-
-
Souvenir from the AWS Habana Hackathon
Inspiration
Automatic Speech Recognition is very important in daily life. It is a multidisciplinary domain, as it uses tools of computer-vision to generate sequences of characters as in NLP.
A speech wave file is not only what we listen to.
What it does
The Model aims to recognize speech from wave files. It uses a Deepspeech network and converts sound to images to sequence of characters.
How we built it
I used many codes using Deepspeech, some could not be compiled, due to code breaking of the habana framework, others had more advanced features. namely three tentatives :
- https://github.com/SeanNaren/deepspeech.pytorch.git : based on hydra -pytorchlightning
- https://github.com/mozilla/DeepSpeech.git : uses older version of tensorflow, and did not compile well on HB platform
- https://github.com/jiwidi/DeepSpeech-pytorch.git : modified, running on local machine without torchaudio dependencies, but some errors occur in EC2-DL1 machine (inside hb docker )
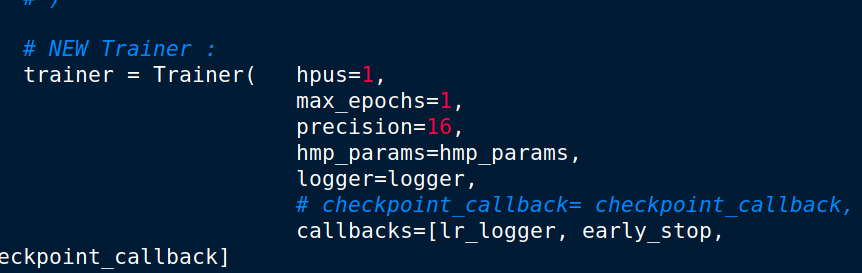
My adapted Code : https://github.com/mbencherif/DeepSpeechHB.git
Challenges we ran into
- Many code breakings, most of them solved.
- Documentation not available to go straight forward to code porting
- Cost of the machine, 13$/hour..
- Working on two systems, cuda platform on my computer, (RTX3090+ Threadripper ) and working on EC2-DL1, totally another world of magic.
Accomplishments that we're proud of
- Modified the torchaudio to work on EC2-DL1- machine with actual framework, which is not possible with actual HB framework.
What we learned
A ton of things, but it is good to learn management of stress and time. :)))
What's next for ASR on Gaudi Processors
Built With
- pytorch
- pytorchlightning


Log in or sign up for Devpost to join the conversation.