-
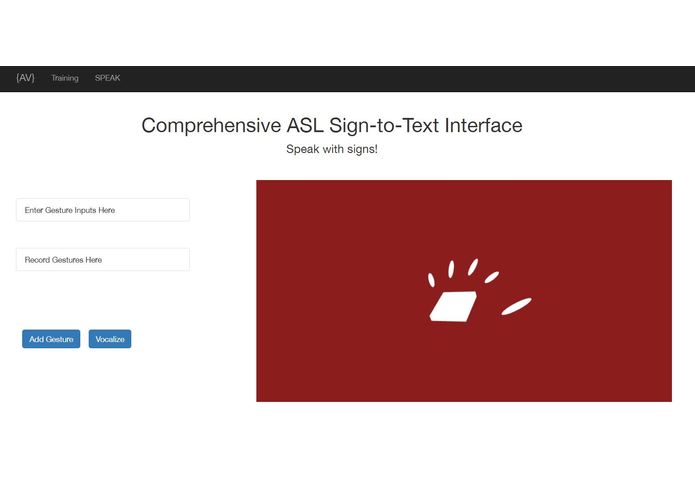
Main page.
-
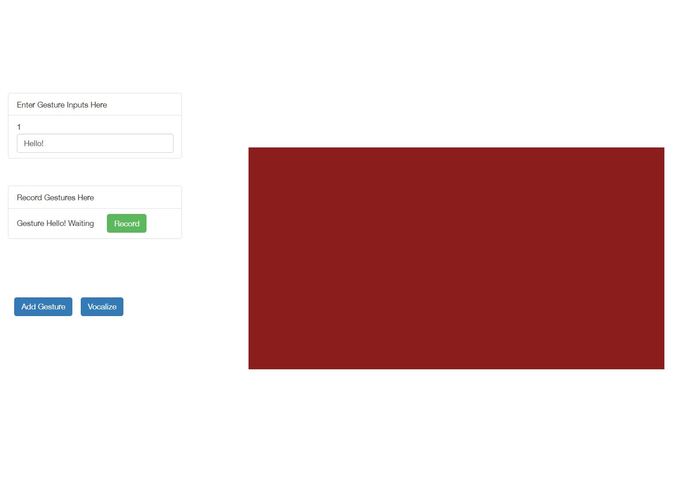
Recording a new sign.
-
Leap motion configuration.

Inspiration
Starting from a conversation about how the Amazon Echo couldn't be used by individuals suffering from muteness, we developed our idea for a sign language translator somewhat backwards. First, we thought about how these individuals communicated in public. Currently, there exist several ways. While it is possible for them to write down their thoughts for others to read, this is a rather impersonal and utilitarian approach to communication. Nonetheless, it does work. The primary mode of communication for such people, however, is ASL, the American Sign Language. An immensely popular mode of communication among mute and otherwise verbally-impaired individuals, the language remains surprisingly unknown to the majority of people who can speak, creating a hidden language gap between the able and the unable. Our ASL Sign-to-Speech interface aims to be the first step at bridging this gap, helping the verbally impaired become more intrinsically connected to the world around them.
What it does
Our interface allows users to record and/or train any number of signs and store them locally. As each gesture is saved, it now also becomes recognizable, and the web app will start to begin verbalizing the letter or phrase as it is performed. When the application receives sufficient data, it is possible to form words from letters and sentences from words, given practice. The words each gesture are assigned to are readout twice over- once through the computer's speakers and once through a connected Amazon Echo. Of the two, it is clear Echo's text-to-speech sounds better, but we didn't want to deny people without the Echo the opportunity to use our app as well.
How I built it
We started from either end of the project, my partner starting from looking into text-to-speech development for the Amazon Echo, and I looking into developing a front-end and interpreting signs from the Leap Motion. Turns out using the Echo to take text as input from the front-end interface and speak it was a lot more challenging than we anticipated, and we ended up needing to learn new things about stuff like server accessibility and cross origin resource sharing.
Challenges I ran into
Relatively little documentation, libraries, and utilities exist for both the Leap Motion and the Amazon Echo, so our development process with the two was far slower than it would normally be with more established technologies. Development was not as simple as raiding StackOverflow for answers, and there were several times in the process where we had to fully debug our software and/or scrap copious amounts of code.
Accomplishments that I'm proud of
Dynamic generation of new elements on the webpage and use of those elements with actions in javascript to store gestures. This allows us to accommodate for a substantial number of gestures/poses, rather than creating a fixed and more limited setup.
Loading a WebGL output from the LeapMotion, processing it with LeapTrainer.js, and positioning it in an iframe on the site. The result makes recording gestures relatively easy.
Getting the program to generate downloadable log files.
Using a High-Resolution subclass from the LeapTrainer library that enabled HitThresholds (accuracy of picked up gesture) to be set lower while simultaneously increasing overall accuracy.
What I learned
We learned how to develop for the Leap Motion, and how to use our Amazon Web Services accounts much better than before. We also learned how to develop, implement, and deploy servers that we could send and retrieve info from with the Amazon Echo. In coding this project, we were also able to learn more about how to carefully debug applications that use javascript, as this was a crucial but also limited part of our project.
What's next for ASL Sign-to-Speech Interface
For now, the ASL Sign-to-Speech Interface would work best as an app run in the background of a computer. In public places, those with speaking disabilities would be able to verbalize with others, resulting in a perhaps more natural conversational experience. However, the accuracy and portability of the system can be improved quite a bit. Firstly, a larger set of examples of signs could be used as training data for one potential application of machine learning here. This way, minor differences in the execution of signs would affect the end results less than they do in the application's current state. Another big change we could make is to put the application on mobile devices, at which point the application's practicality would take a huge leap. Individuals who formerly couldn't speak might even be able to have a phone call with others. Furthermore, they could always be able to switch to speaker mode to talk to others face to face.
The application also carries inherent educational purposes, like training students in ASL, that could be more fully explored in the future as well.

Log in or sign up for Devpost to join the conversation.