-
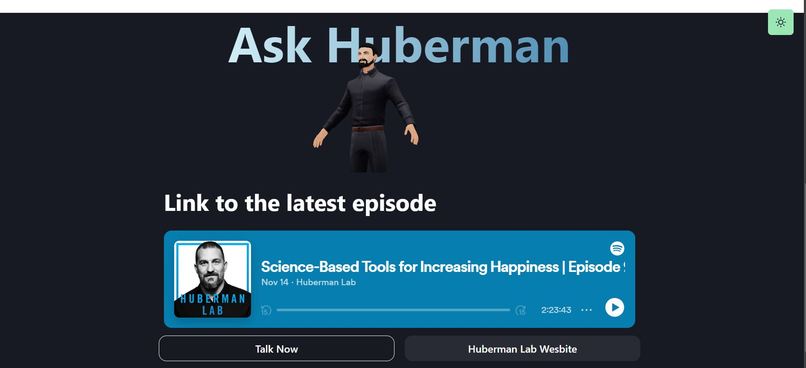
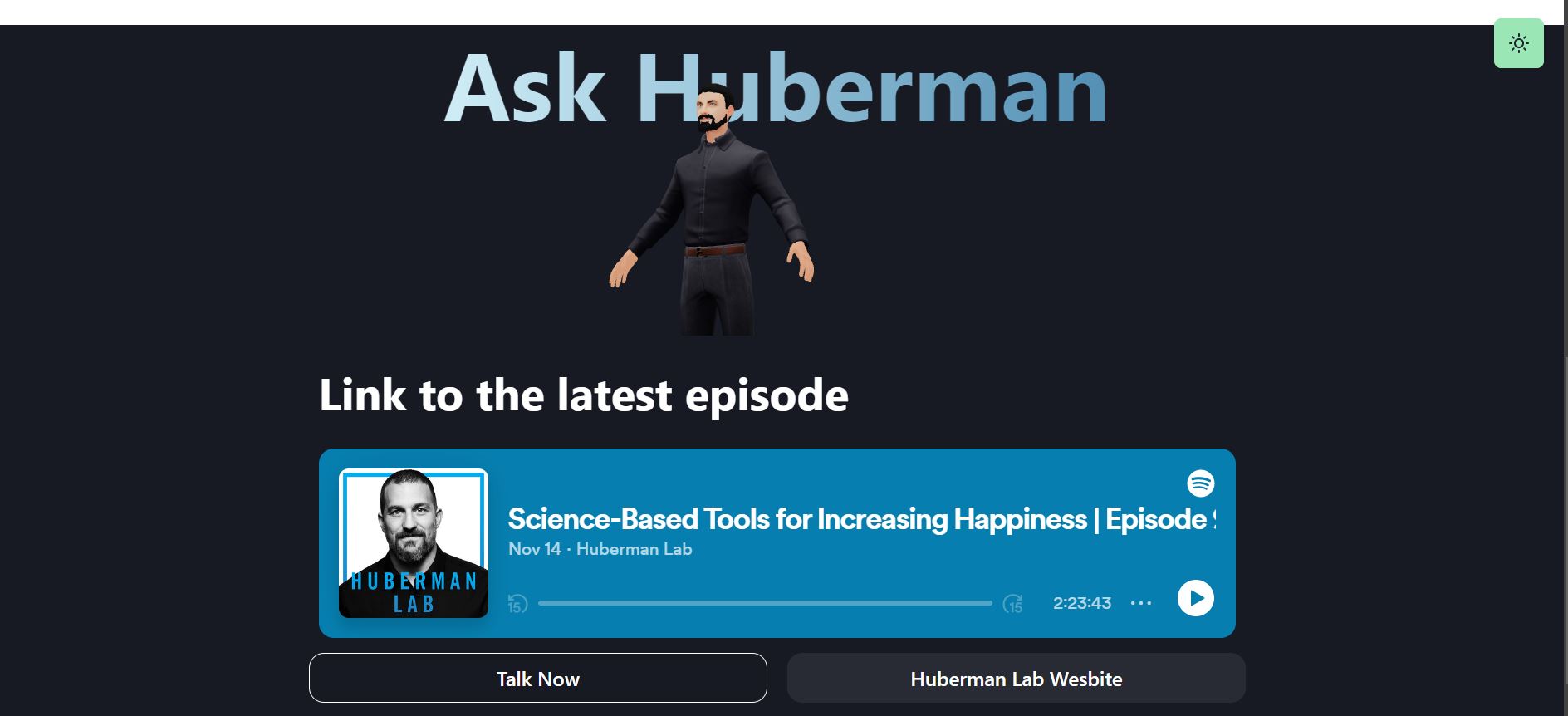
Landing
-

3d model
-
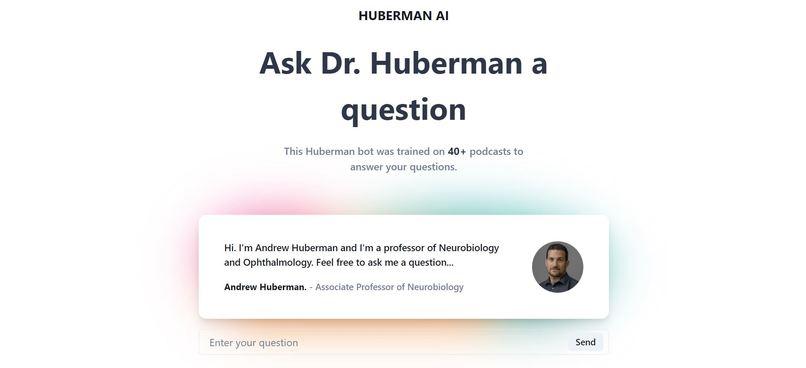
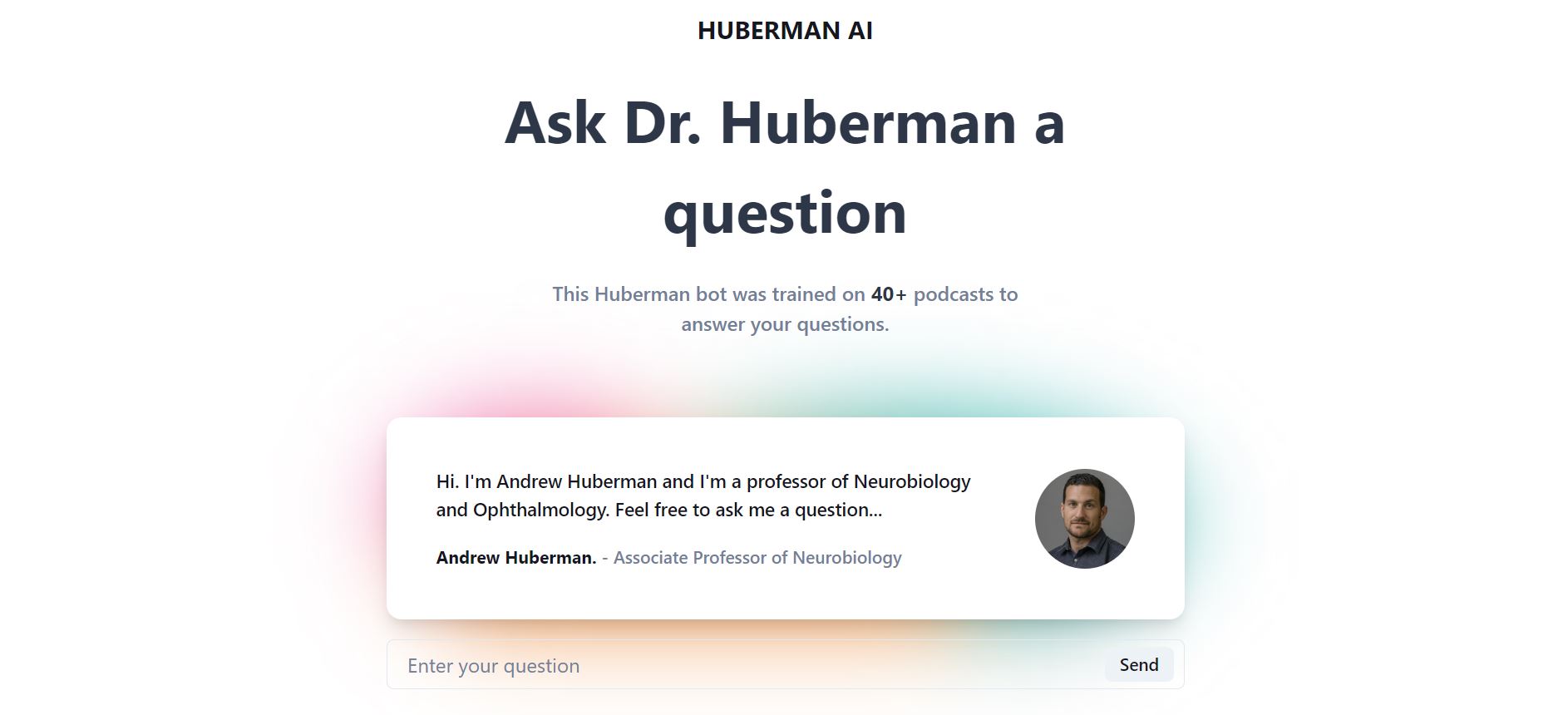
question asking state
-
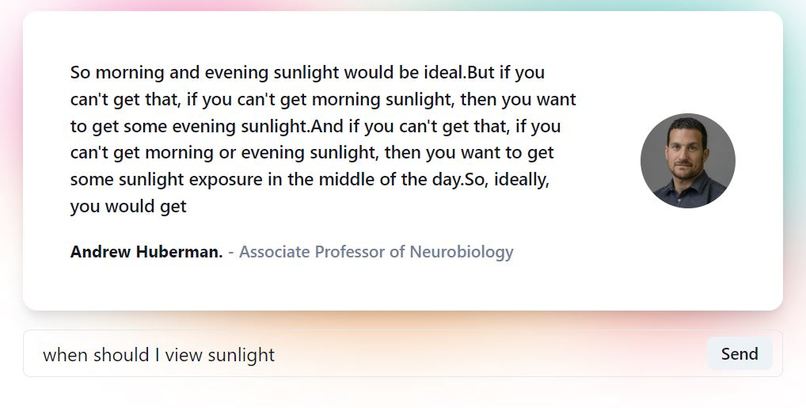
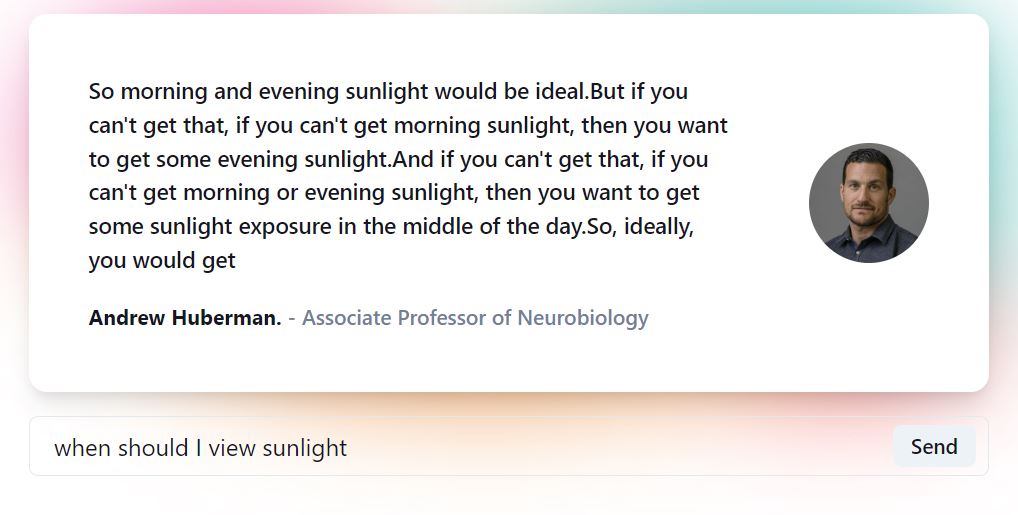
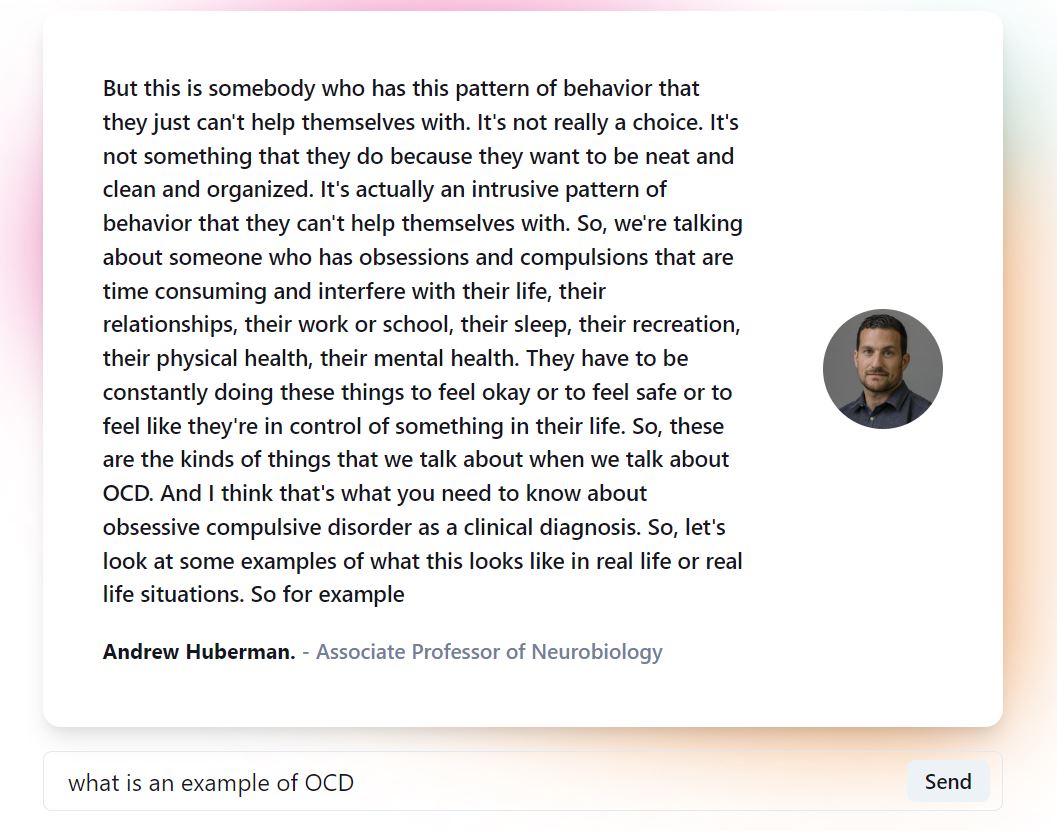
Response example (1/3)
-
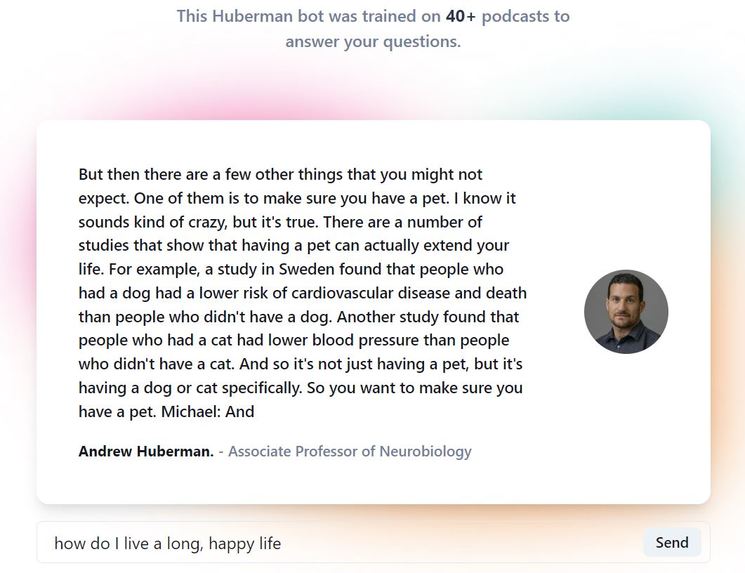
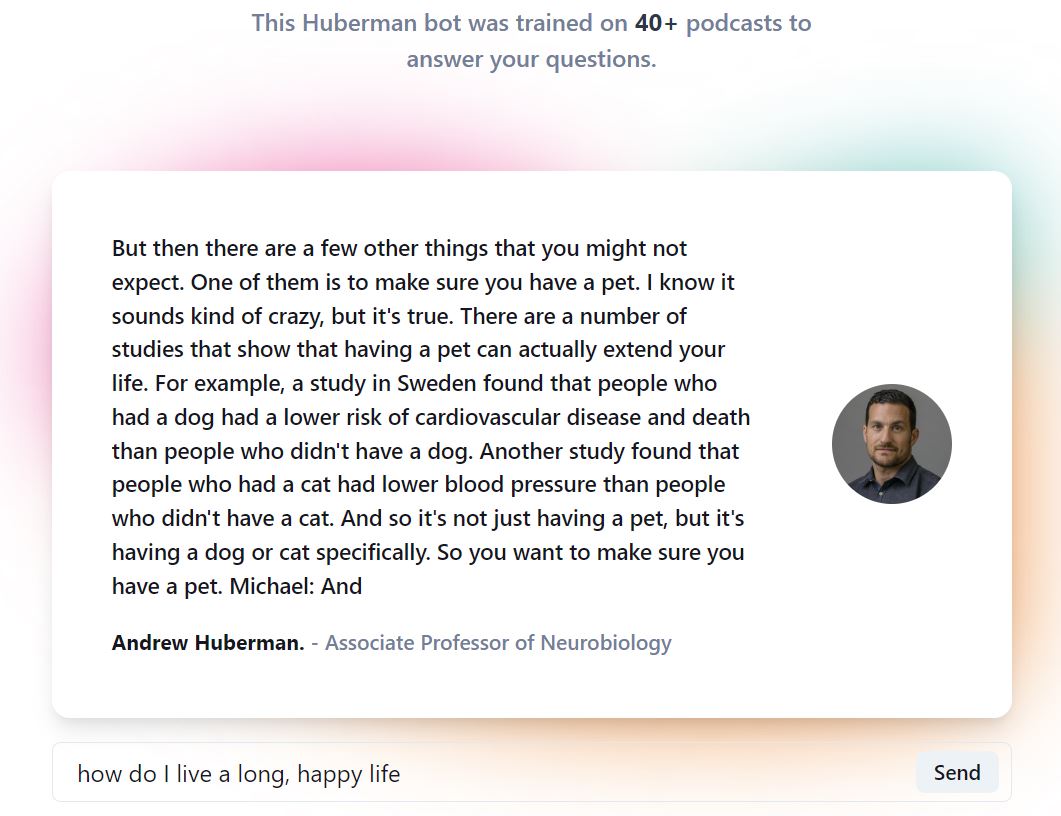
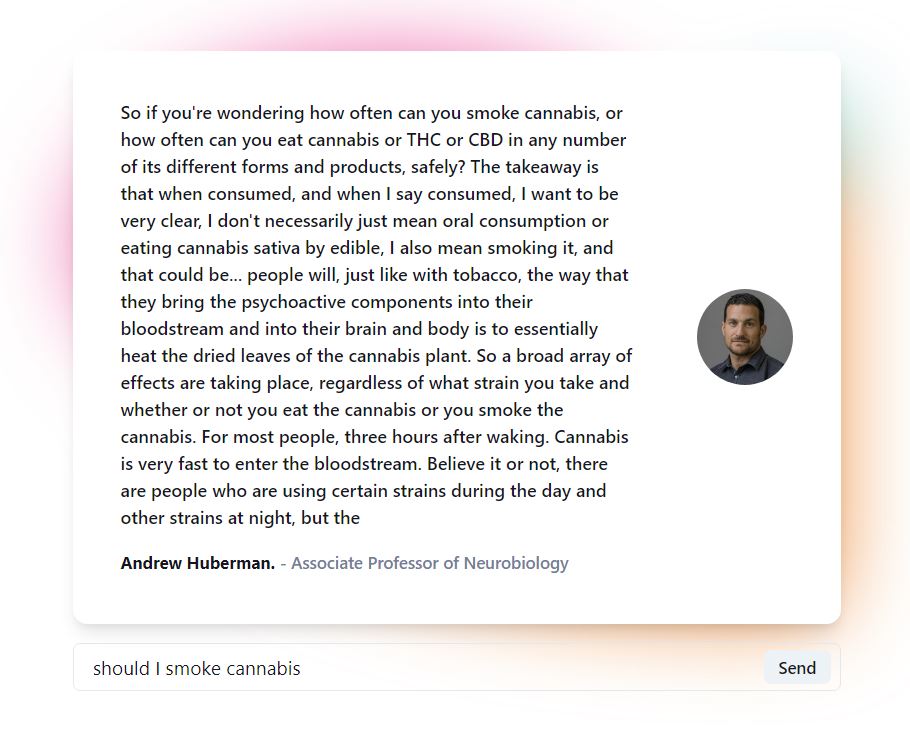
Response example (2/3)
-
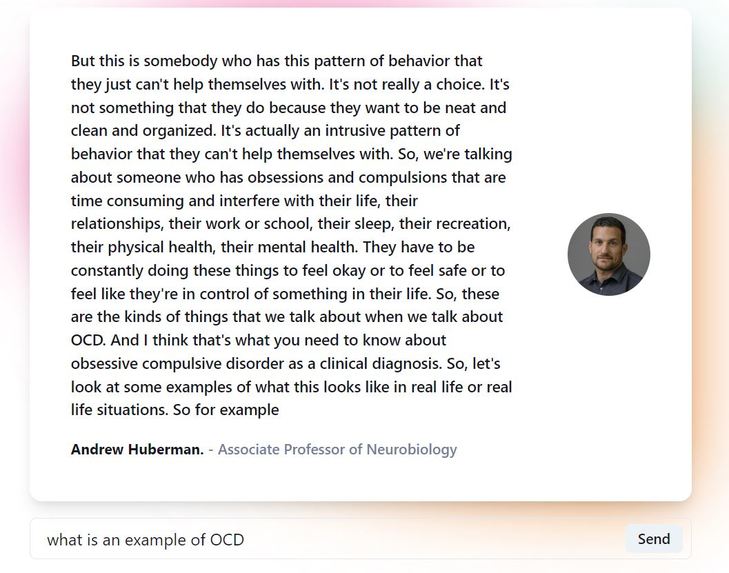
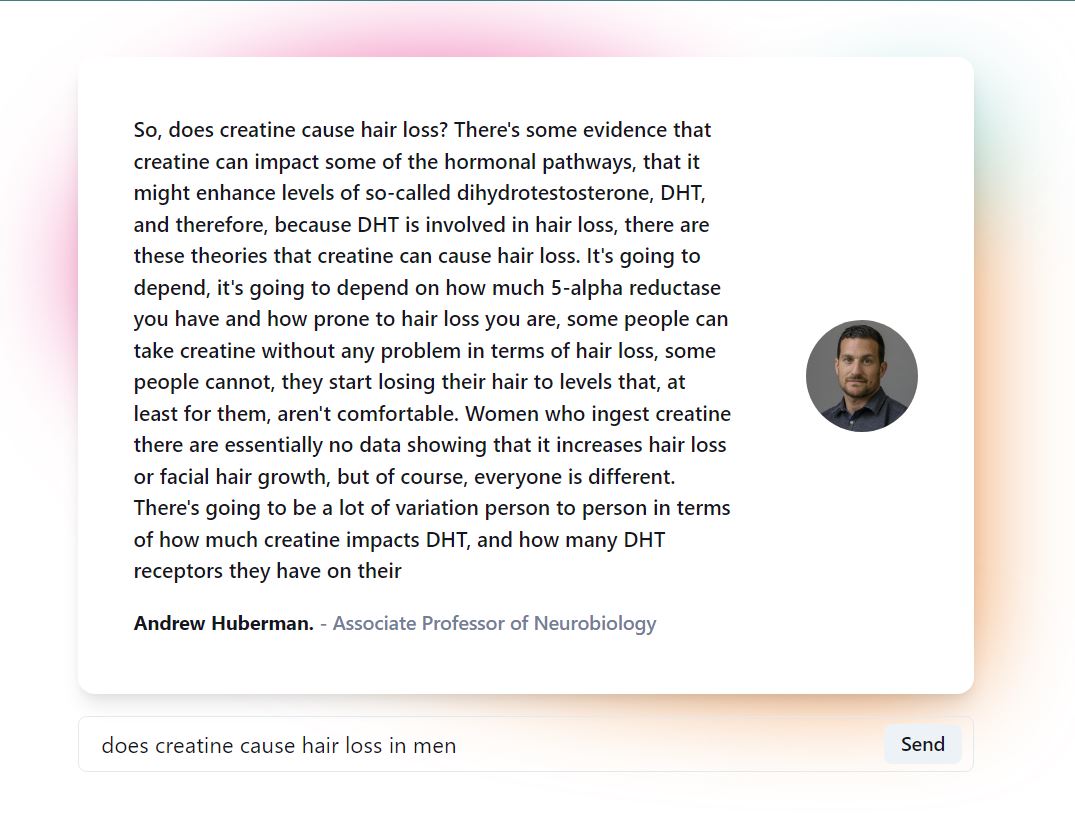
Response example (3/3)
-
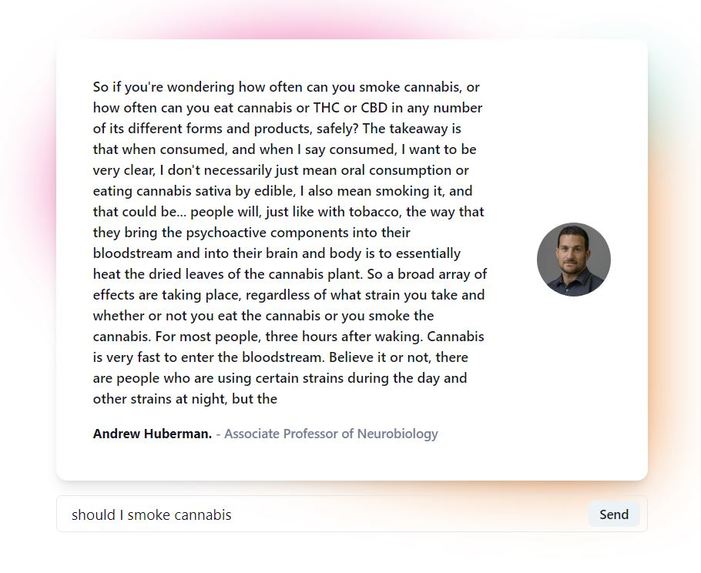
-
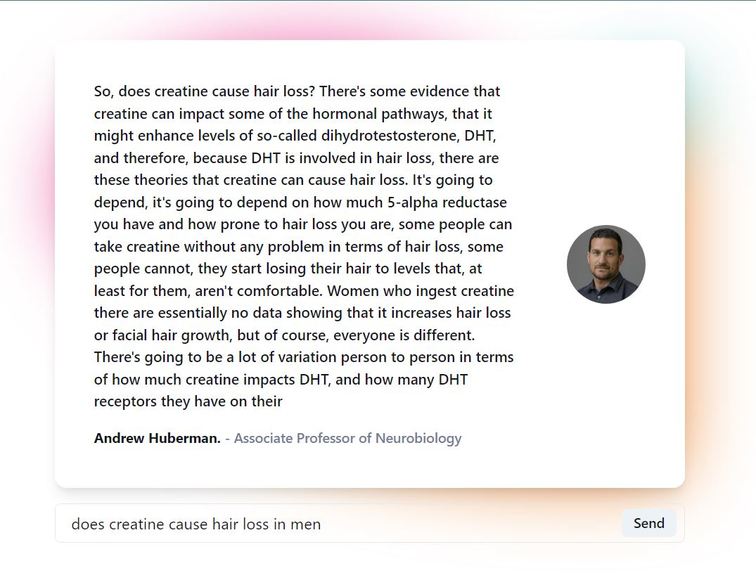
-
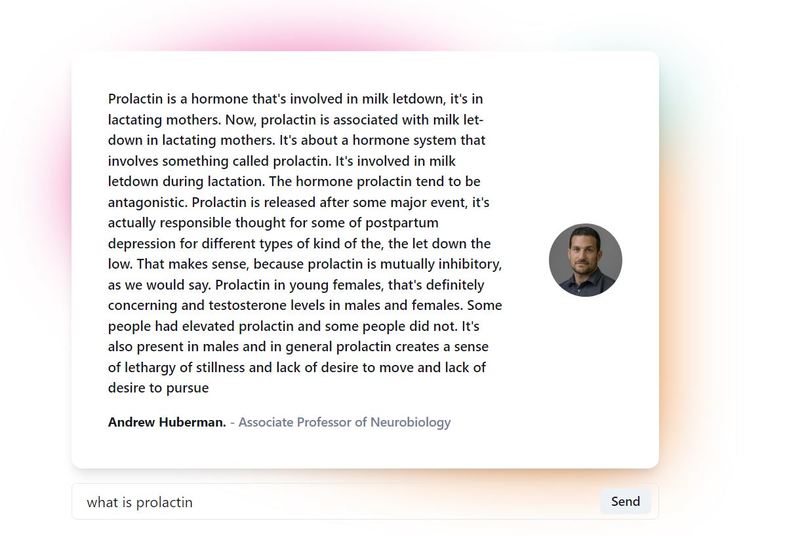

Inspiration
The phrase, "hey have you listened to this podcast", can be seen as the main source of inspiration for this project.
Andrew Huberman is a neuroscientist and tenured professor at Standford school of medicine. As a part of his desire to bring zero cost to consumer information about health and health-related subjects, he hosts the Huberman-lab podcast. The podcast is posted weekly, covering numerous topics all provided in an easy-to-understand format. With this, listeners are able to implement the systems he recommends with results that are backed by the academic literature.
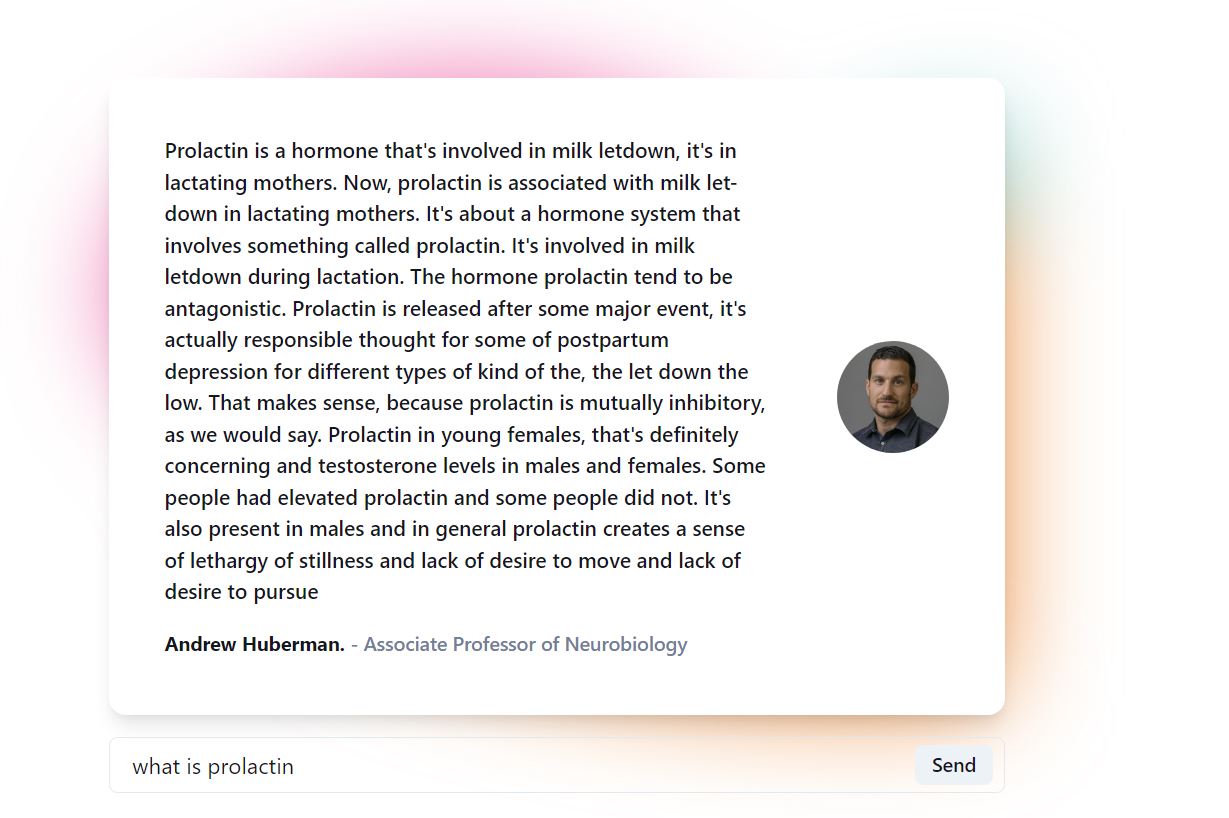
What it does
With over 90 episodes, wouldn't it be great to search through the episodes to have a deeper understanding of a topic? What if you are interested in what was said about a particular subject matter but don't have time to watch the whole episode? Better yet, what if you could ask the Dr. himself a question about something he has talked about (which people now can do, at a premium price of $100 a year).
With this in mind, I have created an immersive experience to allow individuals to ask him health-related questions through a model generated based on his podcasts.
What problem does it solve
It is tough to find trustworthy advice on virtually any topic due to the rise of SEO and people fueled by greed. With this pseudo-chat bot, you can guarantee that the advice provided is peer reviewed or at the very least grounded in truth.
Many people append "Reddit" to their google searches to make sure the results they receive are trustworthy. With this model, the advice it provides is short, and to the point while removing the need to scour the internet for the right answer.
How I built it
Frontend: NextJS (React) + ChakraUI + Three.js + ReadyPlayer (model and texture generation) + Adobe Mixamo (model animation) Backend: Flask (Python) Data sci: Pinecone (vector storage) + Cohere (word embedding, text generation, text summarization), nltk (English language tokenizer)
40 podcast episodes (almost ~35,000 sentences) were processed via the backend and stored on Pinecone to be called via Cohere. Once the backend receives a query request (question/prompt provided by the user):
- A text prompt is generated based on Cohere's models (breaking down what the user meant)
- The prompt is fed through their embedding, to embed the newly generated prompt (create something we can search the Pinecone db with)
- Pinecone is queried, returning the top 10 blocks (sentences). Any block with an accuracy of over 0.45 is fed into the text summarization algorithm
- Text is compiled, and summarized. The final summarized result is returned to the user.
Challenges we ran into
tl;dr
- running the proper glb/gltf models while maintaining textures when porting over from fbx (three.js fun)
- rendering, and animating models properly (more three.js fun)
- creating a chat interface that I actually like lol
- communicating with Cohere's API via the provided client and running large batch jobs with Pinecone (time out, performance issues on my laptop)
- tweaking the parameters on the backend to receive a decent result
Accomplishments that we're proud of
Firsts:
- creating a word-embedded model, or any AI model for that matter
- using Pinecone
- understanding how three.js works
- solo hack!
- making friends :.)
What we learned
See above <3
What's next for Ask Huberman
- Allow users to generate text of X length or to click a button to learn more
- Linking the text generated to the actual podcast episodes to watch the whole thing
- Create a share feature to share useful/funny answers
- Tweak the model output parameters
- Embed amazon affiliate links based on what the answer is
What would you do differently
- cut losses sooner with three.js
- go talk to the Cohere guys a little sooner (they are awesome)
- manage git better?
Huge thank you to the HW team - had a lot of fun.

Log in or sign up for Devpost to join the conversation.