-
-
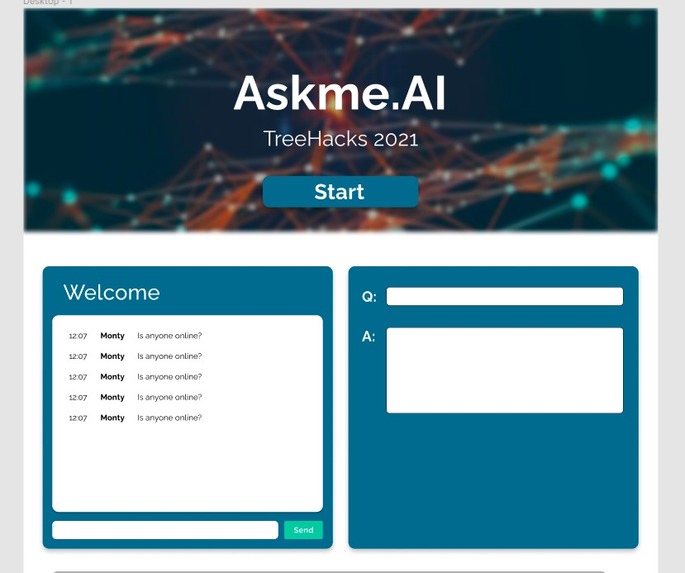
Web app UI
-

Predictions
-

Paper


Inspiration
Our inspiration for this project came from the issue we had in classrooms where many students would ask the same questions in slightly different ways, causing the teacher to use up valuable time addressing these questions instead of more pertinent and different ones. Also, we felt that the bag of words embedding used to vectorize sentences does not make use of the sentence characteristics optimally, so we decided to create our structure in order to represent a sentence more efficiently.
Overview
Our application allows students to submit questions onto a website which then determines whether this question is either:
- The same as another question that was previously asked
- The same topic as another question that was previously asked
- A different topic entirely
The application does this by using the model proposed by the paper "Bilateral Multi-Perspective Matching for Natural Language Sentences" by Zhiguo et. al, with a new word structure input which we call "sentence tree" instead of a bag-of-words that outputs a prediction of whether the new question asked falls into one of the above 3 categories.
Methodology
We built this project by splitting the task into multiple subtasks which could be done in parallel. Two team members worked on the web app while the other two worked on the machine learning model in order to our expertise efficiently and optimally. In terms of the model aspect, we split the task into getting the paper's code work and implementing our own word representation which we then combined into a single model.
Challenges
Majorly, modifying the approach presented in the paper to suit our needs was challenging. On the web development side, we could not integrate the model in the web app easily as envisioned since we had customized our model.
Accomplishments
We are proud that we were able to get accuracy close to the ones provided by the paper and for developing our own representation of a sentence apart from the classical bag of words approach. Furthermore, we are excited to have created a novel system that eases the pain of classroom instructors a great deal.
Takeaways
We learned how to implement research papers and improve on the results from these papers. Not only that, we learned more about how to use Tensorflow to create NLP applications and the differences between Tensorflow 1 and 2. Going further, we also learned how to use the Stanford CoreNLP toolkit. We also learned more about web app design and how to connect a machine learning backend in order to run scripts from user input.
What's next for AskMe.AI
We plan on finetuning the model to improve its accuracy and to also allow for questions that are multi sentence. Not only that, we plan to streamline our approach so that the tree sentence structure could be seamlessly integrated with other NLP models to replace bag of words and to also fully integrate the website with the backend.











Log in or sign up for Devpost to join the conversation.