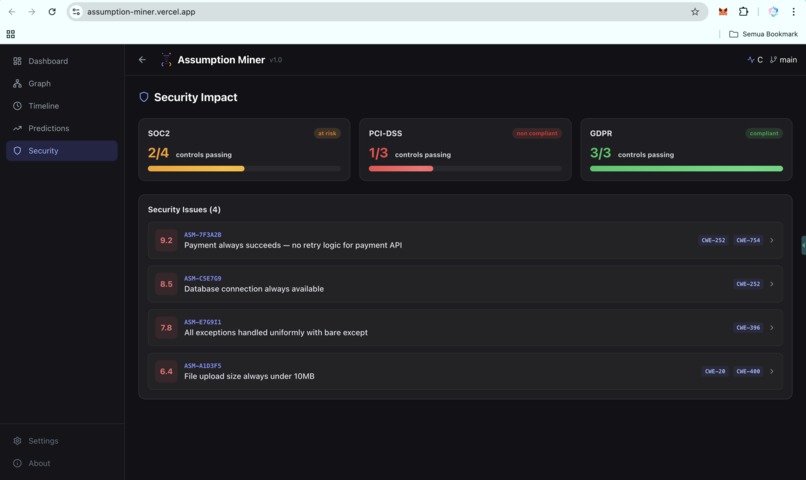
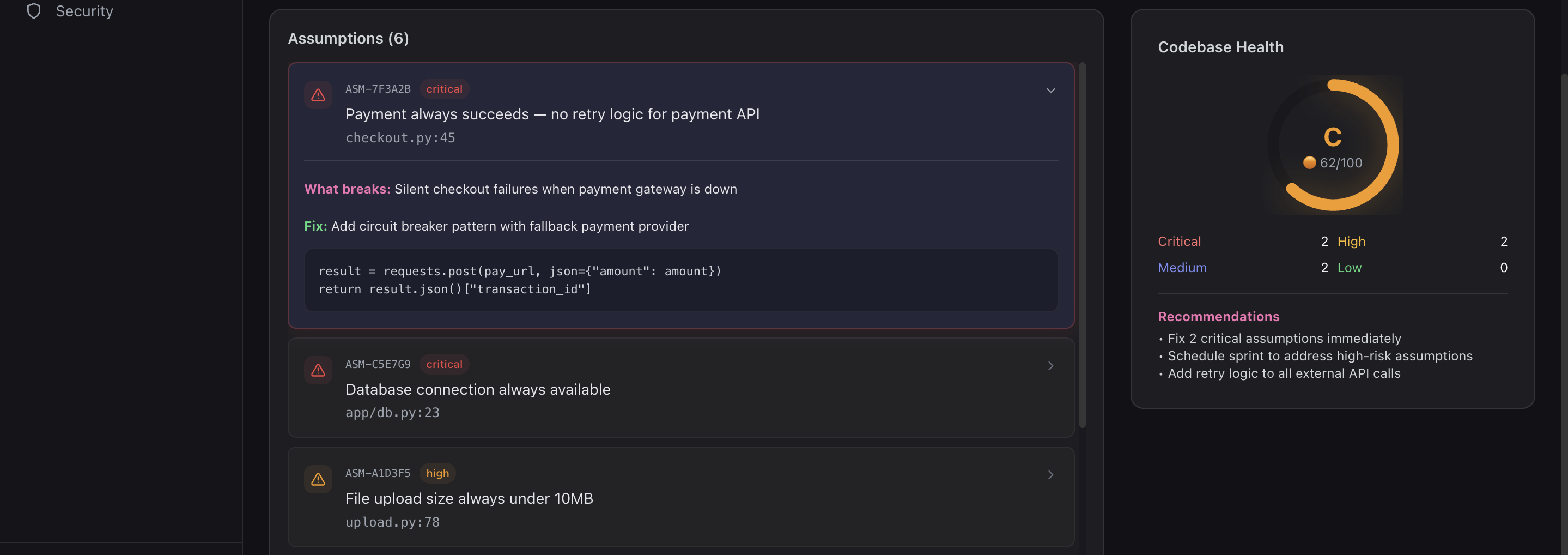
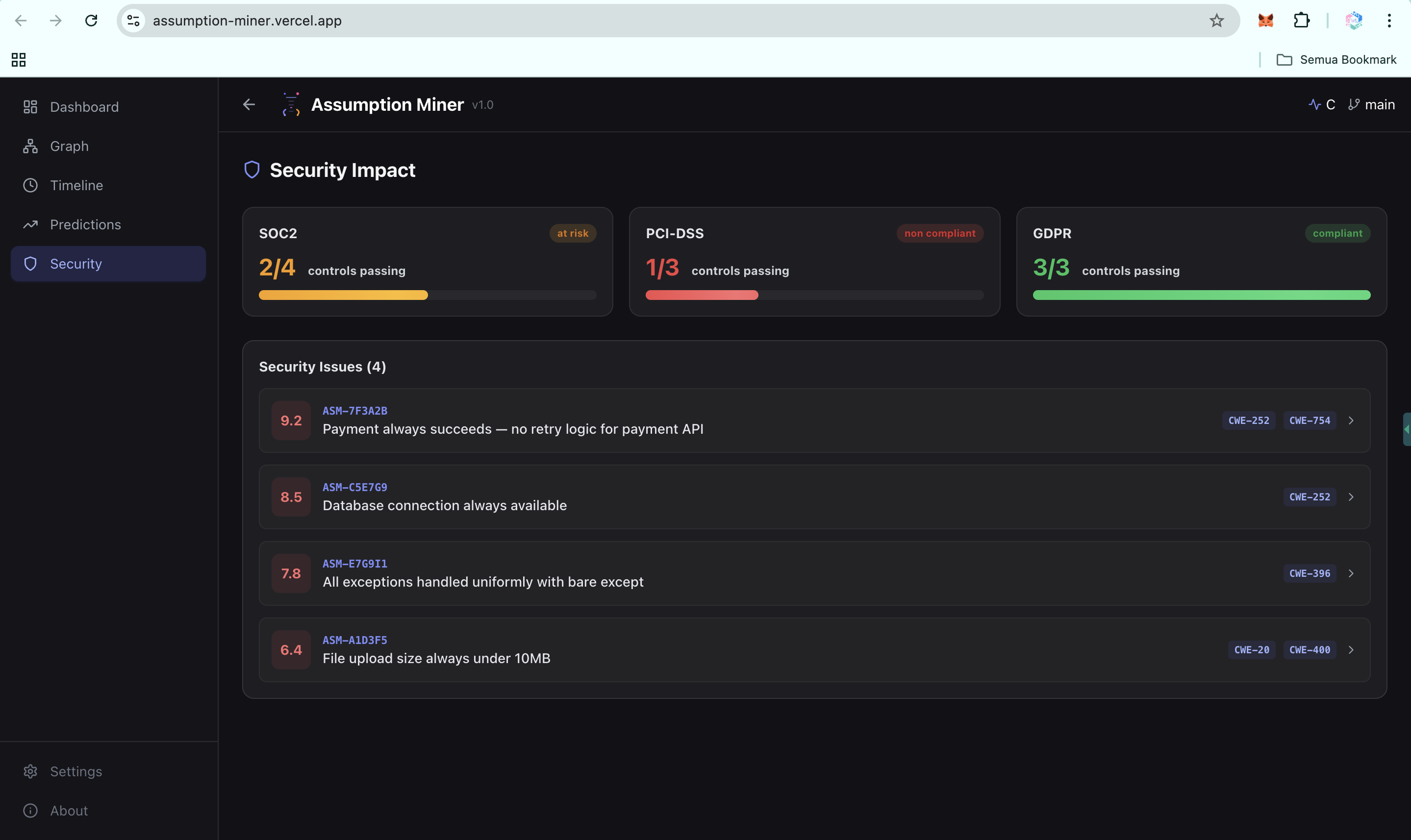
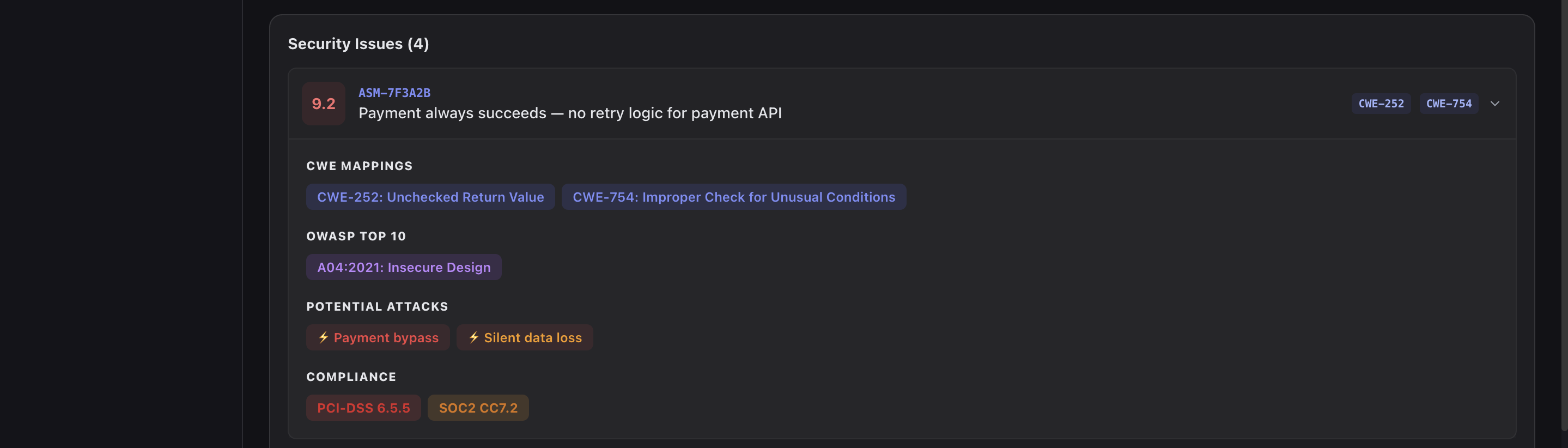
Security: Risk & Vulnerability Insights (UI)
-
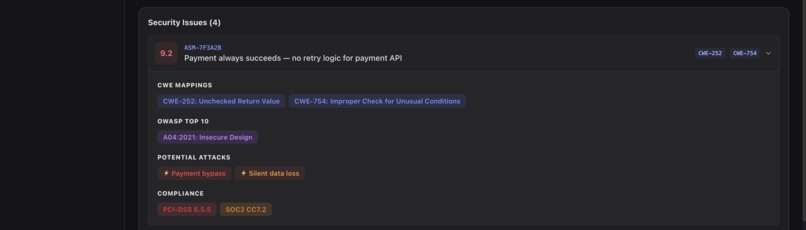
Security: Risk & Vulnerability Insights-2 (UI)
-
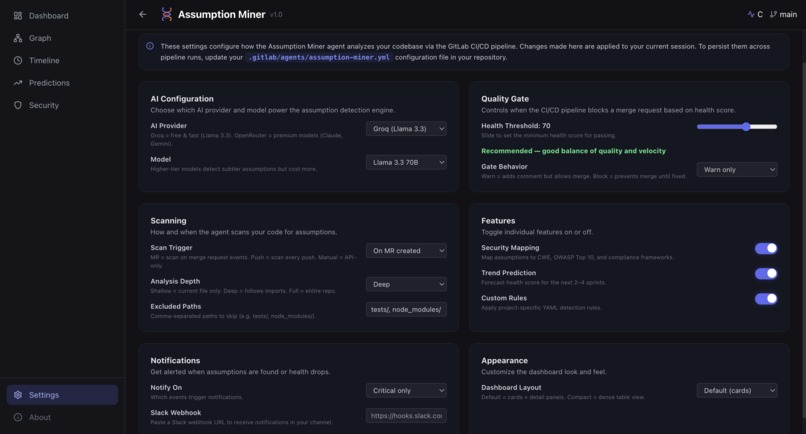
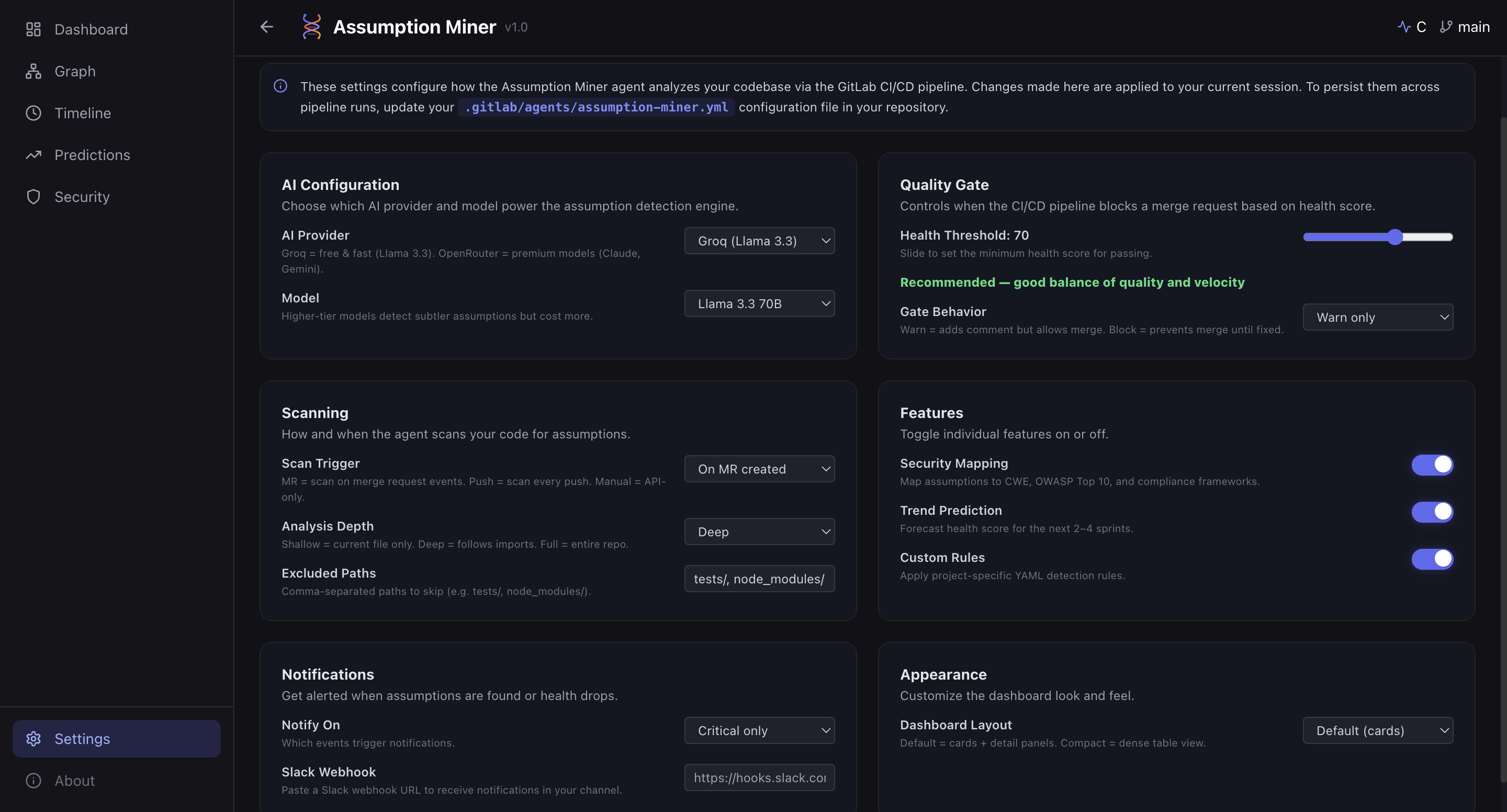
Settings Page (UI)
-
About Page (UI)
-
About Page-2 (UI)
-
About Page-3 (UI)
-
About Page-4 (UI)
-
Google Cloud Run overview dashboard
-
Backend logs on Google Cloud Run
-
Backend metrics on Google Cloud Run
Inspiration
Every war story in software engineering sounds the same: "It worked fine until it didn't." The payment flow that assumed success. The database connection that assumed availability. The file upload that assumed size limits would hold. None of these were bugs in the traditional sense. They were beliefs, implicit, undocumented, unvalidated, baked into the code by developers who were focused on the happy path and never thought to question the assumption underneath it.
I've seen teams spend entire post-mortems trying to answer "where did we assume this?" and come up empty. The assumption wasn't in any ticket, any PR description, or any comment. It was just there, invisible, until production made it visible in the worst possible way.
That's what inspired Assumption Miner. Not a better linter. Not another static analysis tool. Something that looks at what your code believes and surfaces those beliefs before your users become the test suite.
What it does
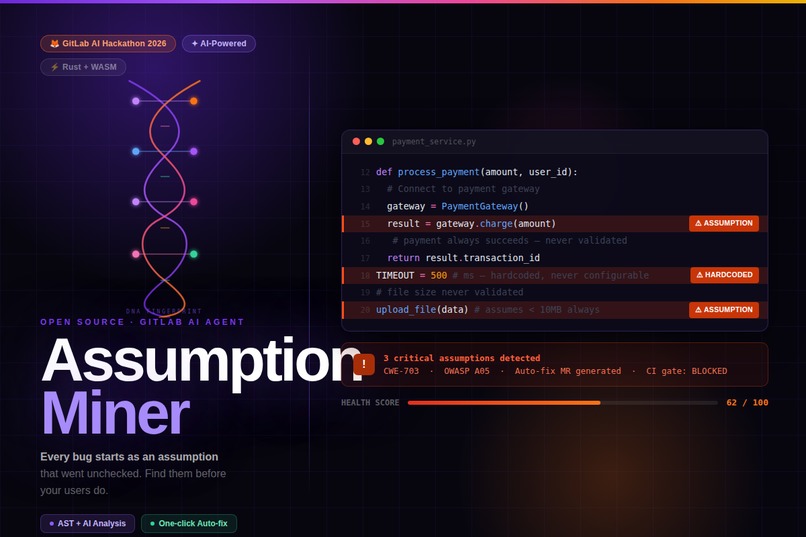
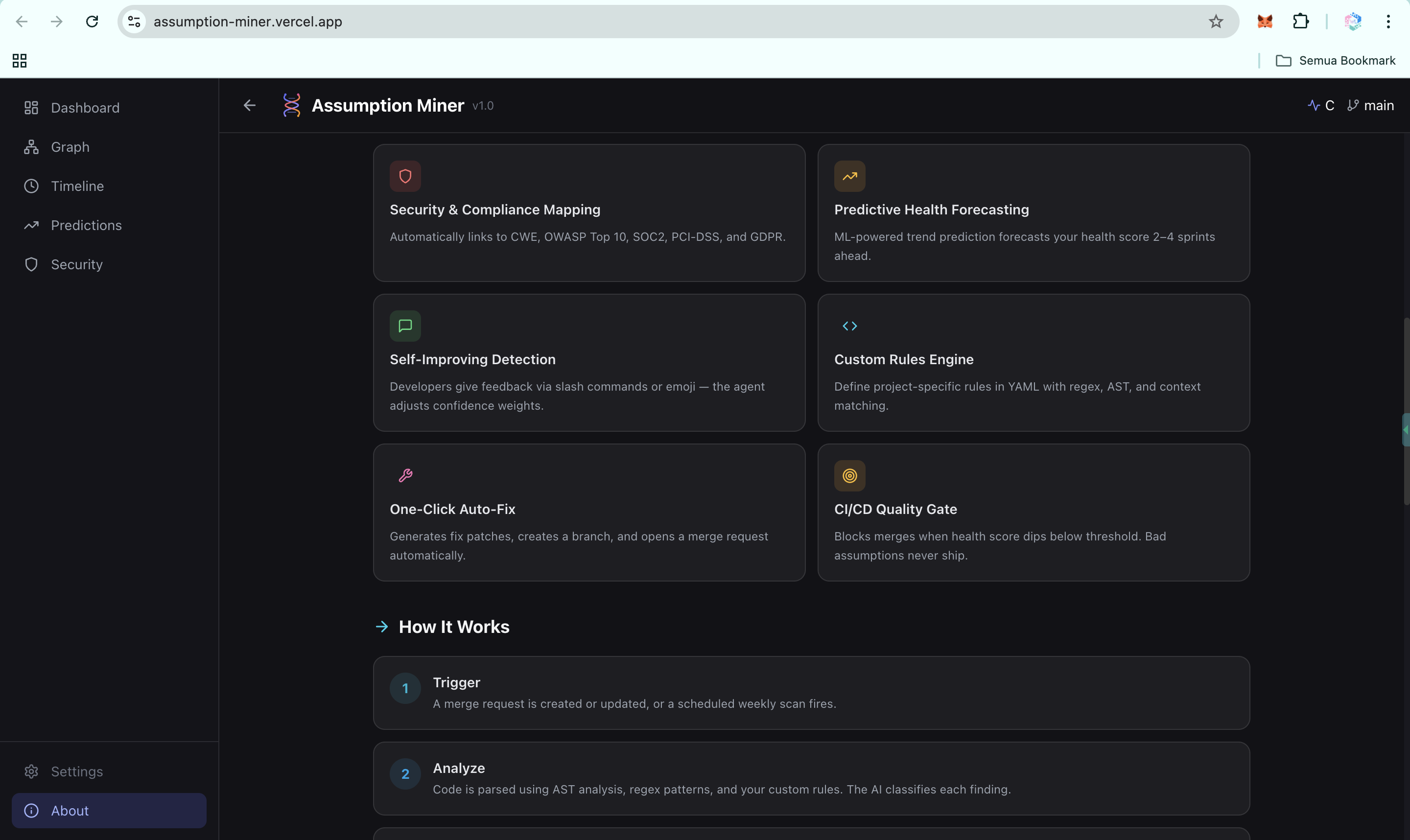
Assumption Miner is a GitLab Duo Agent that detects implicit assumptions in your codebase, tracks them over time, and helps you resolve them before they cause incidents.
It runs automatically on merge requests and on-demand through GitLab Duo Chat. Under the hood, it combines AST-level code parsing with AI-powered reasoning to identify patterns that conventional static analysis misses entirely.
Core capabilities:
- Assumption detection: finds hardcoded thresholds, missing input validation, unhandled error paths, environmental dependencies, implicit ordering, and undocumented API contracts across Python, JavaScript, TypeScript, and more
- DNA fingerprinting: assigns each assumption a stable identity that survives renames, file moves, and refactors, so nothing falls through the cracks during code evolution
- Health scoring: grades your codebase from A+ to F using a Rust-powered scoring engine with Monte Carlo simulation, compiled to WebAssembly for sub-millisecond execution directly in the browser
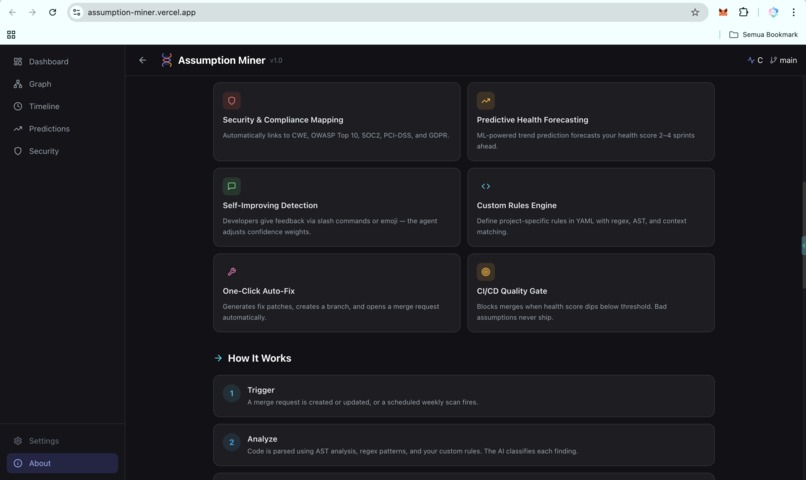
- Security mapping: automatically links every assumption to CWE entries, OWASP Top 10 categories, and compliance frameworks (SOC2, PCI-DSS, GDPR)
- Trend prediction: forecasts your health score 2 to 4 sprints ahead using linear regression and weighted moving average, so teams can act before the slope turns critical
- Auto-fix MR generation: produces fix patches from templates (error handling, null checks, timeouts, input validation), creates a branch, and opens a merge request for one-click resolution
- CI/CD quality gate: plugs into GitLab pipelines and blocks merges when the health score drops below a configurable threshold
- Real-time dashboard: a React frontend deployed on Vercel, backed by a FastAPI service on Google Cloud Run, showing assumptions, risk distribution, dependency graph (3D), timeline, and predictions
How we built it
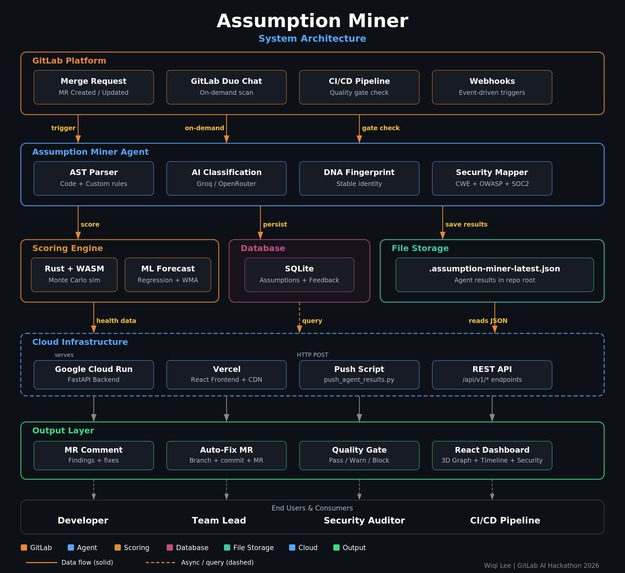
The architecture is a layered pipeline that takes code as input and produces actionable intelligence as output.
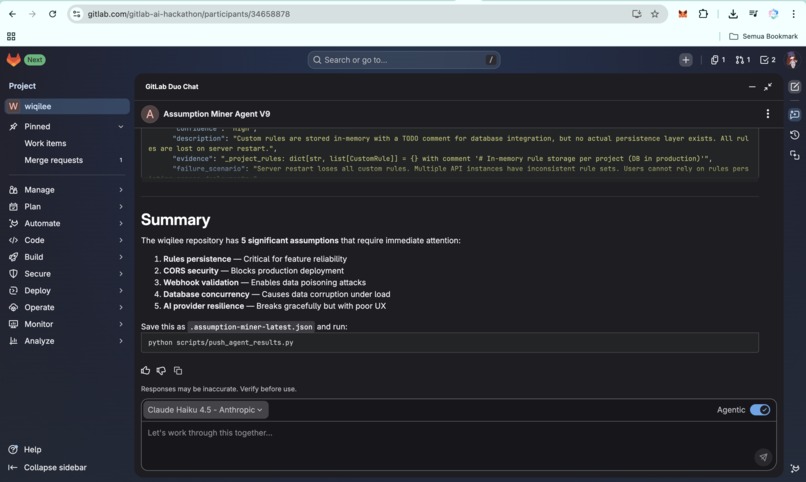
GitLab Duo Agent + Flow (YAML) sits at the entry point. The agent responds to merge request events and on-demand chat prompts. A custom Agent Skill (/scan-assumptions) and AGENTS.md context file shape the agent's behavior and output format, including auto-saving scan results to .assumption-miner-latest.json for downstream processing.
AST parser + custom rules engine (Python) handles the structural analysis layer. It parses source files into abstract syntax trees, then applies pattern matchers (literal, regex, function call, and context-aware) to surface assumption candidates. The rules are defined in YAML and fully extensible per project.
AI classification layer (Groq / OpenRouter) takes the raw candidates and classifies them: severity, confidence, failure scenario, CWE mapping, and recommended fix. Groq with Llama 3.3 handles the primary path for speed; OpenRouter provides fallback access to Claude, Gemini, and Mixtral.
DNA fingerprinting assigns a stable hash to each assumption based on its semantic signature rather than its line number or filename, so the identity persists across refactors and moves.
Scoring engine (Rust compiled to WebAssembly) computes health scores using a weighted formula and Monte Carlo simulation to model uncertainty. It loads directly in the browser for zero-latency scoring with no server round-trip.
ML layer (Python) runs linear regression and weighted moving average over historical health snapshots to generate forward projections. A feedback learning loop adjusts confidence weights based on developer reactions.
Backend (FastAPI on Google Cloud Run) exposes a REST API consumed by the dashboard. Cloud Run provides auto-scaling and zero ops overhead.
Frontend (React + Vite + Tailwind CSS + Three.js on Vercel) renders the dashboard, 3D dependency graph, timeline, predictions, and security pages. Deployed globally via Vercel's edge network with automatic deploys on every push to main.
Challenges we ran into
Making AI output structurally reliable. Getting an LLM to consistently return well-formed JSON with the right schema, across different models and prompt variations, required careful prompt engineering and a defensive parsing layer. Early versions would silently return malformed results that broke the dashboard downstream.
DNA fingerprinting stability. The first hashing approach was too sensitive. Moving a function by three lines would generate a completely new fingerprint, defeating the purpose. Iterating on the semantic signature algorithm to balance sensitivity and stability took longer than expected.
Rust + WebAssembly in a browser context. Compiling the scoring engine to WASM and loading it correctly inside a Vite/React build pipeline surfaced several toolchain compatibility issues. Getting the Monte Carlo simulation to run reliably at sub-millisecond speeds while integrating cleanly with the React state model required multiple iterations.
Slash command registration in GitLab Duo. The slash-command metadata format in SKILL.md frontmatter is not well-documented. An incorrect format (slash-command: enabled instead of the proper nested structure) caused the command to silently fail without any error, which was difficult to debug.
Keeping the dashboard reactive without a WebSocket. Rather than maintaining a persistent connection, the dashboard polls the backend after the push script runs. Getting the timing and state reconciliation right, especially for the health score animations and layout toggle, required careful state management with Zustand.
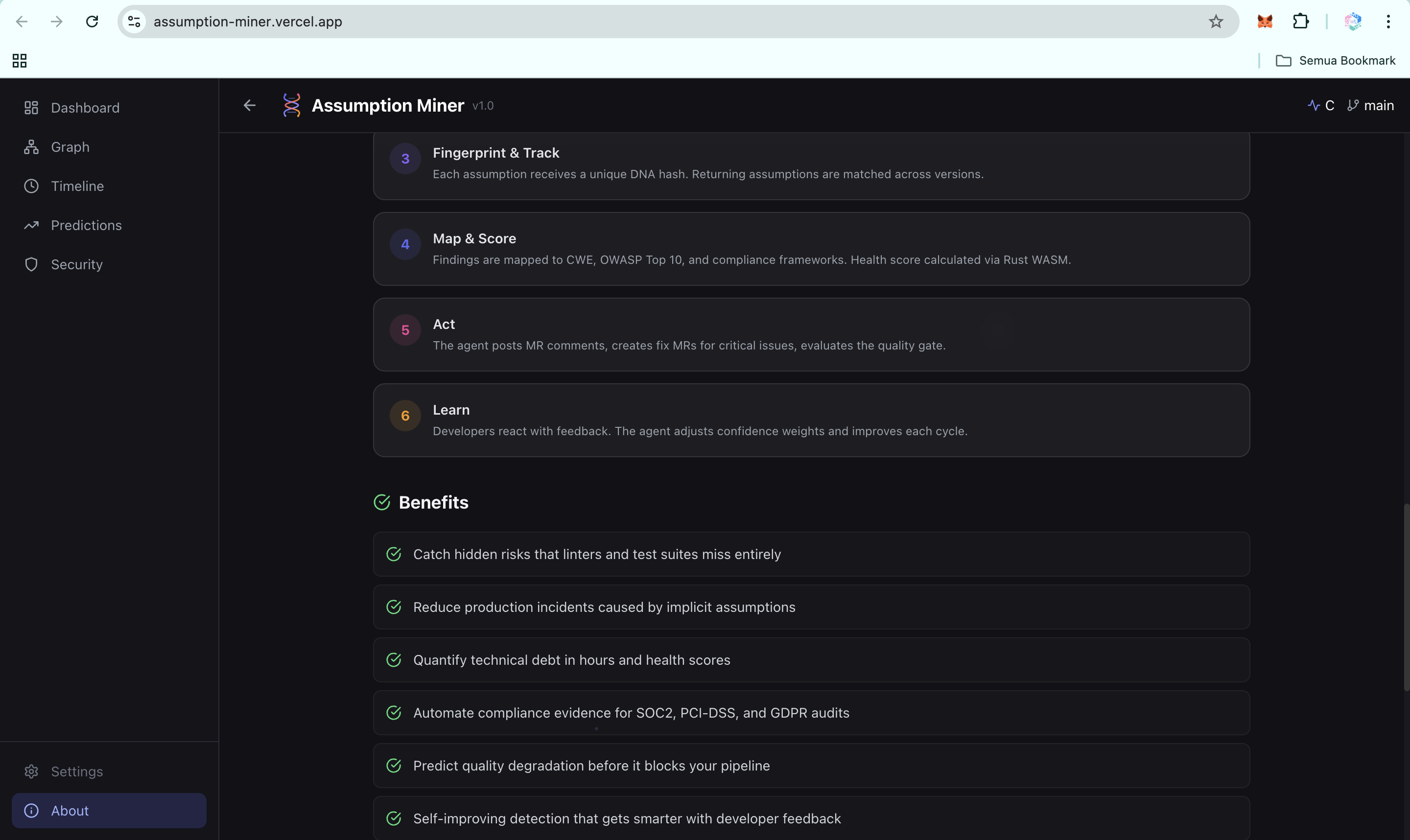
Accomplishments that we're proud of
The DNA fingerprinting actually works. Watching an assumption maintain its identity through a file rename and a function restructure, and seeing it correctly show up in the timeline as "mutated" rather than as a new finding, was one of the most satisfying moments in the build. It makes assumption tracking feel genuinely durable, not fragile.
Sub-millisecond health scoring in the browser. Running Monte Carlo simulation in WebAssembly, compiled from Rust, without any server round-trip, is something most tools in this space don't even attempt. It works, and it's fast.
The agent writes its own output file. In agentic mode with a single natural-language instruction, the GitLab Duo agent scans the repository, classifies findings, saves structured JSON to .assumption-miner-latest.json, and tells the developer exactly what to run next. The loop from intent to dashboard update is one prompt and one terminal command.
End-to-end GitLab integration. The same tool that runs on-demand in Duo Chat also runs automatically in CI/CD as a quality gate and posts structured findings directly to merge request comments. It lives inside the GitLab workflow rather than alongside it.
The 3D dependency graph. Using Three.js to render assumption clusters and their relationships in an interactive 3D holographic view was ambitious for a hackathon timeline, and it shipped.
What we learned
Assumptions are a first-class engineering artifact. Building this project reframed how I think about code quality. Most tools measure what's wrong with code. Assumption Miner measures what code believes. That's a fundamentally different lens, and one that surfaces risk that conventional metrics can't see.
AI agents need context architecture, not just prompts. The quality of the agent's output improved dramatically once AGENTS.md was structured thoughtfully, not as documentation, but as a behavioral contract. What the agent does with a scan assumptions instruction depends almost entirely on the context it has about the project's tech stack, output format expectations, and severity definitions.
WebAssembly is production-ready, but the toolchain isn't forgiving. Rust to WASM to Vite to React is a powerful stack, but every boundary in that pipeline has sharp edges. The tooling has matured significantly, but debugging across that boundary still requires patience.
Agentic mode changes the interaction model fundamentally. The jump from slash commands (which require exact registration) to natural language instructions (which work on intent) made the agent dramatically more accessible. Designing around agentic behavior rather than scripted commands produced better results.
What's next for Assumption Miner
Multi-language depth. The current parser covers Python, JavaScript, and TypeScript well. Java, Go, and Rust support is the next priority. Each brings different assumption patterns (null safety in Rust, checked exceptions in Java, goroutine assumptions in Go) that warrant dedicated detection rules.
GitLab-native assumption registry. Rather than a standalone dashboard, the long-term vision is to surface assumptions directly in GitLab as a custom object type in the issue tracker, linked to the MRs that introduced them and the incidents they contributed to. Closing the loop between detection, tracking, and resolution inside the platform where developers already live.
Cross-repository drift detection. Microservices that share interfaces accumulate assumption drift. One service assumes a field exists that another stopped sending three sprints ago. Detecting this divergence across repos is technically solvable with the fingerprinting infrastructure already in place.
Team feedback calibration. The feedback learning loop currently adjusts confidence weights based on individual reactions. Extending this to team-level calibration, where a pattern dismissed by three separate developers across different PRs gets suppressed globally, would significantly reduce noise for larger organizations.
IDE integration. Bringing the assumption scan directly into VS Code and JetBrains as a background lint pass, with inline decorations on lines that carry unresolved assumptions, would close the feedback loop from days (on MR review) to seconds (while writing code).
Built With
- docker
- fastapi
- gitlab
- gitlab-duo-agent
- gitlab-duo-flow
- gitlabduoagent
- google-cloud-run
- groq
- llama-3.3
- openrouter
- python
- react
- rust
- sqlalchemy
- sqlite
- tailwind-css
- three.js
- typescript
- vercel
- vite
- webassembly
- zustand







Log in or sign up for Devpost to join the conversation.