-

ASL Alphabet Detector Logo and Mascot
-
Original Design Idea
-
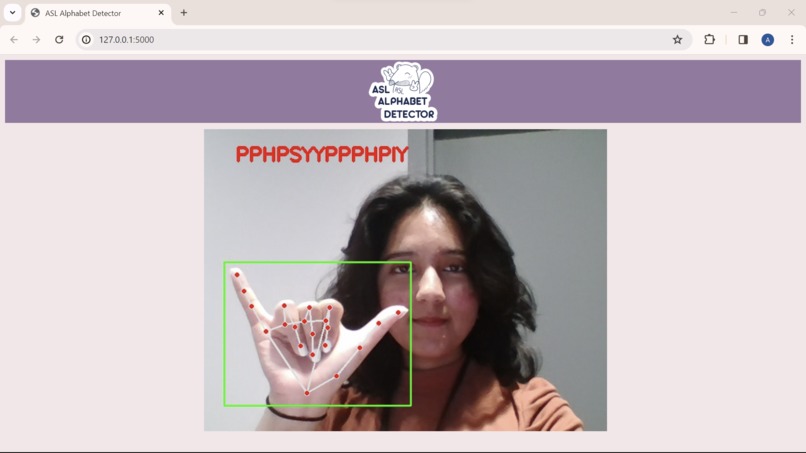
Working Project
-

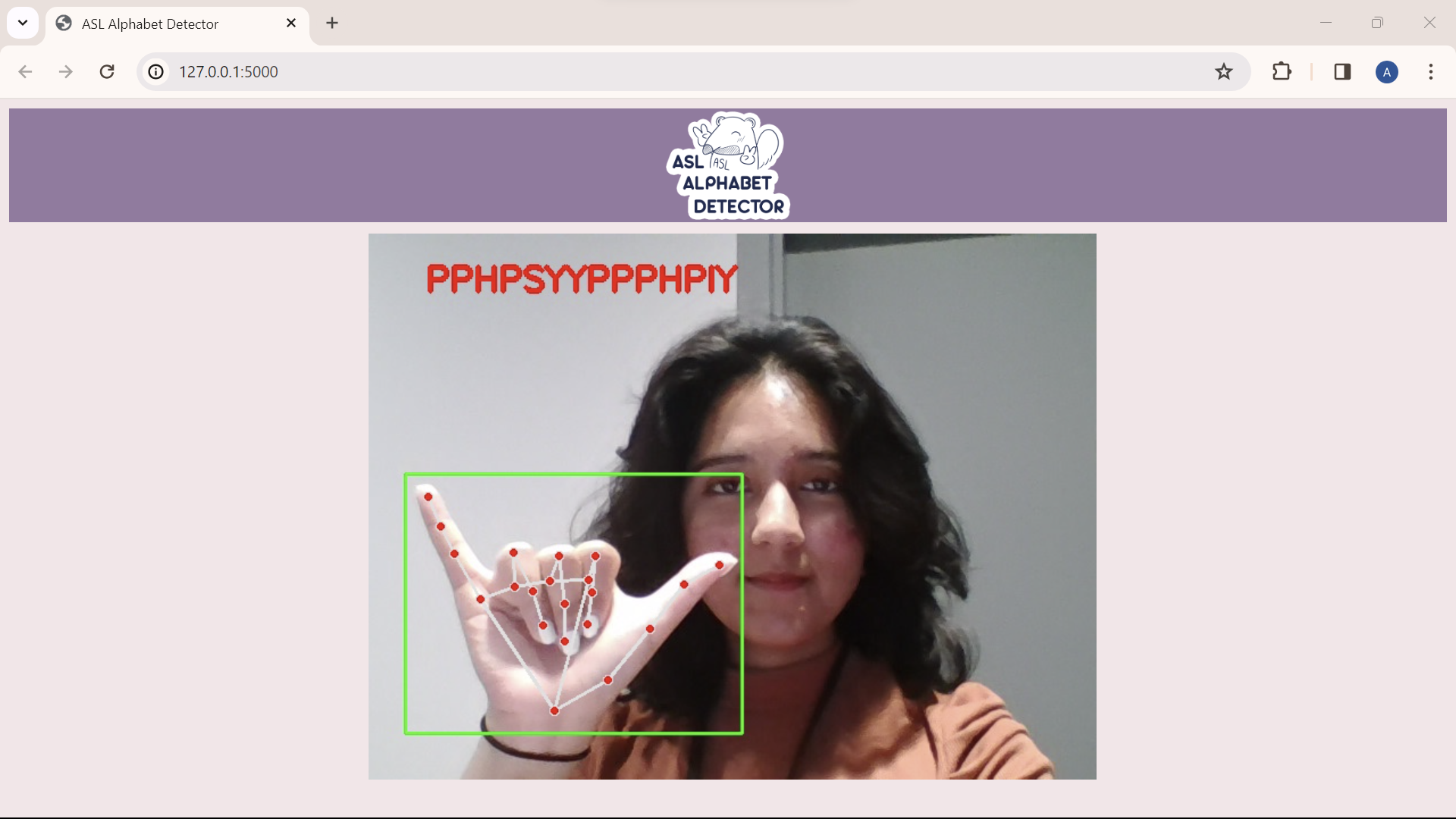
Processed Image


Inspiration
In an age of video streaming and video conversation, it is more important than ever to make sure that the tech space can be explored and navigated effectively by the folks in the American Sign Language (ASL) community. In order to communicate with those who don't know how to sign, ASL users often have to resign themselves to typing out their thoughts. However, doing so takes away from the expression and emotion that can be transmitted through video, defeating the purpose of using video transmission in the first place. We want to provide a synchronous transcription of ASL, in order to allow ASL users the joy of conversation afforded to their peers who can use their voice.
What it does
The ASL Alphabet Detector takes in real time video feed from the user's webcam and maps out hand gestures using computer vision. It then sends frames capturing a unique motion to the deep learning model and outputs the English letter it's most confident every 10 frame interval.
How we built it
First, we sourced the public 'Sign Language MNIST' dataset from Kaggle. We then created an image pipeline and trained our own Keras deep learning model on the different variations of hand positions in Jupyter Notebook. To take in live video feed, we integrated our trained model with the OpenCV library and abstracted the project into a user-friendly website in Flask.
Challenges we ran into
Although detecting ASL letters has been done before, transcribing live conversation has more room for exploration. As such, we went through a series of experimental phases, including frameworks for deploying a ML model on an app, libraries that were not compatible with our OS, the rate of prediction for footage, and displaying both video and text simultaneously in real time. None of us are proficient in ASL, so testing the model did not go as accurately as it could've. In addition, our model is limited in the sense that there's much more to ASL than just the alphabet, such as gestures and expressions.
Accomplishments that we're proud of
We trained a deep learning model with about 35,000 images (each 784 pixels long), achieving 99.6% training accuracy and 99.5% testing accuracy after 20 epochs using advanced optimization techniques. We were able to integrate the project completely, so we have a front-end that captures synchronous video feed, which is then processed before being sent to the model, ultimately returning letter data to the display. We also have the model hosted on IBM Cloud, available for public at this link through REST API.
What we learned
We learned that computer vision is a time-intensive but extremely fulfilling field to explore. None of us will forget the moment when we got the ML model to recognize our poorly done ASL live. Despite the many roadblocks we encountered, we never gave up and took moments to take a deep breath, reconvene, and pave a new path forward. We also made sure to take breaks during ebbs in our productivity flow to give our mind time to recover, which is an important skill to develop.
What's next for ASL Alphabet Detector
We'd love to implement three new main functionalities: expanding the ML model to include more complex ASL vocabulary, natural language processing (NPL) to predict full words, and a more robust integration with apps that use live image feed.



Log in or sign up for Devpost to join the conversation.