-
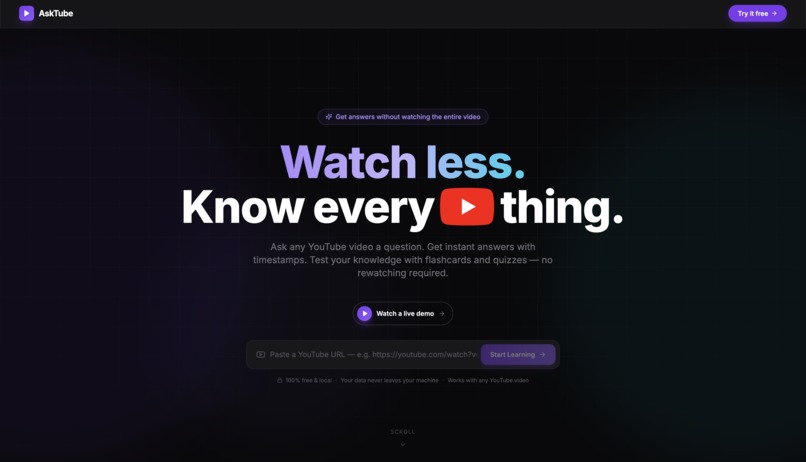
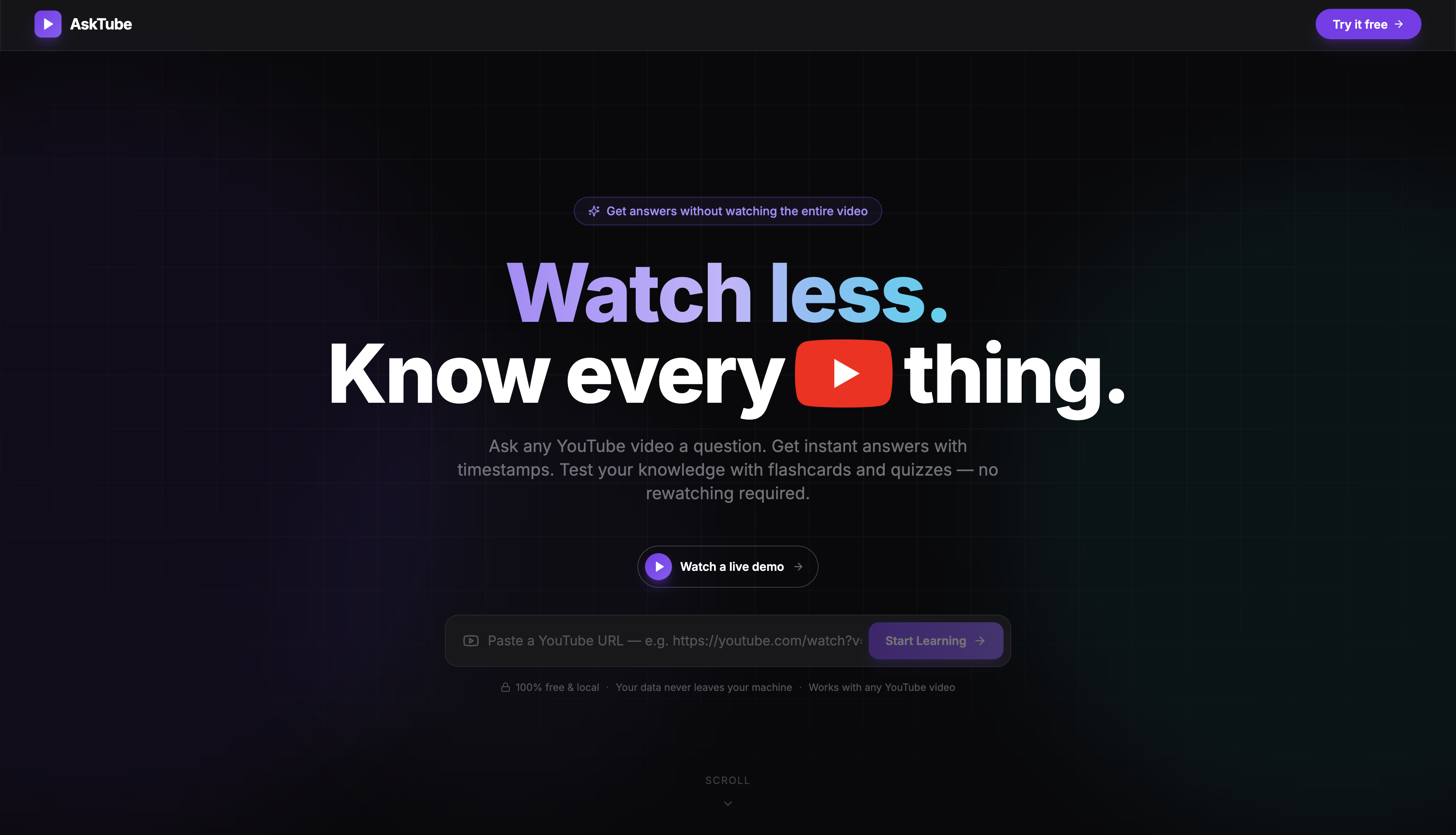
Home page 1
-
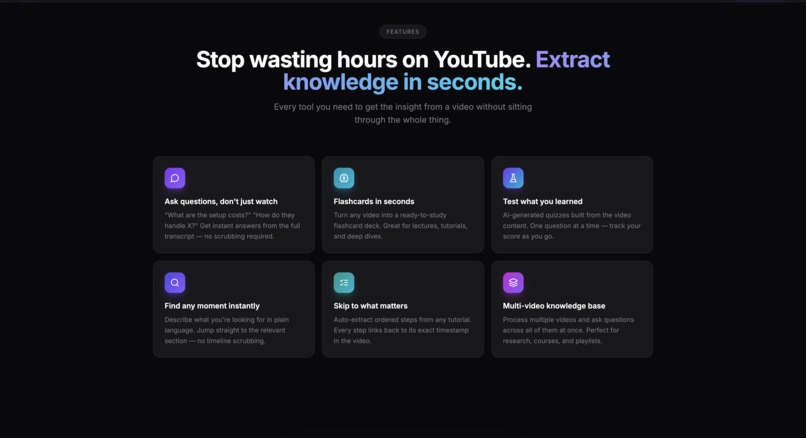
Home page 2
-
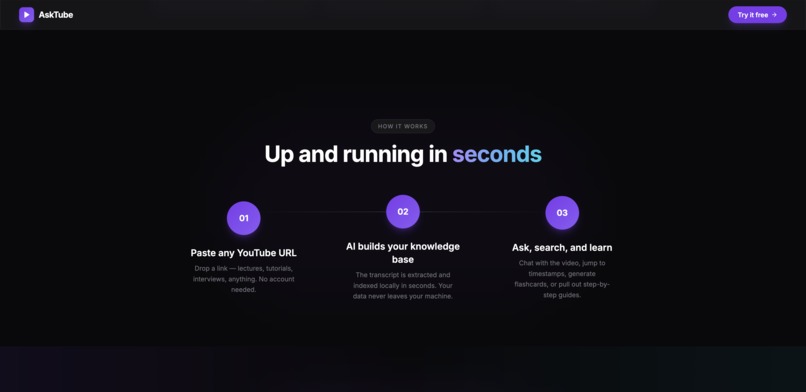
Home page 3
-
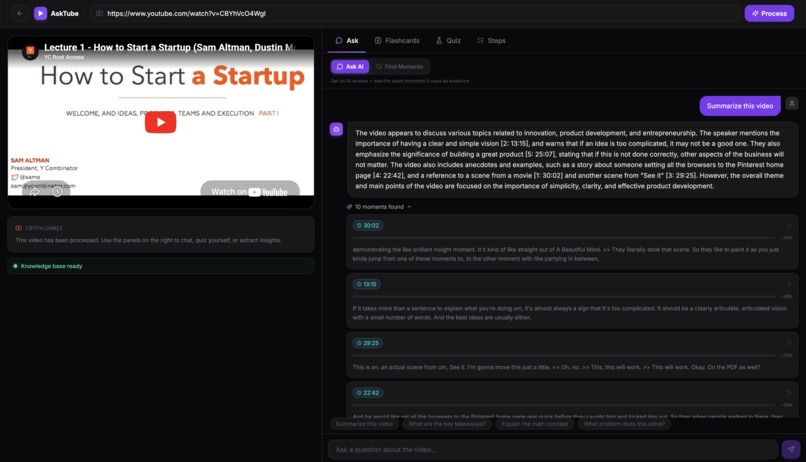
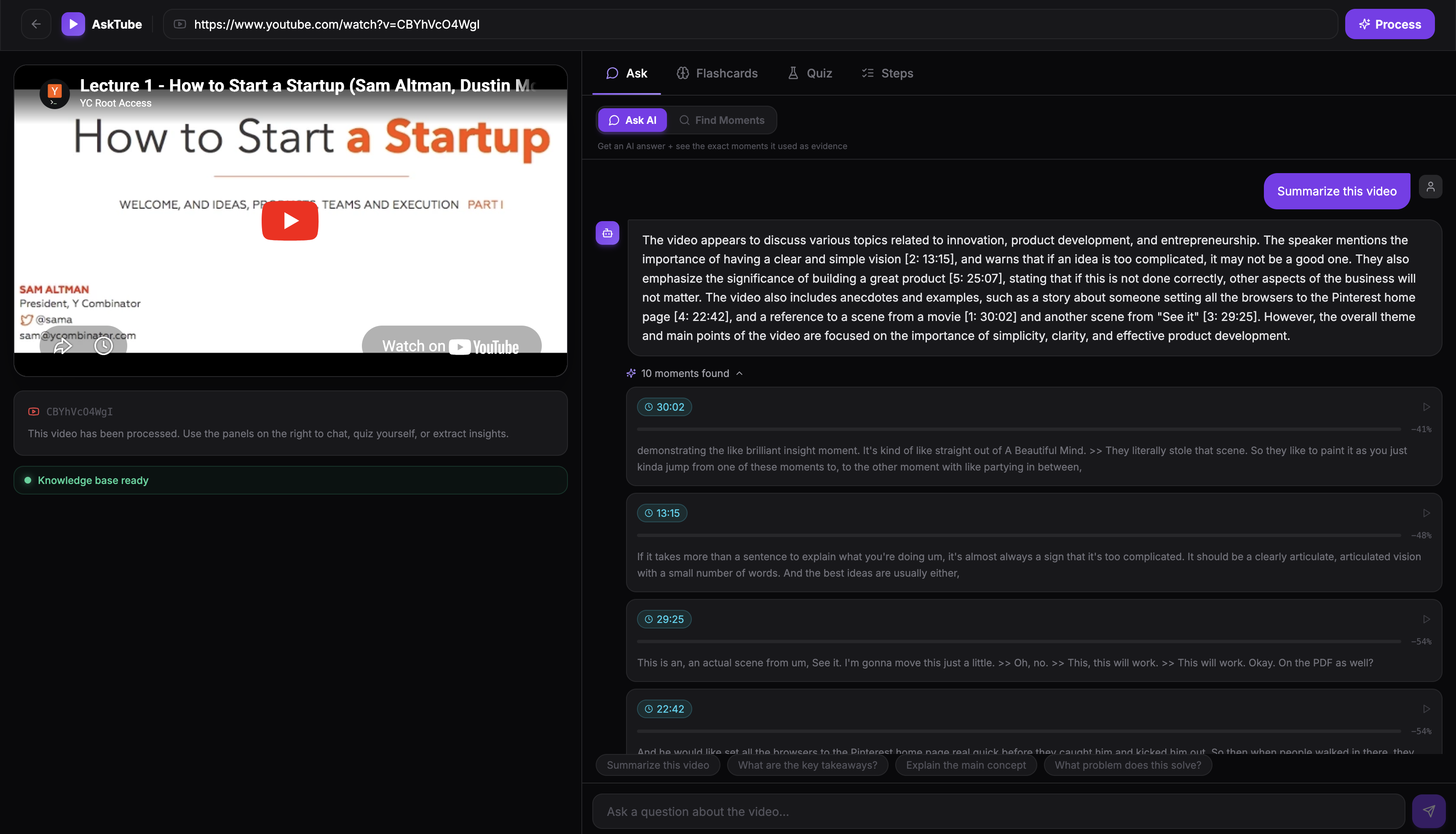
Summary of the video (and chat with the video)
-
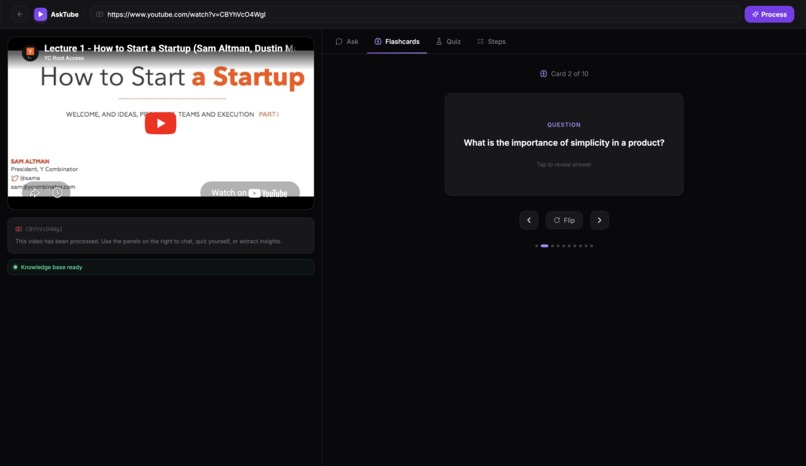
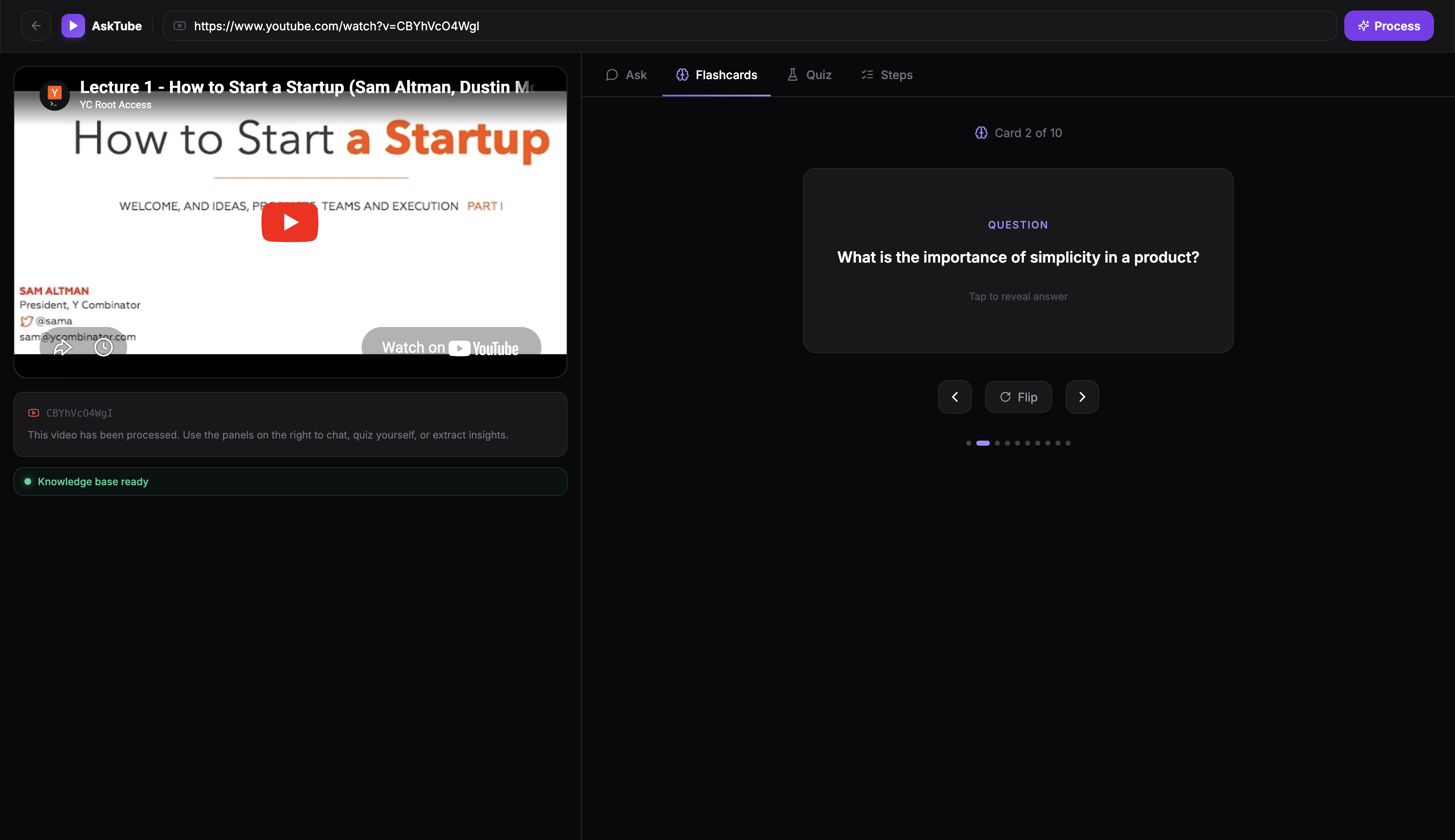
Flashcard generated based on the video
-
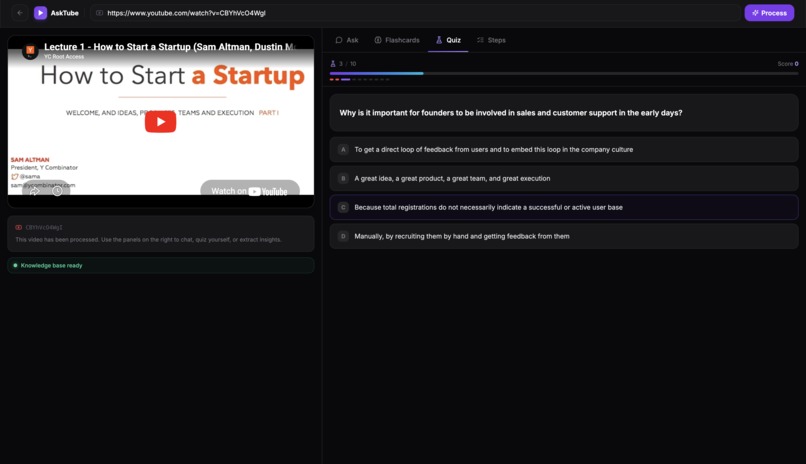
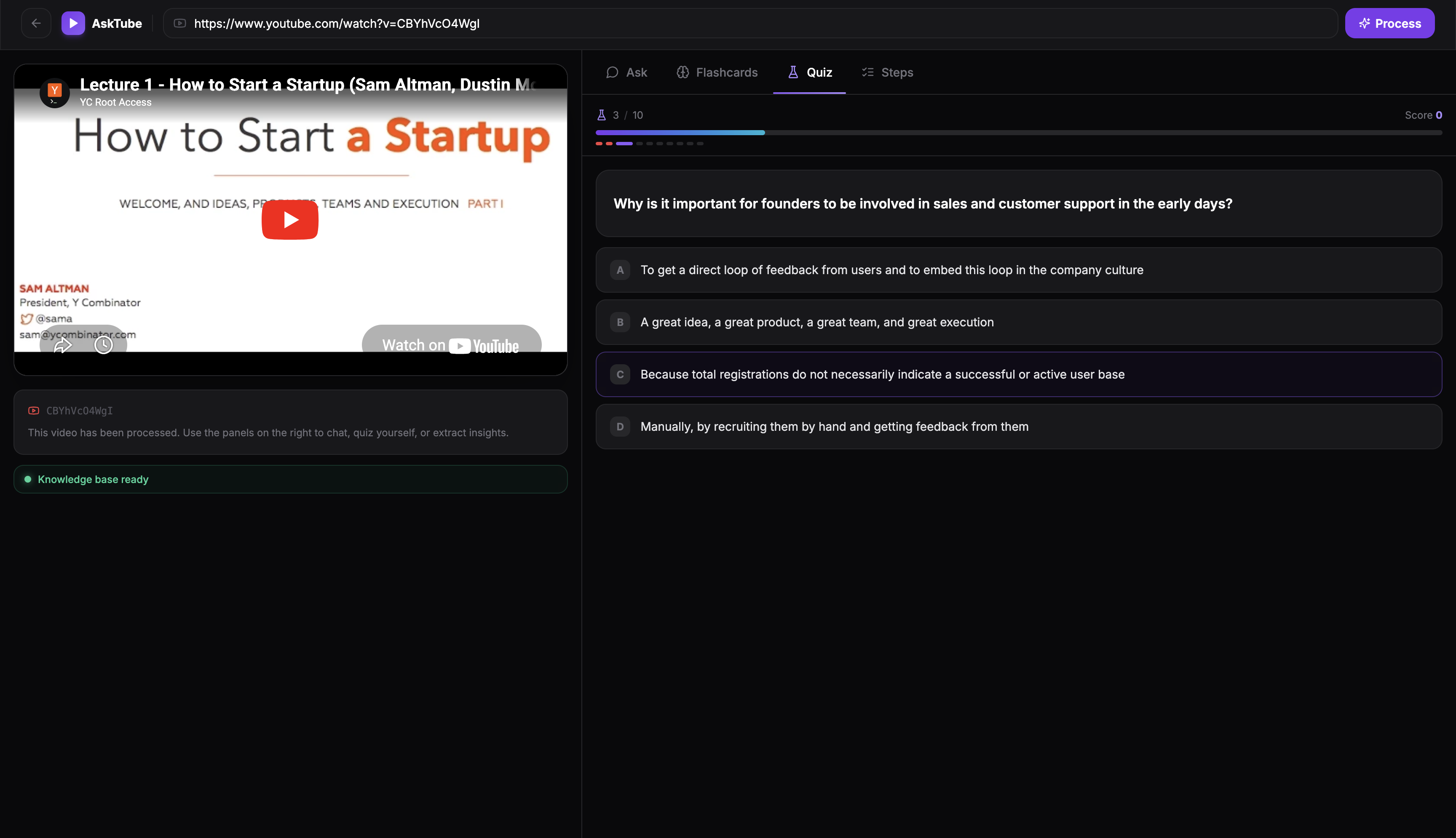
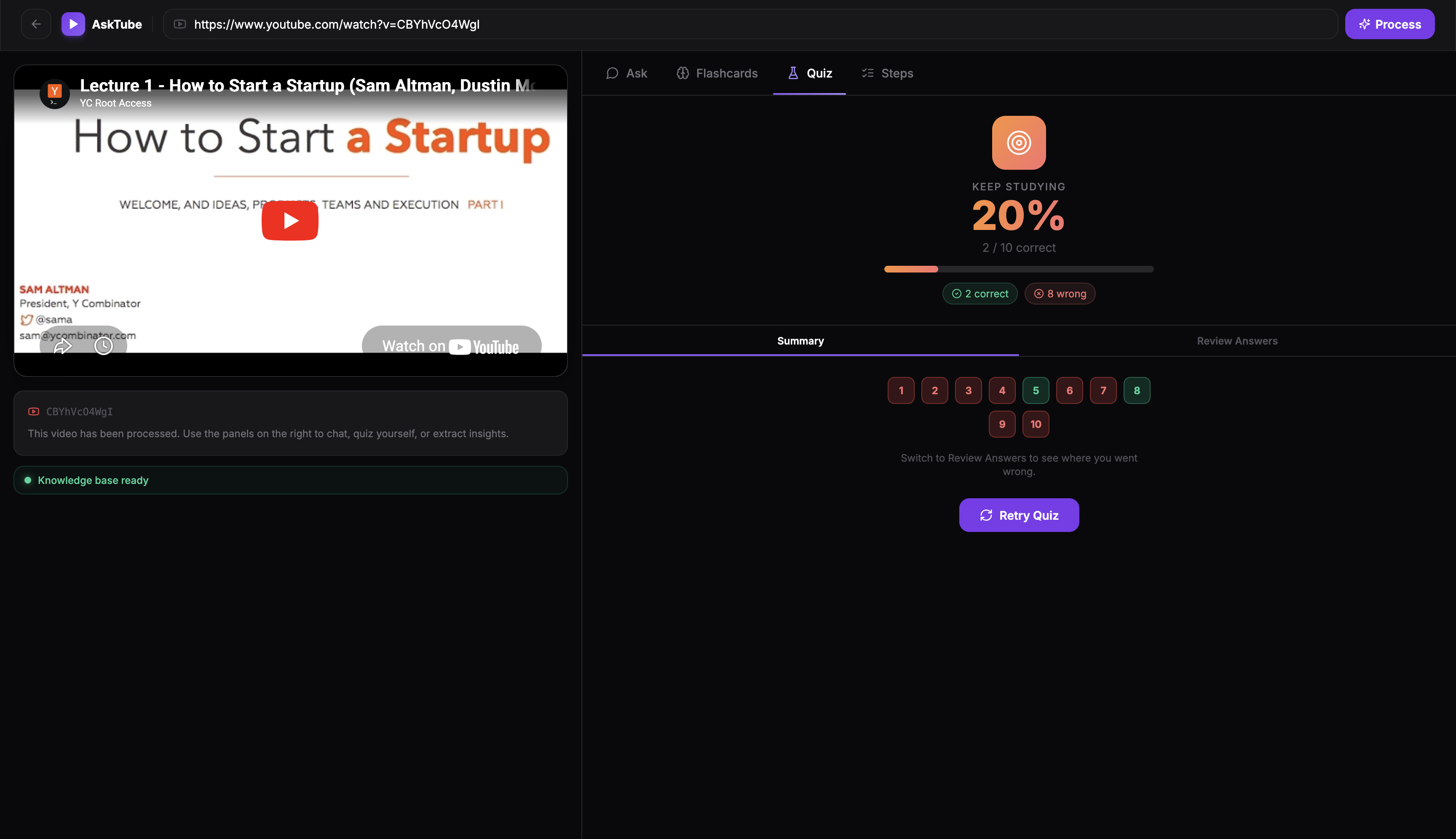
Quiz geenrated based on the video
-
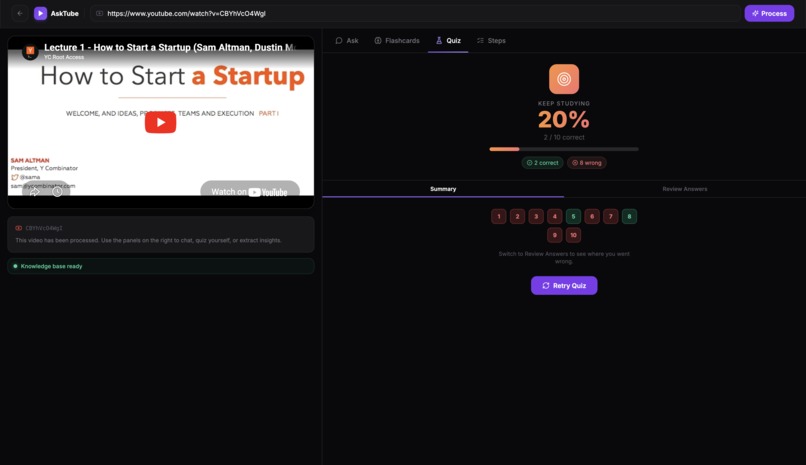
Quiz Results
-
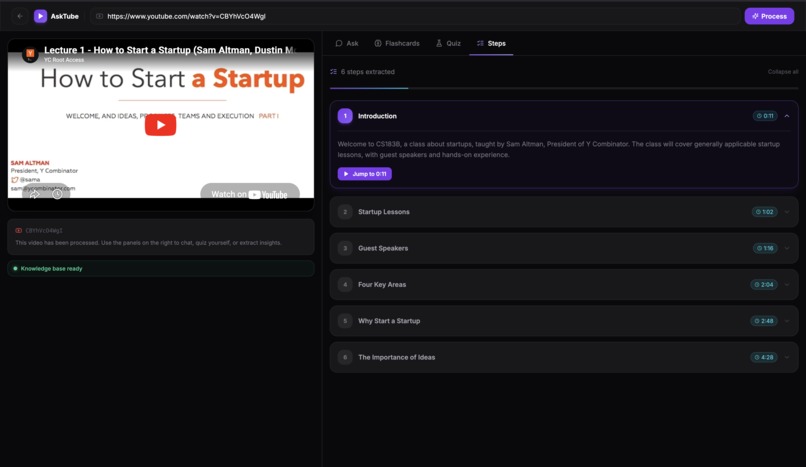
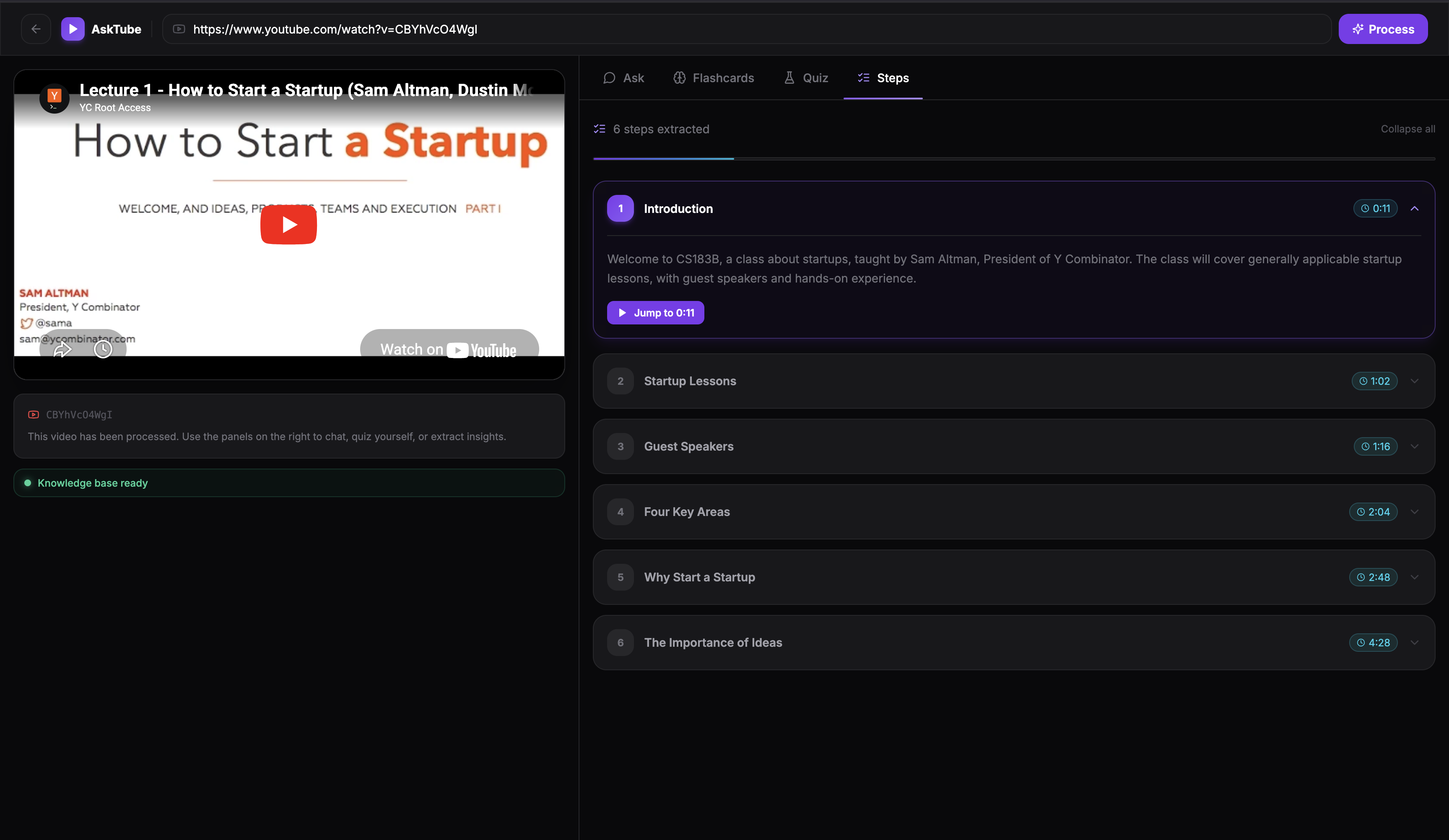
Chapers or Subsection of the video


## Inspiration
We've all been there: a 2-hour lecture, a dense tutorial, or a conference talk you need to understand — but rewatching it to find one specific answer wastes time you don't have. YouTube is the world's largest knowledge base, yet it lacks an advanced intelligence layer to test how much you’ve learned. AskTube was built to fix that.
## What It Does
AskTube turns any YouTube video into an interactive knowledge system:
- Ask AI — chat with the video and get answers grounded in exact timestamps
- Flashcards — auto-generated Q&A cards for studying and retention
- Quiz — test your understanding with instant feedback and a streak tracker
- Steps — extract ordered, actionable instructions from tutorial videos
- Multi-video KB — combine multiple videos into one searchable knowledge base (Next Iteration multiple video current version only supports 1 video)
## How I Built It
- Backend: FastAPI (Python) with a modular
services/routes/modelsstructure - LLM: Groq API (Llama 3.3 70B) for fast, free-tier inference
- Embeddings:
sentence-transformers(all-MiniLM-L6-v2) for semantic search - Vector DB: ChromaDB for storing and querying transcript chunks
- Transcript:
youtube-transcript-apiwith a manual paste fallback for blocked videos - Frontend: Next.js 14 + Tailwind CSS, designed to feel like a polished SaaS product
- Deployment: Render (backend) + static export (frontend)
The core architecture is a RAG (Retrieval-Augmented Generation) pipeline: transcripts are chunked, embedded, and stored in ChromaDB. On each query, the top-k semantically similar chunks are retrieved and passed to the LLM with the question — so every answer is grounded in the actual video content, not hallucinated.
## Challenges We Faced
- YouTube IP blocking: Render's shared IPs are flagged by YouTube, breaking automatic transcript fetching. We built a manual transcript paste modal that parses YouTube's native timestamp format as a fallback.
- Cold start on free hosting:
sentence-transformersv5 pulls in PyTorch (~2GB), which takes 30-60 seconds to import — long enough to fail Render's port-scan health check. We solved it by deferring all heavy imports inside lazy getter functions, so the server binds to its port instantly and warms up on first request. - Designing for clarity: Combining Chat and Search into one unified "Ask" panel without overwhelming the user required several iterations — we landed on a mode toggle with collapsible "moments" so answers stay clean.
## What We Learned
- How to build a production-grade RAG pipeline from scratch with open tools
- The importance of graceful degradation (manual fallback when APIs fail)
- How lazy initialization patterns matter in memory-constrained cloud deployments
- That good UX is a feature — a demo that feels polished wins as much as one that works
Built With
- chromadb
- fastapi
- groq
- llama-3
- next.js
- python
- pytorch
- rag
- react
- render
- sentence-transformers
- tailwindcss
- typescript
- vercel
- youtube-transcript-api

Log in or sign up for Devpost to join the conversation.