Associated Rules mining algorithm - ECLAT
ECLAT - Equivalent CLAss Transformation, a highly efficient algorithm to mine correlations between items. This is a Neo4j database extension that implements mining and creating of Associated Rules from transaction data(item set). The classic use cases are shopping cart analysis, recommendations, intelligent search etc.
Submitted to the GraphHACK 2019. (https://neo4j.com/graph-hack-19/)
@Team: GraphActions @Members:
- Min Li, Senior Software Developer, ActionSky Shanghai, China
- Haibo Fu, Senior Software Developer, fuhaibo@actionsky.com. ActionSky Shanghai, China.
- Liang Chen, Product Manager, liangchen@actionsky.com. ActionSky Shanghai, China.
- Weihao(Luke) Xia, post graduate(Data Science major) of University of Sydney, Australia.
What is Associated Rules Mining?
Association rule mining is a procedure which is meant to find frequent patterns, correlations, associations, or causal structures from data sets found in various kinds of databases such as relational databases, transactional databases, and other forms of data repositories.
Given a set of transactions, association rule mining aims to find the rules which enable us to predict the occurrence of a specific item based on the occurrences of the other items in the transaction. Today we will be focusing on ECLAT algorithm and its entension on neo4j.
One of the most well known examples of Associated Rulke Mining is probably 'diappers and beer' through shopping cart mining in which a high correlation had been revealed between these 2 products.
There are several Associated Rules Mining algorithms. The most often mentioned is Apriori, and the one of higher efficiency is ECLAT.
Apriori Overview
Apriori is an algorithnm for frequent item set mining and association rule learning over relational databases. It proceeds by identifying the frequent individual items in the database and extending them to larger and larger item sets as long as those item sets appear sufficiently often in the database. The frequent item sets determined by Apriori can be used to determine association rules which highlight general trends in the database: this has applications in domains such as market basket analysis.
Apriori property (Assumption)
1.All subsets of a frequent itemset must be frequent.
2.If an itemset is infrequent, all its supersets will be infrequent.
Apriori Algorithm

Step1:Apply minimum support to find all the frequent sets with k items in a database.
Step 2: Use the self-join rule to find the frequent sets with k+1 items with the help of frequent k-itemsets. Repeat this process from k=1 to the point when we are unable to apply the self-join rule.

Aprior Algorithm example

Source: https://slideplayer.com/slide/9699938/31/images/52/ECLAT%3A+Tidlist+Intersections.jpg
Dataset(Transactions)
Step1:C1, Calculate the support/frequency of all items.
Step2:L1,Discard the items with minimum support.(In this example, the minimum support is 1)
Step3:C2, Combine two items. (Combination not Permutations, order does not matter)
Step4:C2 after second scan,Calculate the support/frequency of all items in C2.
Step5:L2, Discard the items with minimum support.(In this example, the minimum support is 1)
Step6:C3 and L3, combine three items and calculate tihe support. {ACE 1} and {BCE 2}, discard the items with minimum support.(In this example, the minimum support is 1)
Result: {ACE}
ECLAT Overview
The ECLAT algorithm stands for Equivalence Class Clustering and bottom-up Lattice Traversal. It is one of the popular methods of Association Rule mining. It is a more efficient and scalable version of the Apriori algorithm. While the Apriori algorithm works in a horizontal sense imitating the Breadth-First Search of a graph, the ECLAT algorithm works in a vertical manner just like the Depth-First Search of a graph. This vertical approach of the ECLAT algorithm makes it a faster algorithm than the Apriori algorithm. The basic idea is to use Transaction Id Sets(tidsets) intersections to compute the support value of a candidate and avoiding the generation of subsets which do not exist in the prefix tree.
Original algorithm was published by Zaki, M. J. (2000). "Scalable algorithms for association mining", IEEE Transactions on Knowledge and Data Engineering. 12 (3): 372–390.
ECLAT Algorithm

ECLAT Algorithm Example
Same dataset as Aprior algorithm example but using different approach Dataset {10 | A,C,D} {20 | B,C,E} {30 | A,B,C,E} {40 | B,E}
Step 1: K=1 {A | 10,30} {B | 20,30,40} {C | 10,20,30} {D | 10} {E | 20,30,40}
Step 2:K=2 compute using intersection {A,B | 30} {A,C | 10,30} {A,D | 10} {A,E | 30} {B,C | 20,30} {B,E | 20,30,40} {C,D | 10} {C,E | 20,30}
Step 3:K=2 compute using intersection {B,C,E | 20,30}
Result
ECLAT advantage over Aprior
1.Memory Requirements: Since the ECLAT algorithm uses a Depth-First Search approach, it uses less memory than Apriori algorithm.
2.Speed: The ECLAT algorithm is typically faster than the Apriori algorithm.
3.Number of Computations: The ECLAT algorithm does not involve the repeated scanning of the data to compute the individual support values.
Neo4j Database Extension
As the world #1 graph database platform, Neo4j inveted and implemnted Cypher query language for graph traversals, and it also allows developers to extend database capabilities by building and deploying extensions using its Traversal Framework and APIs in Java.
There are two very famous database extensions available for everyone to use(for FREE): APOC (Awesome Procedure Of Cypher) and ALGO(rithms for Graph). More details can be found from:
- APOC: https://neo4j.com/developer/neo4j-apoc/
- ALGO: https://neo4j.com/docs/graph-algorithms/current/
Database extensions are developed in Java, compiled into JAR and copied to plugins folder of Neo4j server home. After re-start database services, they can then be executed in Cypher:
CALL mypackage.procedure() YIELD value RETURN value;
The Implementation
All source code and compiled binary can be found in this repository.
Main Java Classes: AssociatedRulesAlgoProc
1. The main procedure - eclat()
@Procedure(mode = Mode.WRITE)
@Description("mypackage.assocrule.eclat(cypherItemset, minSupportRatio, optimized) YIELD value")
public Stream<LongResult> eclat(
@Name("cypherItemset") String cypherItemSet,
@Name("minSupportRatio") Double minSupportRatio,
@Name("optimized") Boolean optimized) { ... }
The procedure takes 3 parameters:
- cypherItemSet: Cypher to execute that returns item sets.
- minSupportRatio: minimal support ratio, i.e. min percentage of transactions the item should be included. Default value is 0.01(1%)
- optimized: whether to use Triangular Matrix to optimize execution. Default value is true.
2. The algorithm - runAlgorithm()
This is the body of ECLAT algorithm.
3. save() and saveSingleItem()
These are procedures to save items into either a local file or Neo4j database (by executing a Cypher query). When destination is 'neo4j', results will be written into Neo4j(see secsions below).
Associated Rules in Neo4j
1. Writing item sets into Neo4j
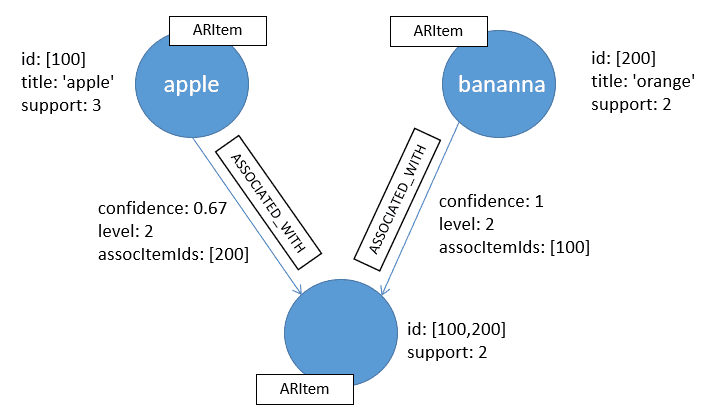
When running in Cypher, the eclat() procedure will write generated rules into Neo4j as ARItem(so by default the destination is 'neo4j'), connected by ASSOCIATED_WITH relationships.

The ARItem nodes have the following properties:
- id(optional): list of database internal id(s) of the associated single item or item set.
- support(populated): the number of occurrences in transactions.
- title(optional): the description, only available for single item.
The ASSOCIATED_WITH relationship has the following properties(all populated):
- confidence: occurrences of itemset / occurrences of parent itemset
- level: size of itemset
- assocItemIds: internal ids of associated items
2. The Cyher used
We will use the following Cypher query to store associated rules after the algorithm has done calculations on item sets:

Here, apoc.coll.sort() is used to sort items in the list so that for item sets that have the same items, they are identical. The script can be found under cypher folder of this repository.
3. A simple example
Let's have a look at an example.
Given a set of transactions below: {apple, bananna} {apple} {apple, bananna}
and ids are: apple - 100, bananna - 200
We will have the associated rules: {apple}, 3 {bananna}, 2 {apple, bananna], 2
Deployment
You may copy procedures-1.0-SNAPSHOT.jar to /plugins, then restart the database service:
bin/neo4j start
You can also download the project soource code and compile it by yourself.
The Test
Environment Details
Intel i7 7500 2 core; 20GB RAM; 1TB SSD.
Windows 10 Professional; JDK 1.8_144.
Neo4j Community Edition 3.5.5.
APOC version 3.5.0.2
Sample Database: Meetup
You can download it from this repository. After download, unzip it to a folder and update neo4j.conf to point to it:
dbms.active_database=meetup.graphdb dbms.directories.data=/your/data/folder
Restart neo4j database service.
This is the graph meta model of Meetup:

Test #1
With Meetup database, we will run the following Cypher to find Topics that are used by multiple Groups(the item set):

This will return 22 records.
Before we actually run the algorithm, let's create an Index to improve database performance for update:
CREATE INDEX ON :ARItem(id)
Now let's use the above query as the input to ECLAT algorithm:

The query finished in 9 seconds, and created 282 associated rules.
Some tips: 1) We use filter on size((Group) -[:HOSTED_EVENT]-> (Event)) > 100 to only return active groups that have enough events hosted, which will reduce total transactions / item sets;
2) We use 0.1 / 10% of returned transactions as minSupportRatio, which is 3 after rounded as the minimal support level(threshold). Topic(s) (Item / Itemset) that has been referred by Groups over this threshold will be included as associated rules. Always make sure this value is at least 2, otherwise all items and possible subsets will be included(once the support is 1), which can cause a lot of useless rules created.
Test #2
Using the same Cypher, with different parameters:
- size((g) -[:HOSTED_EVENT]-> (Event)) > 10
- minSupportRatio : 0.01
Results:
- items = 703, transactions = 222
- single = 169, itemset = 8956
- algo time = 1s, db-time = 354s,
Test #3
Using the same Cypher, with different parameters:
- size((g) -[:HOSTED_EVENT]-> (Event)) > 10
- single = 516, itemset = 64638
- minSupportRatio : 0.005
Results:
- items = 938, transactions = 317
- algo time = 221s, db-time = 2816s,
- max Java heap = 7GB
Search for related items / recommendations
Below sample queries are based on results of Test Case #2 above.
We will use the following query to find assoicated words for 'Data Science'(check the first line):

And have these words returned:

Interestingly, from those top 10 most associated words/topics, some high confident one has less degree(connections to other topics). This is understandable as more popular topics may have a higher support to other topics. By having both confidence and degree, it's possibile to further define a weighte score like 'relevance', which considers both relevance to this topic, as well as relevance to overall topics.
We pick 'Hadoop' from the list, so to have 2 topics ['Data Science', 'Hadoop'] to start with, and run the query again (by changing the first line) to have these results:

With 3 topics ['Data Science', 'Hadoop', 'NoSQL']:

The graph below shows the ARItem nodes and how they are connected:

Try It Yourself
We have created a sandbox for you to try out this procedure. Please follow the details below:
Host: User: Code:
Feedback & Comments
Any is welcome. Happy hacking!!!









{kind=link}
Log in or sign up for Devpost to join the conversation.