-
-
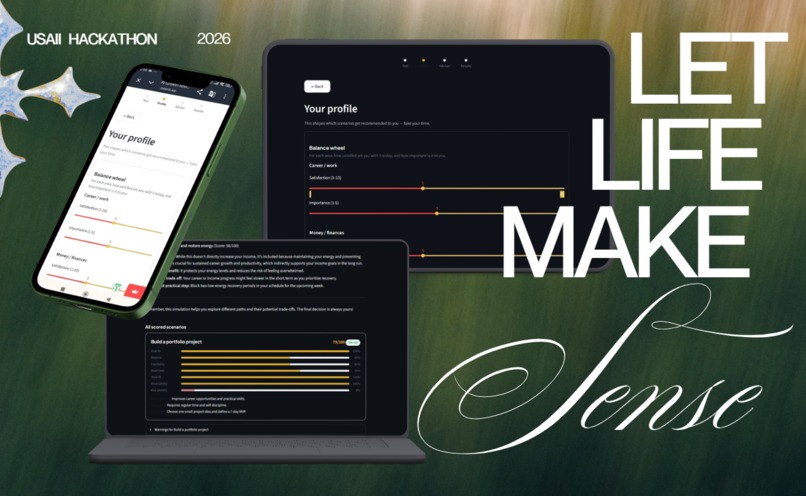
main cover
-

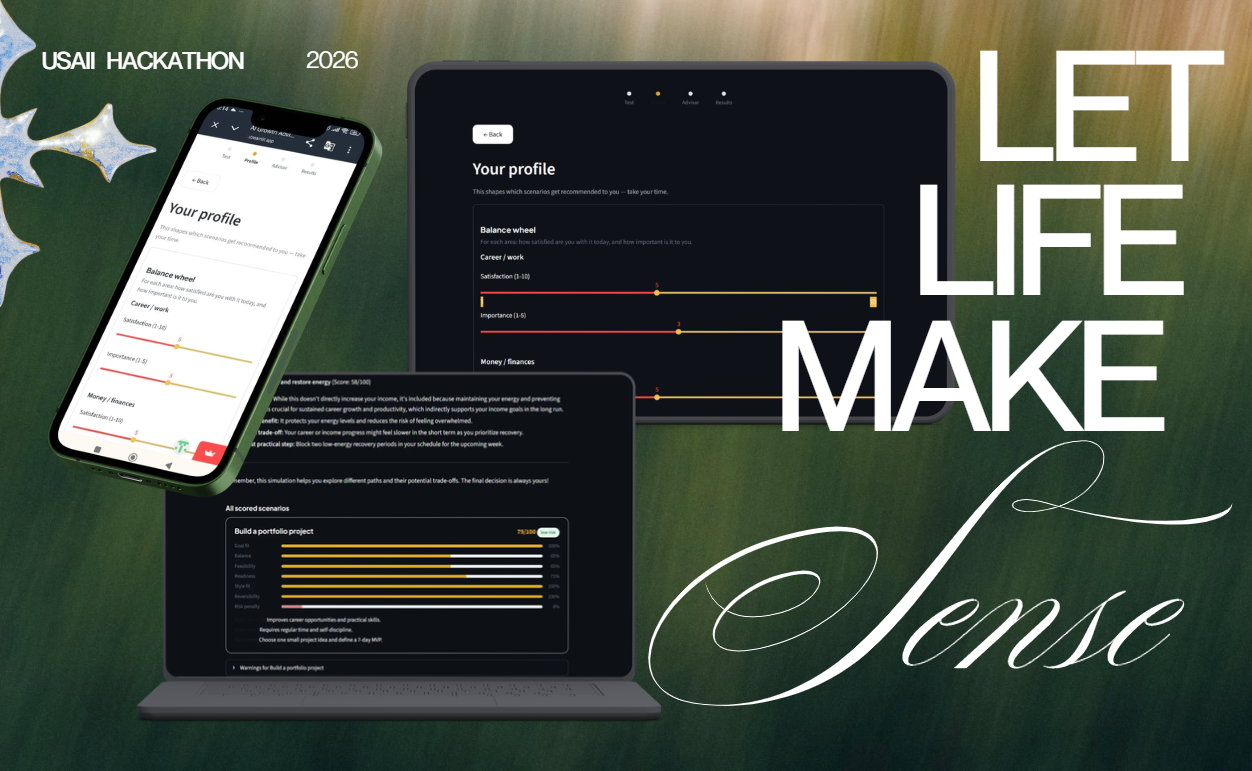
secondary poster

Inspiration
People we encounter that appear “stuck” (in careers, finances, relationships, etc.) typically have an abundant supply of “what-to-dos.” They’ve read the articles, watched the videos, they generally know “what they ought to do.” What these individuals are missing is something a bit more subtle: “Which choice is most appropriate for MY life, right NOW, in light of my available energy, my constraints, and the compromises I am genuinely willing to make?” This question is structurally different from “What are my choices?” and answering it requires reasoning over how an option impacts their present life’s balance, their capacity, their tolerances, and their working style, considering unarticulated costs. We couldn’t find a tool to do this effectively. Either they offer more generalized wisdom, or they offshore the entire task to some language model that, lacking a structured foundation, produces authoritative, non-traceable pronouncements. We were also interested in the psychology of the problem. Productivity isn’t, afterall, simply an intellectual exercise. Loss aversion drives many decisions and our willingness to take on a task is dependent on the state of our energy resources. What is objectively a superior outcome may be a dreadful choice for someone who has no time, limited support, or is already exhausted. We aimed to design an experience that treated human psychology as a design specification rather than as merely a channel for communication.
What it does
Assesta is an AI growth advisor structured around three acts. Profile. The user completes a structured intake across five clusters: a Life Balance Wheel rating satisfaction and importance across six life domains (career, money, learning, relationships, health, free time), a goal specification (focus area and specific request), a capacity assessment (hours per week, budget, energy, skill), a motivational profile (autonomy, support levels), and a working style assessment (structure need, self-discipline, social energy, stress tolerance, risk attitude). The user can also add personal notes, such as scenario ideas they are already considering, with tags and risk flags. Simulate. A deterministic scoring model, pure Python, no language model, computes seven sub-metrics for every scenario in the shared library and ranks them by final score out of 100. Each scenario is scored on goal fit, balance score (weighted by how much each domain matters to this specific user), feasibility, readiness, action style fit, reversibility, and a risk penalty that accounts for critical area harm, overload risk, and uncertainty. The user receives a full score breakdown, trade-off descriptions, contextual warnings, and a concrete first step for each option. Advice. A conversational AI advisor, powered by Gemini 2.5 Flash, has the user's complete profile injected into its system prompt at session start. It knows their energy level, their risk tolerance, their balance gaps. A separate LLM call translates the completed scored results into plain language, explaining why each scenario ranked where it did. The human chooses their path and the system never chooses for them.
How we built it
The stack is deliberately minimal: Streamlit for the full frontend (intake, results, chat), Python 3.11 for the scoring engine, Gemini 2.5 Flash for both LLM roles, and Supabase (PostgreSQL) for persistence. The most important architectural decision was isolating the scoring model completely. life_decision_model/ is a self-contained Python package with one public entry point: run_model(user_profile, scenarios) → dict. It imports nothing from Streamlit, the database, or the LLM. It is fully testable in isolation and produces a completely auditable output: a ranked list with score breakdowns, risk levels, and warnings. The LLM receives this completed output and translates it — it cannot alter a score or reorder a scenario. The scoring formula integrates six psychological frameworks: the Life Balance Wheel drives the balance score through importance-weighted domain gaps; HEXACO personality dimensions are captured implicitly through working style sliders and feed the style fit metric; Self-Determination Theory maps autonomy and support levels to readiness; the Transtheoretical Model proxies stage-of-change position from motivation and energy; Prospect Theory applies a loss-aversion-inspired reversibility weight so irreversible scenarios are structurally penalised; and Conservation of Resources theory powers the overload guard — the model actively resists recommending paths that would deplete the user's energy base.
$$\text{score} = 0.30 \cdot \text{GoalFit} + 0.20 \cdot \text{BalanceScore} + 0.15 \cdot \text{Feasibility} + 0.15 \cdot \text{StyleFit} + 0.10 \cdot \text{Readiness} + 0.10 \cdot \text{Reversibility} - \text{RiskPenalty}$$ decision_engine.py orchestrates the full pipeline: load profile from Supabase → load scenario library → run model → persist the result with full profile and scenario snapshots as JSONB → pass to the LLM explainer. The snapshot pattern means every result is reproducible and comparable across time. The chat advisor injects the profile into every session, keeping temperature at 0.4 and thinking budget at zero for response speed. What-if simulation requires no extra logic — the app simply calls run_model() twice with different profiles and compares the outputs. The warning engine runs separately from the score. It surfaces five signal types — critical area harm, overload risk above 0.5, high uncertainty combined with low reversibility, scenario-level risk tags, and mismatches between the user's hidden concerns and a scenario's contraindication flags — without double-counting them in the formula
Challenges we ran into
We had no training set of “correct” rankings to validate against. The risk penalty was particularly tricky, if too aggressive, it dominated the score for any low-energy user and made all scenarios look equally bad. We iterated across many realistic profile examples until the formula produced meaningfully differentiated results across genuinely different life situations. Sixteen required fields is a lot. Sliders from 1 to 5 need precise framing language to feel like genuine self-reflection rather than bureaucracy. Getting that balance, enough fields for the model to work, few enough for a user to complete without disengaging, required constant iteration on wording and grouping. Defining the LLM’s exact role. The temptation at every stage was to let the language model do more: adjust scores based on its own reasoning, select the top option, infer additional profile fields from free text. The LLM’s role had to be precisely bounded, explainer, or the auditability of the whole system collapses. Writing system prompts that reliably held that boundary took more iteration than expected. The model has space for many more sub-metrics, HEXACO subscale decomposition, scenario clustering, multi-step path planning.
Accomplishments that we're proud of
We have seven components, and for every score produced, the equation that it’s derived from (user’s input + parameters for the six psych variables) produces exactly that number. If someone wants to know why scenario B comes before scenario C, they can look at the scores and literally see why. That is really difficult to get right with personalisations. We are also delighted by the psych richness of the model. Six mental-health and social science frameworks have been translated into real variables that have specific math function properties. That you can find an optimal scenario scored at 79 percent for this user - with the identical skills and career level but a higher life balance priority - as opposed to someone else being evaluated at 58 percent for this same scenario? The warning engine is something we are genuinely proud of. A high-scoring scenario might still trigger a warning on balance issues or contra-indicated concerns; we’ve tried to be upfront about uncertainty where the model cannot quantify it (overload). It is responsible for warning you when a particular recommendation, despite scoring high in many dimensions, is actually a bad idea.
What we learned
The ultimate question to ask when building an AI advisory system is not "what should the AI say?" But "what should the AI not decide?" We found ourselves posing that question more than dozens of times during our build process, and time after time the answer was consistent: that decision belongs with the human user. Our entire system design-the decoupling of our scoring logic from our explanation logic, the hard coded model note, the manual human review-is the aggregate of countless such decisions. Psychology as a methodology, we learned, is only useful when translating it to concrete variables, not simply referring to it as our guiding principle. Prospect Theory isn't background literature - that's why we have a reversibility metric with a structurally defined negative reward; Conservation of Resources isn't a lofty abstraction, it’s the very reason behind our overload risk system and why it will always return an empty decision regardless of its perfect goal-match scoring.
Differentiation
A typical AI growth advisor (ChatGPT, a coached LLM, a journaling app with AI) operates as follows: the user describes their situation in natural language, the model generates a response from its training distribution, and the quality of that response depends entirely on the quality of the prompt and the model's general reasoning. There is no formal model of the user, no scoring, no way to verify why one option was suggested over another. The same question asked twice can produce different answers, as the system has no memory of what tradeoffs it implicitly made, while Assesta operates differently at every layer.
Before the language model speaks, a deterministic scoring engine has already ranked every scenario against the user's profile across seven independently weighted sub-metrics. The LLM receives a completed ranked output and is architecturally prohibited from altering it. A user who asks "why did this option rank above that one?" receives a numeric breakdown — goal fit, balance score, feasibility, readiness, style fit, reversibility, risk penalty — not a generated explanation that sounds plausible but cannot be verified. No general-purpose chatbot can produce this because it requires a formal user model and a formula.
The recommendation is personalised at the variable level. Two users with identical career goals but different life balance profiles receive different rankings for the same scenario because the balance score is weighted by importance minus satisfaction per domain, and those numbers differ. A scenario that improves career at the cost of relationships scores lower for the user who rated relationships high-importance-low-satisfaction than for the user who does not. This is not prompt personalisation. It is structural personalisation: the same formula, different inputs, different outputs.
Every scenario in the library carries domain-by-domain impact scores across all six life areas. The scoring engine surfaces a "relationships: −3" alongside a "money: +5" and weights both against what the specific user cares about. The warning engine additionally flags overload risk, critical area harm, and contraindicated concerns separately from the score, so they cannot be buried by a strong goal fit.
What's next for Assesta - AI Growth Advisor
The features listed below are not yet implemented but represent planned extensions to the system enabled by decisions taken now. Longitudinal check-ins. The current system models a person at a single point in time, but re-running intake every two to four weeks would create a time series of profile states. That would let the model detect drift ( declining energy, a worsening life domain, rising readiness ) and update scenario rankings automatically. The snapshot persistence pattern in decision_engine.py is already set up for this, since every result is stored with full profile context for later comparison.
Behavioural feedback loop. If users report back on scenarios they tried (what worked and what trade-offs were real ) the system gains ground-truth calibration data. The gap between predicted and experienced trade-offs becomes a signal for refining scoring weights, per user or across segments. This is the path from an expert-calibrated formula to a genuinely learning system.
Adaptive advisor language. The chat advisor now uses a fixed style, but interaction history could shape it over time: which follow-up questions users ask, which explanations they engage with, how much detail they prefer. Someone who wants structure gets a more structured advisor; someone who wants directness gets shorter, sharper responses. The language becomes a reflection of the relationship.
Sequential path planning. The current model scores scenarios in isolation, but it could chain them. If a user’s energy is too low for the top-ranked scenario, the model could flag a recovery scenario as a prerequisite, then recalculate the landscape after capacity is restored. A single recommendation becomes a sequenced roadmap.
Personalised scenario generation. The scenario library is currently global, but a future version could use an LLM to parse the user’s free-text context and explicit options field into structured scenario candidates, then score them deterministically. Users would get options that fit their actual situation, not a generic set. The schema already exists: schemas.py defines the 17-field contract a scenario must satisfy before entering the scoring engine.


Log in or sign up for Devpost to join the conversation.