-
-

-
-
-

-

-

View our video to see how our application works!
-






Mudra AI: Translating Motion to Voice
Overview
Mudra AI is an intelligent American Sign Language (ASL) translation system that bridges communication between Deaf/Hard-of-Hearing and hearing individuals.
It combines computer vision, gesture recognition, natural language understanding, and speech synthesis to convert ASL gestures into real-time English text and expressive voice output.
Inspiration
This project was inspired by a personal connection. One of our team members has a close friend who is Deaf, and learning ASL was transformative in building that friendship.
However, we realized that not everyone has the opportunity or time to learn sign language — making communication difficult for many in daily life.
Mudra AI was built with a simple but powerful goal:
To give ASL users an instant “voice” and enable natural, inclusive conversations powered by AI.
How We Built It
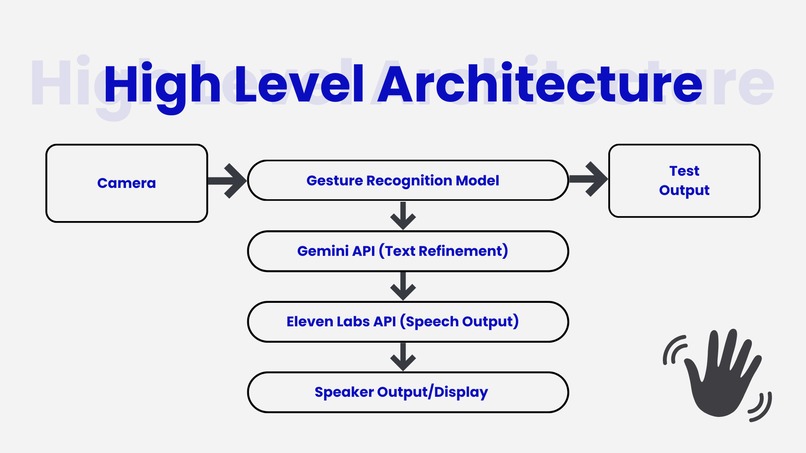
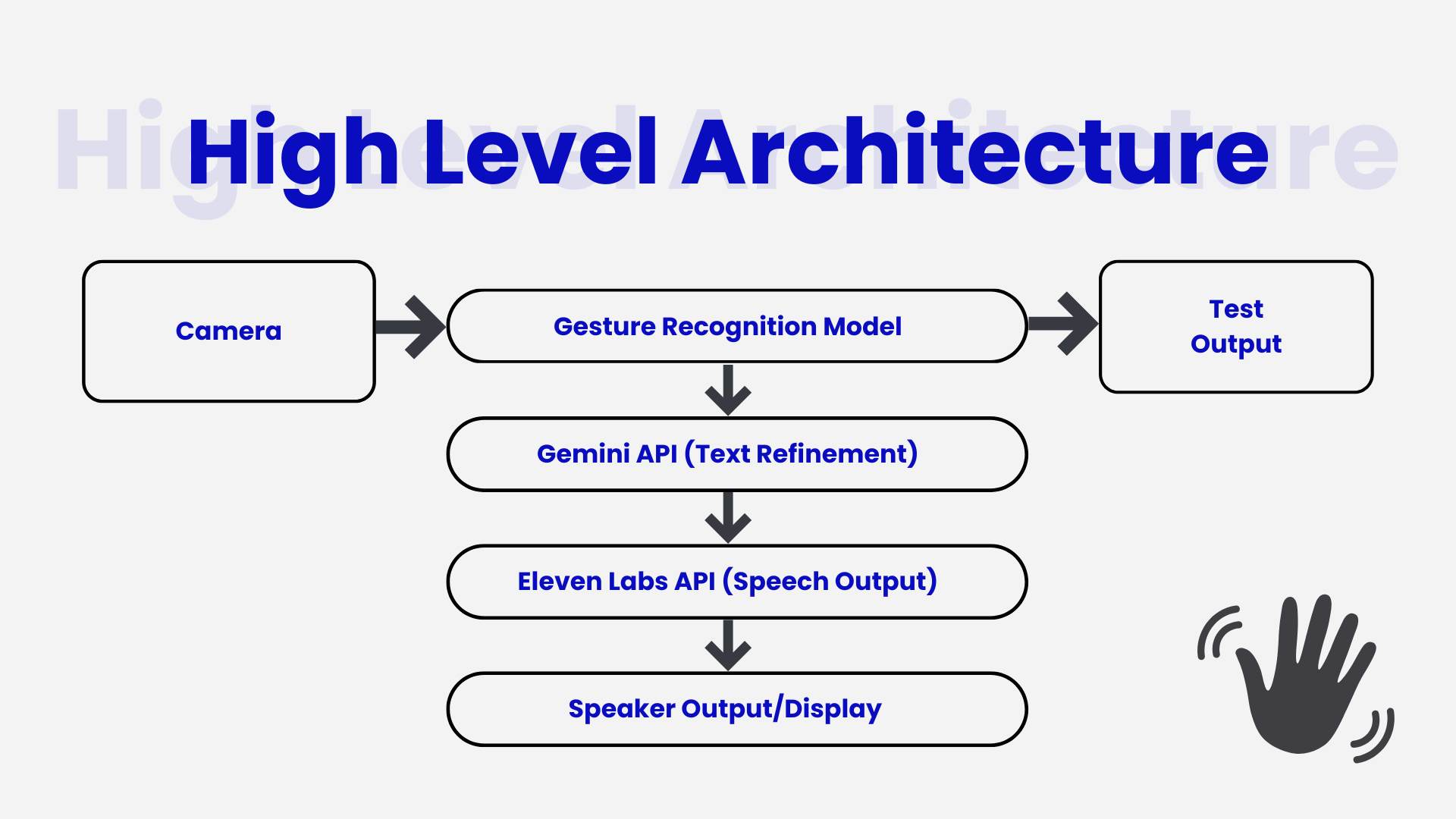
We designed Mudra AI around a layered architecture that integrates multiple AI components seamlessly:
1. Gesture Recognition Layer (Computer Vision + ML)
- Utilizes MediaPipe Holistic to extract hand, arm, and pose landmarks in real time.
From each video frame, we identify 144 unique numerical features representing both arms and hands combined:
- 63 features from the left hand
- 63 features from the right hand
- 18 features from upper-body pose (arms and shoulders)
- Total: 144 features per frame
These features are fed into a TensorFlow-based LSTM model trained on ASL gesture data to recognize letters and short signs.
2. Language Refinement Layer (Gemini API)
- The raw recognized sequence (e.g., “I LIKE COFFEE”) is sent to Google’s Gemini API.
- Gemini refines it into fluent, grammatically correct English (e.g., “I’m going to the store.”).
- This layer bridges ASL syntax and English grammar, producing natural, readable text.
3. Voice Output Layer (ElevenLabs API)
- The refined text is passed to ElevenLabs Text-to-Speech, which generates expressive, human-like speech in real time.
- This gives the ASL user a clear, natural-sounding voice for communication.
4. User Interface Layer (Streamlit UI)
- Displays the live camera feed, recognized signs, translated text, and plays generated speech instantly.
Challenges We Faced
Building Mudra AI was both technically and creatively challenging. Here are the major hurdles we overcame:
1. Lack of High-Quality 3D ASL Datasets
- Most open-source ASL datasets are 2D, optimized for static hand poses, not dynamic motion.
- These datasets fail to capture depth and motion—essential for gesture-based communication.
- To overcome this, we collected our own ASL dataset covering letters and basic gestures.
- However, we recognized that achieving full ASL fluency requires a much larger and more diverse dataset.
2. User Noise and Background Interference
- In real-time webcam input, MediaPipe sometimes detects multiple hands or faces in the background.
- We needed a model that could focus solely on the active user.
Our solution:
- Confidence thresholds to validate true detections
- Temporal smoothing for stability
- Landmark filtering to remove random noise and irrelevant movement
This significantly improved recognition accuracy and user focus.
3. Model Training and Accuracy
- With limited data, our goal was to build a model that generalizes well across users with different hand sizes, lighting conditions, and signing speeds.
- We used our own custom data so we had to learn ASL on the fly and trying to match the best we can to get the more accurate fingerspelling landmarks, but this would obviously introduce human error as this is not trained by 100% stable ASL configurations.
We applied:
- Normalization and data augmentation
- LSTM-based temporal learning for sequential gestures
These techniques helped the model learn motion context rather than just static frames.
4. Latency and Real-Time Inference
- The pipeline required multiple steps: gesture detection, API calls (Gemini + ElevenLabs), and audio output — all in real time.
We reduced latency by:
- Using TensorFlow Lite for fast inference
- Offloading non-essential computations
- Streamlining data flow between modules
What We Learned
Through building Mudra AI, our team learned how to integrate multiple AI disciplines into one cohesive system:
- How computer vision and landmark-based features can translate motion into structured data
- How language models like Gemini contextualize that data into human-like communication
- How text-to-speech APIs can restore accessibility by giving ASL users a literal voice
Most importantly, we learned how technology can bridge communities and promote inclusive communication.
What We're Proud Of
One of our biggest achievements during this hackathon was getting an entire Computer Vision → Machine Learning → LLM pipeline operational within 24 hours.
We weren’t sure if integrating gesture recognition, language refinement, and real-time speech synthesis would work this smoothly on a first prototype, but it did.
Seeing Mudra AI translate live ASL gestures into natural speech for the first time was a truly inspiring moment for our team.
We’re incredibly proud of how far this prototype has come in such a short time and are excited to expand and refine it, as there’s still a huge scope for improvement and innovation.
Future Work
Our roadmap for Mudra AI includes:
- Expanding our ASL dataset to include full words, phrases, and contextual sentences
- Implementing multi-user tracking with automatic background filtering
- Adding reverse translation — speech-to-sign for hearing users
- Developing mobile and wearable versions (smart glasses or AR integration)
- Introducing context memory for continuous, conversational flow
Vision
A real-time ASL-to-Speech translator that empowers inclusive communication — blending AI language models, computer vision, and expressive voice synthesis to help the world understand sign language naturally.


Log in or sign up for Devpost to join the conversation.