-
-
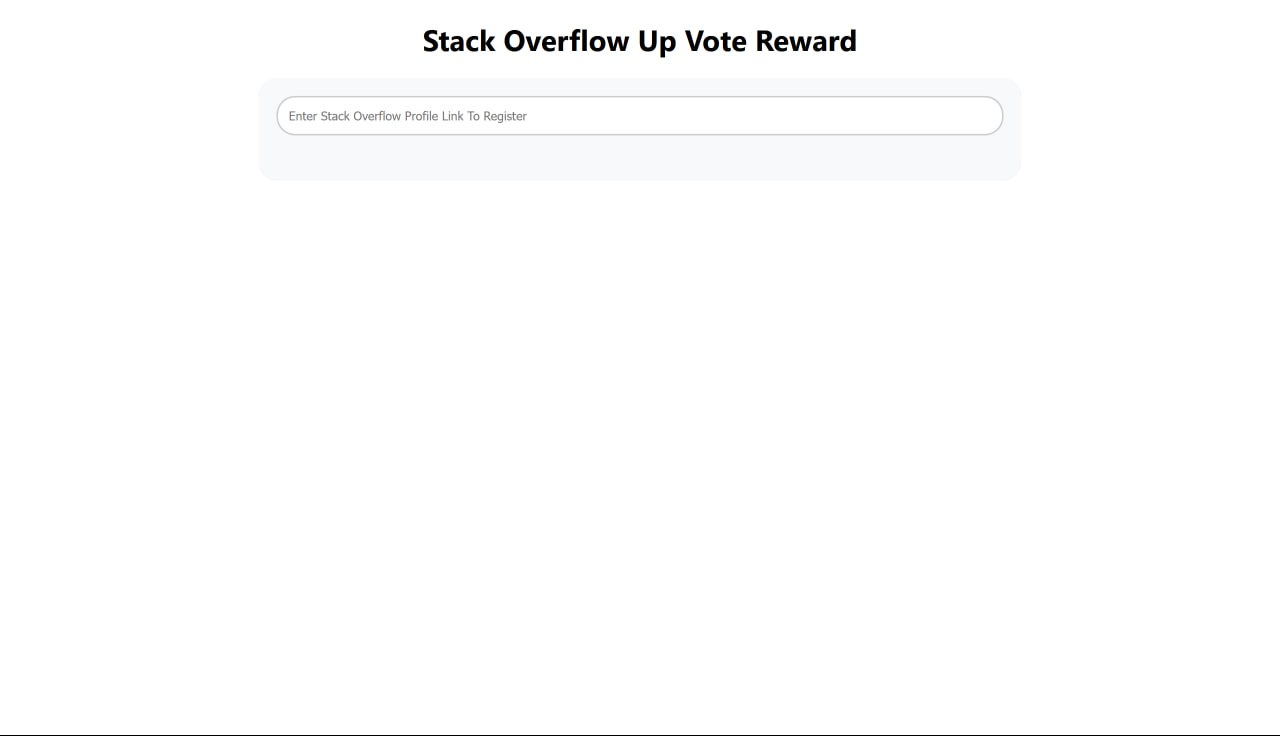
Register as contributor
-
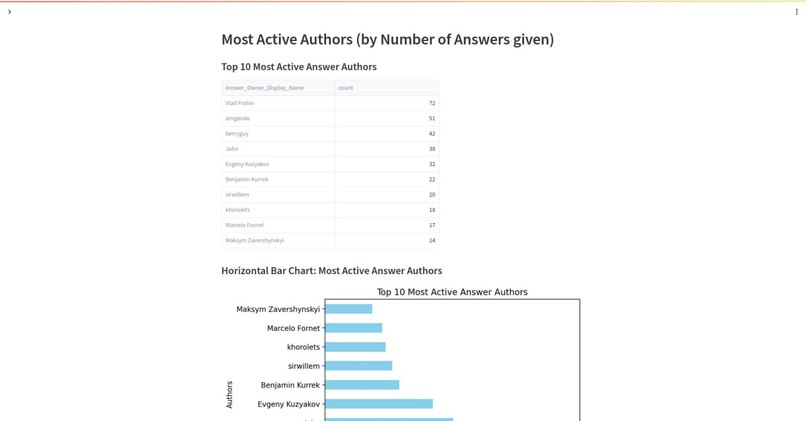
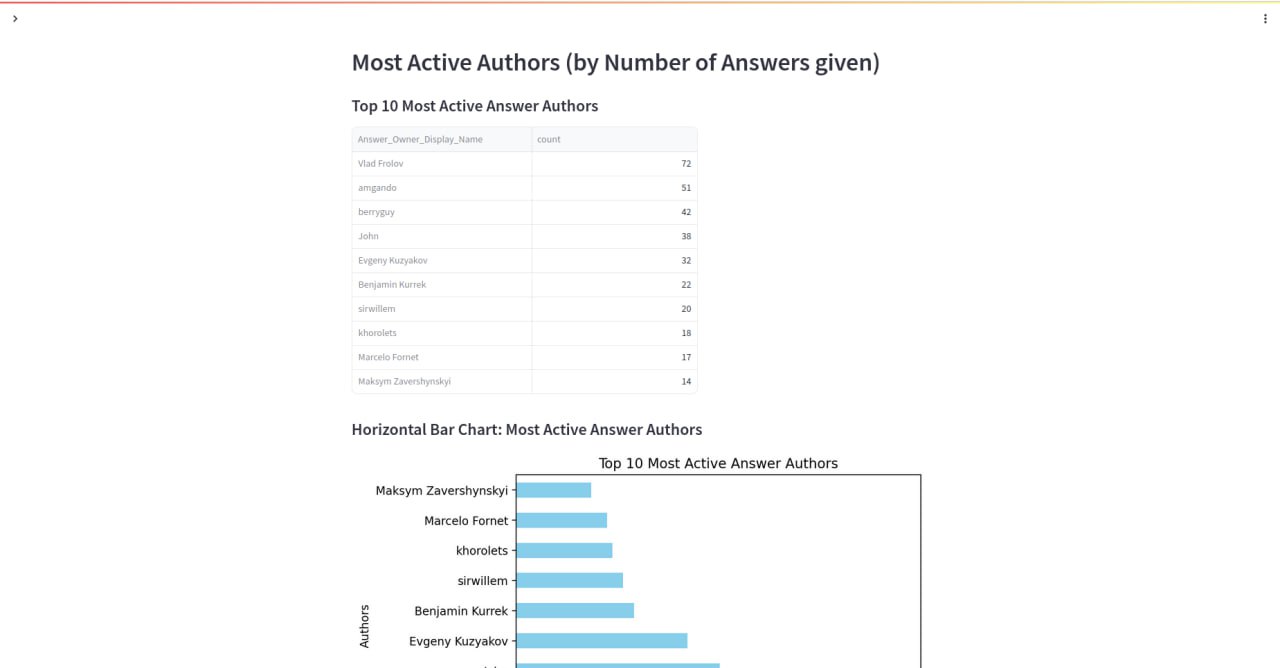
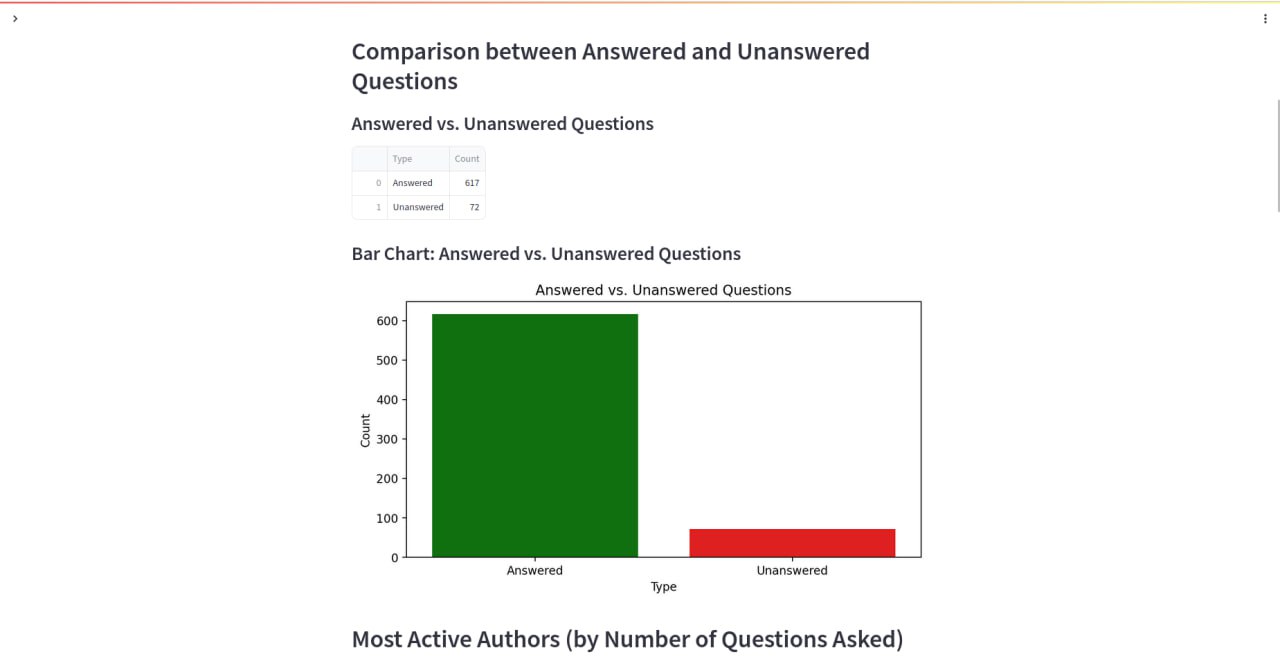
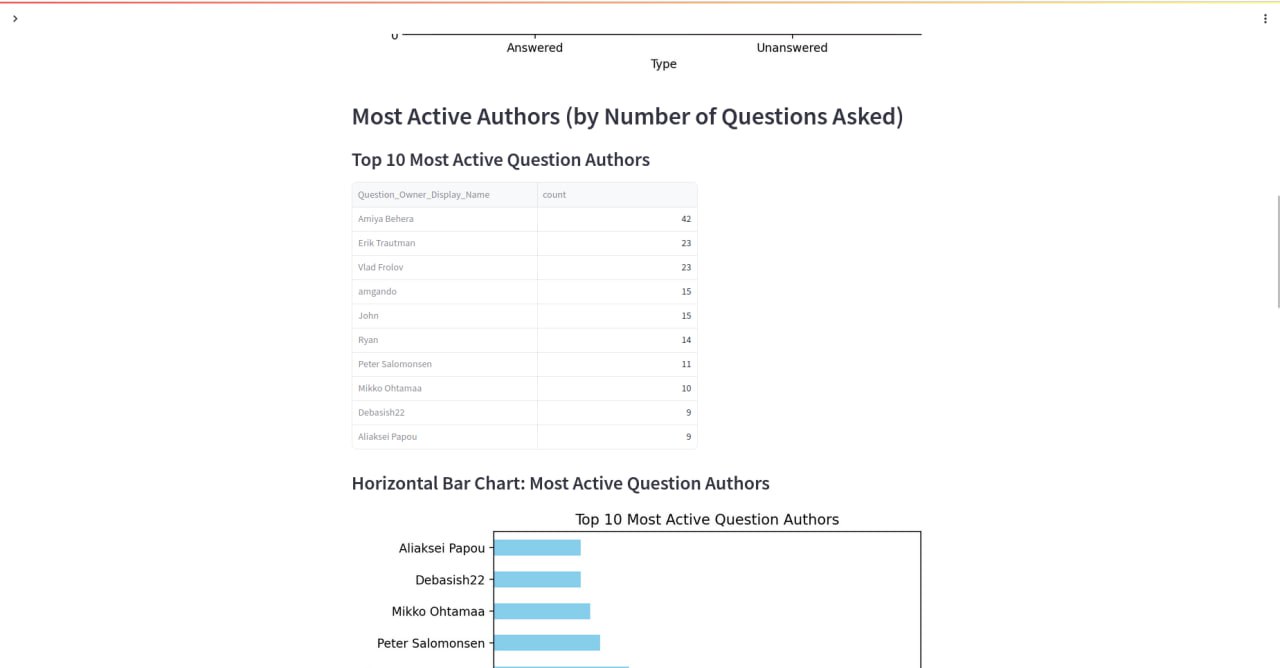
Admin Panel & Reports
-
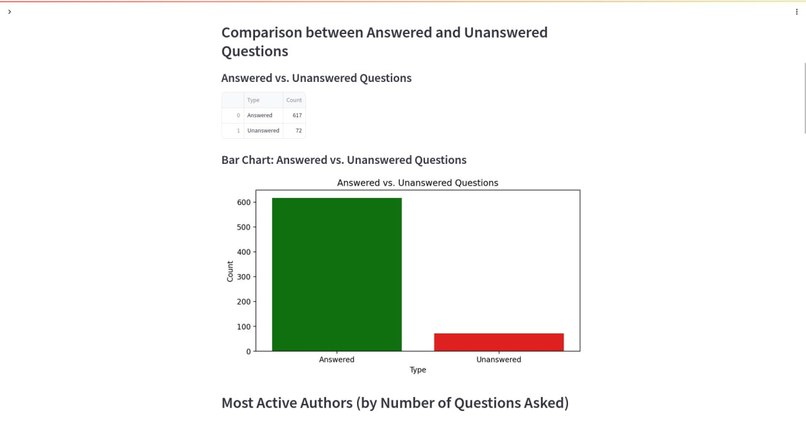
Admin Panel & Reports
-
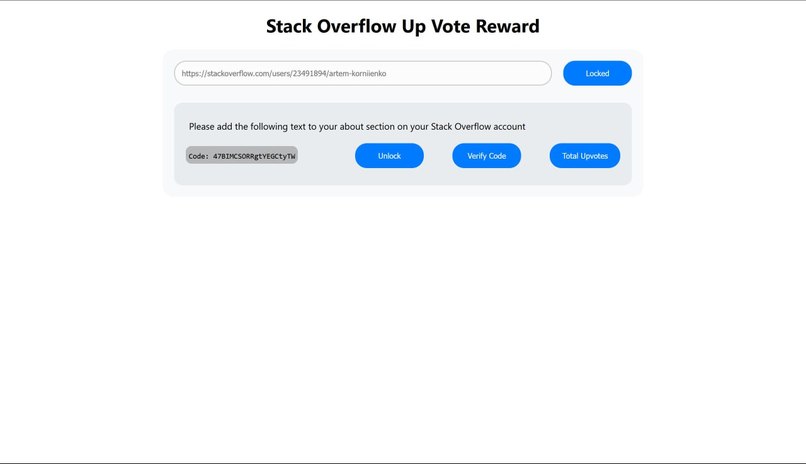
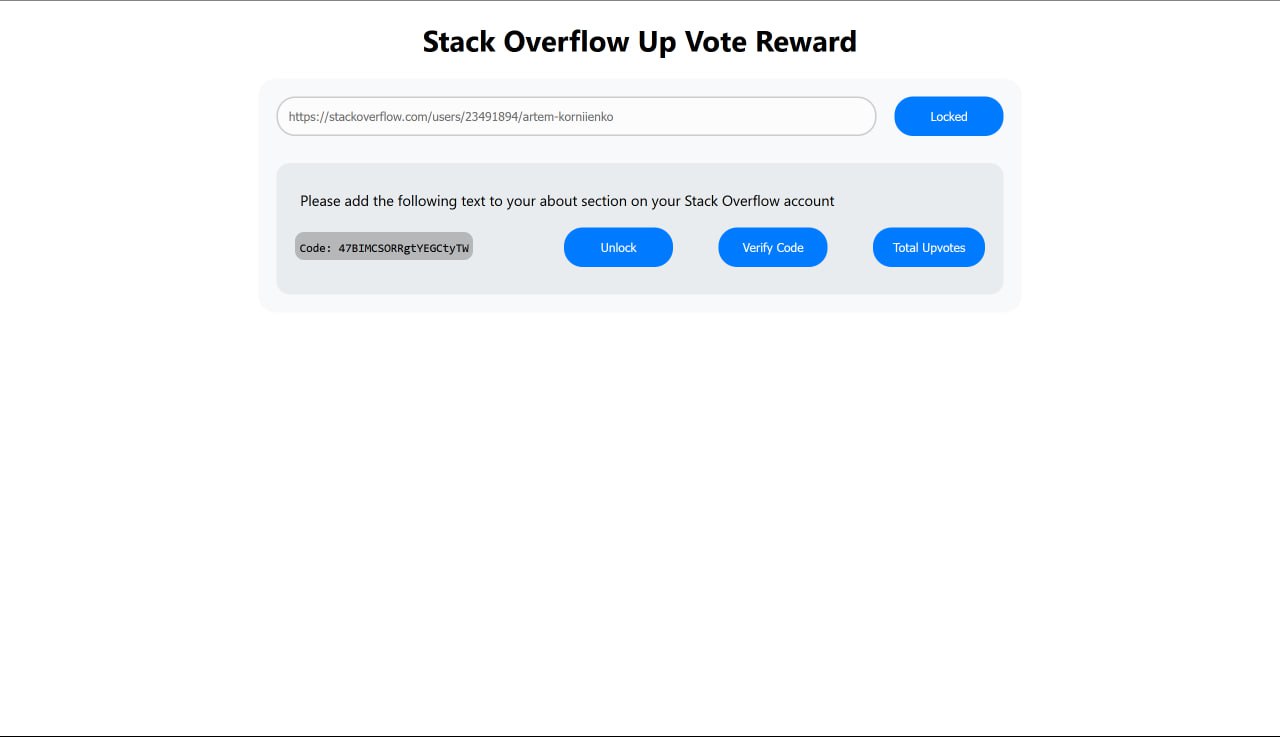
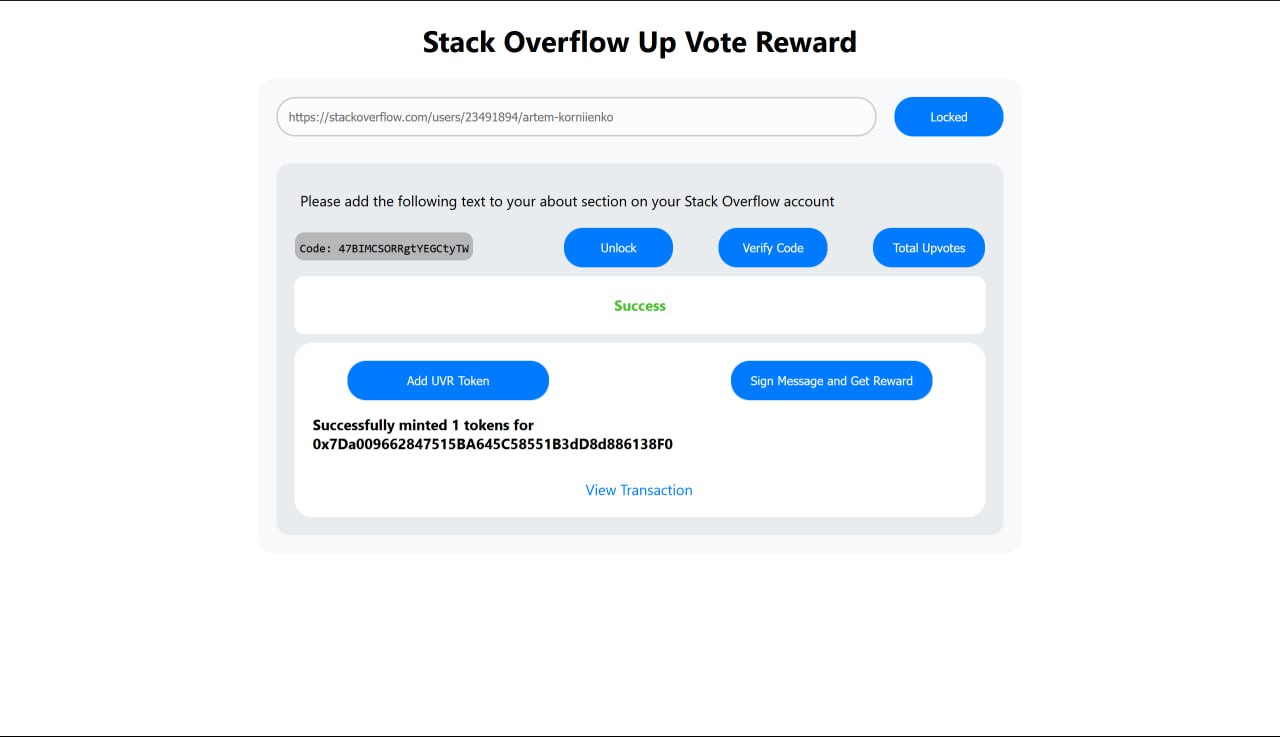
Proof of Account on StackOverflow
-
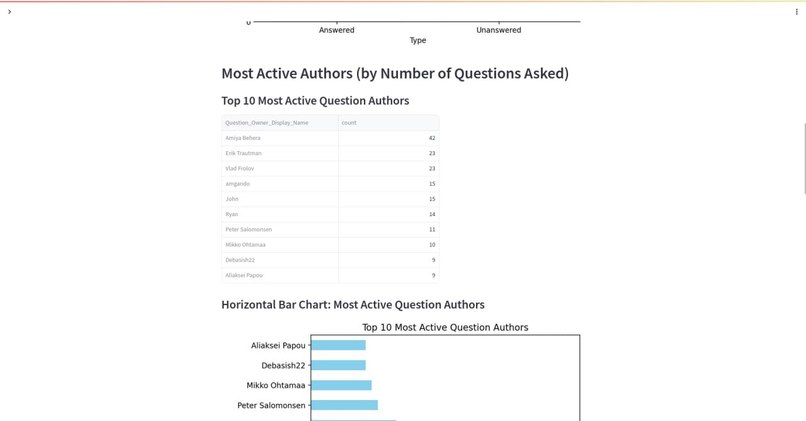
Admin Panel & Reports
-
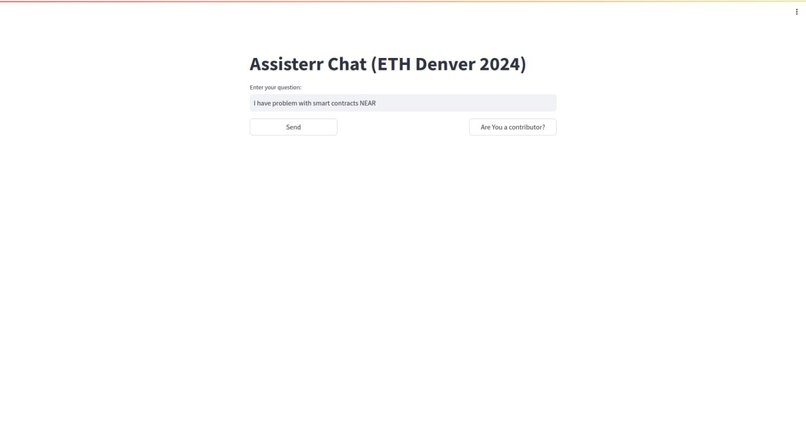
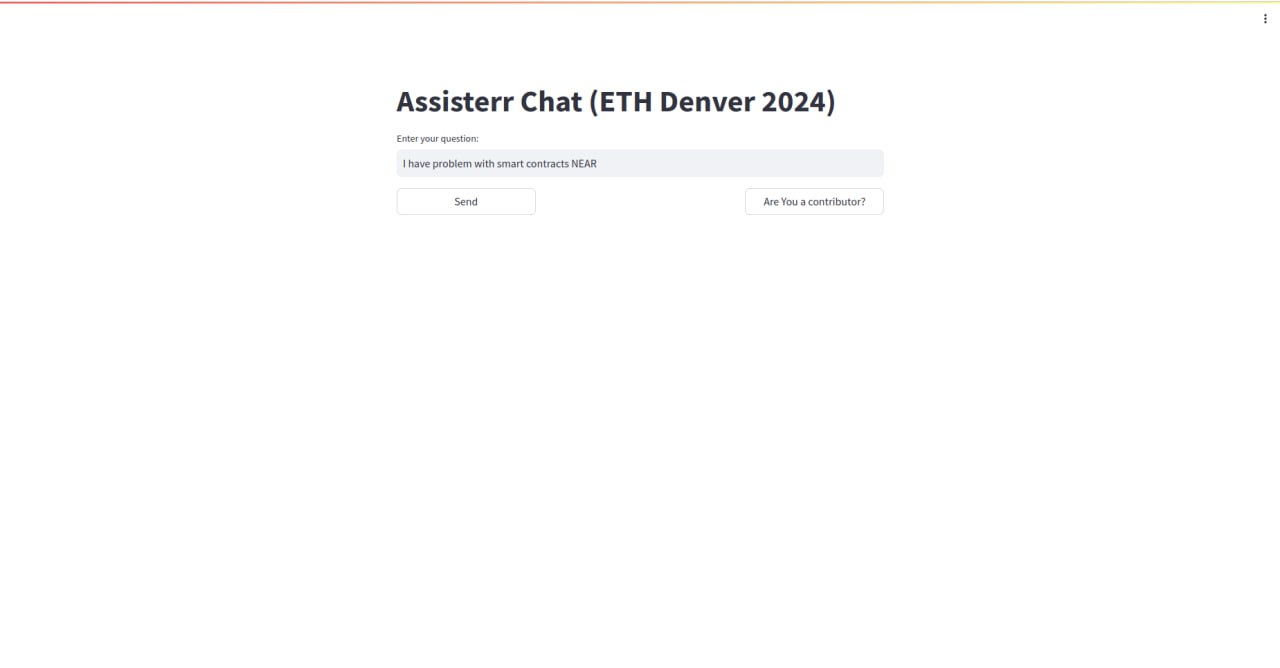
AI Agent Chat Prompt
-
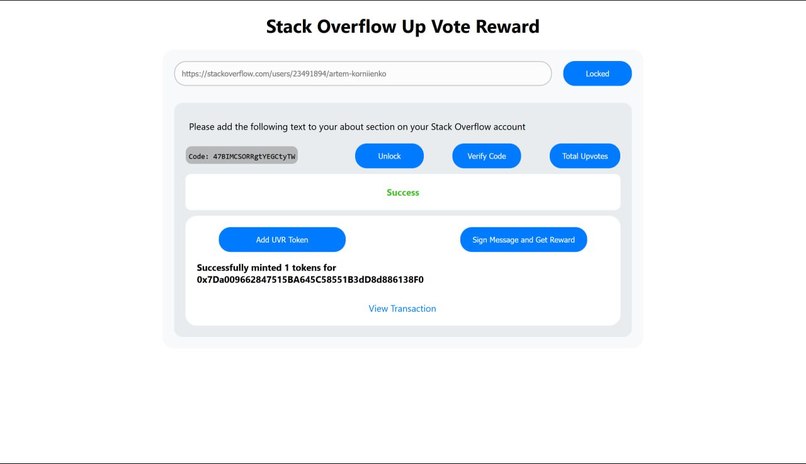
Minting of UVR tokens
-

Proof of Account on StackOverflow
Inspiration
Developers often struggle to get timely support while building and often ask questions on StackOverflow. This can be a solution, but there is a lack of incentive to provide the answers and evaluate its quality by other contributors.
Over the last year, LLMs have empowered real-time conversational chatbot support, but the problem is getting updates regularly. We aim to solve this by incentivizing regular data inference.
What it does
Our solution is a incentive-driven framework that lays at the intersection of AI, Web3, and DevTooling and can be used to incentivize the creation of community-owned AI models.
To tackle this challenge, we have built an incentive-driven framework that encourages the community to contribute by answering questions at the StackExchange-style interface.
How we built it
We built 2 components in our solution:
- Upvote Reward Token - UVR token is used to incentivize valuable contributions and their Validation by the community. For the Hackathon, we created at Polygon Mumbai Testnet UVR ERC20 token that is minted as a reward. If a developer wants to claim rewards, he must submit a Proof of Account. That means he needs to prove that he is the owner of the StackOverlow account. That can be done by putting a code in the About section of his StackOverflow account. After that, he would need to provide his address on which UVR token rewards would be sent. To do it, he needs to pass the Proof of Wallet procedure by signing (do sign) his StackOverflow user_id with his Wallet (MetaMask). The UVR tokens would be minted at his wallet address. The amount of tokens minted equals the sum of all upvotes in that particular tag.
- RAG model - The AI part of our solution utilizes the RAG model. Which provides efficient data inference compared to model finetuning. The retriever component is the Pinecone Vector Database, where every vector is a scraped question/answer pair from StackOverflow's "near protocol" tag. Content is categorized by topic/area/programming language and inserted in a database. That also enables provable training functionality, since every vector represents a traceable content chunk. When a developer asks a question, a similarity search is performed on a vector database where question/answer semantics are taken into consideration. With the most similar answers, LLM (ChatGPT 4.0) is poked to structure a fine answer to the developer.
Challenges we ran into
Web3 integrations were more complex than we expected.
Accomplishments that we're proud of
We've managed to make a comprehensive solution in short period of time. Now we can use the same approach to Reward any user data inference;
What we learned
We have learned how to trace the data from the users based on StackOverflow platform, how to measure the Validators input and store those data to be used in the future; Except that we biold the whole pipeline of embedding user-generated data to the Vector DB.
What's next for Assisterr - Incentive Driven Models
Our next steps:
- Integrating the incentive-driven inference to AI DevRel Agent that we developed earlier for NEAR based on its tech documentation;
- Tests with users, collecting feedback;
- Expanding our framework for additional use-cases;
Built With
- ethers
- javascript
- llm
- pinecone
- python
- redis
- streamlit
- web3



Log in or sign up for Devpost to join the conversation.